本文以使用RAPIDS加速图像搜索任务为例,介绍如何在预装镜像的GPU实例上使用RAPIDS加速库。
使用本教程进行操作前,请确保您已经注册了阿里云账号。如还未注册,请先完成账号注册。
RAPIDS,全称Real-time Acceleration Platform for Integrated Data Science,是NVIDIA针对数据科学和机器学习推出的GPU加速库。更多RAPIDS信息请参见官方网站。
基于图像识别和搜索,图像搜索任务可以实现以图搜图,在不同行业应用和业务场景中帮助您搜索相同或相似的图片。
图像搜索任务背后的两项主要技术是特征提取及向量化、向量索引和检索。本文案例中,使用开源框架TensorFlow和Keras配置生产环境,然后使用ResNet50卷积神经网络完成图像的特征提取及向量化,最后使用RAPIDS cuML库的KNN算法实现BF方式的向量索引和检索。
说明: BF(Brute Force)检索方法是一种百分百准确的方法,对距离衡量算法不敏感,适用于所有的距离算法。
本文案例在阿里云gn6v(NVIDIA Tesla V100)实例上执行。执行案例后,对比了GPU加速的RAPIDS cuml KNN与CPU实现的scikit-learn KNN的性能,可以看到GPU加速的KNN向量检索速度为CPU的近600倍。
本文案例为单机单卡的版本,即一台GPU实例搭载一块GPU卡。
操作步骤
执行以下操作完成一次图像搜索任务:
步骤一:创建GPU实例
具体步骤请参见使用向导创建实例。
- 实例:RAPIDS仅适用于特定的GPU型号(采用NVIDIA Pascal及以上架构),因此您需要选择GPU型号符合要求的实例规格,目前有gn6i、gn6v、gn5和gn5i。本文案例中,选用了ecs.gn6v-c8g1.2xlarge实例规格。
-
镜像:在镜像市场中使用关键字RAPIDS,搜索并使用预装了RAPIDS加速库的镜像。
 - 安全组:选择的安全组需要开放TCP 8888端口,用于支持访问JupyterLab服务。
步骤二:启动和登录JupyterLab
-
连接GPU实例,运行以下命令启动JupyterLab服务。
说明: 连接GPU实例的步骤请参见连接方式导航。
# Go to the notebooks directory. cd /rapids # Run the following command to start JupyterLab and set the logon password: jupyter-lab --allow-root --ip=0.0.0.0 --no-browser --NotebookApp.token='your logon password' # Exit jupyterlab: press Ctrl+C twice. - 在您的本地机器上打开浏览器。输入
http://(IP address of your GPU instance):8888远程访问JupyterLab。说明: 推荐使用Chrome浏览器。
- 输入启动命令中设置的密码,然后单击Log in。

步骤三:执行图像搜索案例
- 进入案例所在目录rapids_notebooks_v0.7/cuml。
- 双击cuml_knn.ipynb文件。
-
单击
 。
。**说明:** 单击一次执行一个cell,请单击至案例执行结束,详细说明请参见[案例执行过程](#section_vqt_ih6_0t7)。 
案例执行过程
图像搜索案例的执行过程分为三个步骤:处理数据集、提取图片特征和搜索相似图片。本文案例结果中对比了GPU加速的RAPIDS cuml KNN与CPU实现的scikit-learn KNN的性能。
-
处理数据集。
-
下载和解压数据集。 本文案例中使用了STL-10数据集,该数据集中包含10万张未打标的图片,图片的尺寸均为:96 x 96 x 3。您可以使用其他数据集,为便于提取图片特征,请确保数据集中图片的尺寸相同。
本文案例提供了`download_and_extract(data_dir)`方法供您下载和解压STL-10数据集。RAPIDS镜像中已经将数据集下载到./data目录,您可以执行`download_and_extract()`方法直接解压数据集。 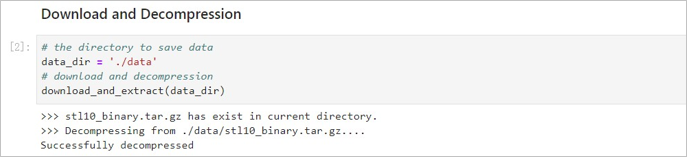 -
读取图片。 从数据集解压出的数据为二进制格式,执行
read_all_images(path_to_data)方法加载数据并转换为NHWC(batch, height, width, channels)格式,以便用Tensorflow提取图片特征。 -
展示图片。 执行
show_image(image)方法随机展示一张数据集中的图片。 -
分割数据集。 按照9:1的比例把数据集分为两部分,分别用于创建图片索引库和搜索图片。

-
-
提取图片特征。 使用开源框架Tensorflow和Keras提取图片特征,其中模型为基于ImageNet数据集的ResNet50(notop)预训练模型。
-
设定Tensorflow参数。 Tensorflow默认使用所有GPU显存,我们需要留出部分GPU显存供cuML使用。您可以选择一种方法设置GPU显存参数:
-
方法1:依据运行需求进行显存分配。
config.gpu_options.allow_growth = True
-
-
- 方法2:设定可以使用的GPU显存比例。本案例中使用方法2,并且GPU显存比例默认设置为0.3,即Tensorflow可以使用整块GPU显存的30%,您可以依据应用场景修改比例。
config.gpu_options.per_process_gpu_memory_fraction = 0.3 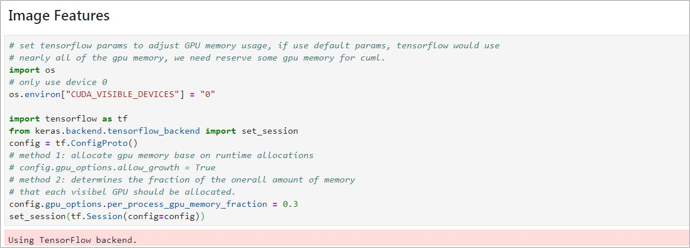
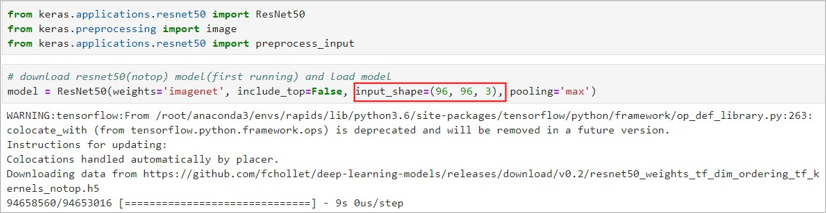
2. 下载ResNet50(notop)预训练模型。 连接公网下载模型(大小约91M),下载完成后默认保存到/root/.keras/models/目录。
|参数名称|说明|
|----|--|
|weights|取值范围: - None:随机初始化权重值。
- imagenet:权重值的初始值设置为通过ImageNet预训练过的模型的权重值。本案例中设置为imagenet。
|
|include\_top|取值范围: - True:包含整个ResNet50网络结构的最后一个全链接层。
- False:不包含整个ResNet50网络结构的最后一个全链接层。本案例中,使用神经网络模型ResNet50的主要目的是提取图片特征而非分类图片,因此设置为False。
|
|input\_shape|可选参数,用于设置图片的输入shape,仅在include\_top设置为False时生效。您必须为图片设置3个inputs channels,且宽和高不应低于32。此处设为\(96, 96, 3\)。|
|pooling|在include\_top设置为False时,您需要设置池化层模式,取值范围: - None:输出为4D tensor。
- avg:平均池化,输出为2D tensor。
- max:最大池化,输出为2D tensor。本案例中设置为max。|
您可以执行`model.summary()`方法查看模型的网络结构。

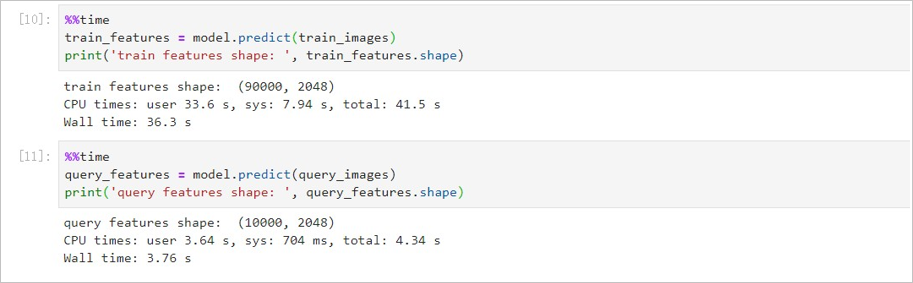
3. 提取图片特征。 对分割得到的两个图片数据集执行`model.predict()`方法提取图片特征。
-
搜索相似图片。
- 使用cuml KNN搜索相似图片。 通过
k=3设置K值为3,即查找最相似的3张图片,您可以依据使用场景自定义K值。其中,
knn_cuml.fit()方法为创建索引阶段,knn_cuml.kneighbors()为搜索近邻阶段。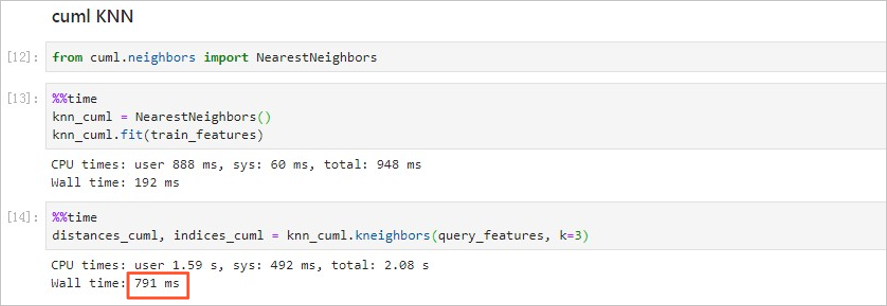
KNN向量检索耗时791 ms。
- 使用scikit-learn KNN搜索相似图片。 通过
n_neighbors=3设置K值为3,通过n_jobs=-1设置使用所有CPU进行近邻搜索。说明: ecs.gn6v-c8g1.2xlarge的配置为8 vCPU。

KNN向量检索耗时7分34秒。
-
对比cuml KNN和scikit-learn KNN的搜索结果。 对比两种方式的KNN向量检索速度,使用GPU加速的cuml KNN耗时791 ms,使用CPU的scikit-learn KNN耗时7min 34s。前者为后者的近600倍。
验证两种方式的输出结果是否相同,输出结果为两个数组:
- distance:最小的K个距离值。本案例中搜索了10000张图片,K值为3,因此
distance.shape=(10000,3)。 - indices:对应的图片索引。
indices.shape=(10000, 3)。
由于本案例所用数据集中存在重复图片,容易出现图片相同但索引不同的情况,因此使用distances,不使用indices对比结果。考虑到计算误差,如果两种方法得出的10000张图片中的3个最小距离值误差都小于1,则认为结果相同。

- distance:最小的K个距离值。本案例中搜索了10000张图片,K值为3,因此
- 使用cuml KNN搜索相似图片。 通过
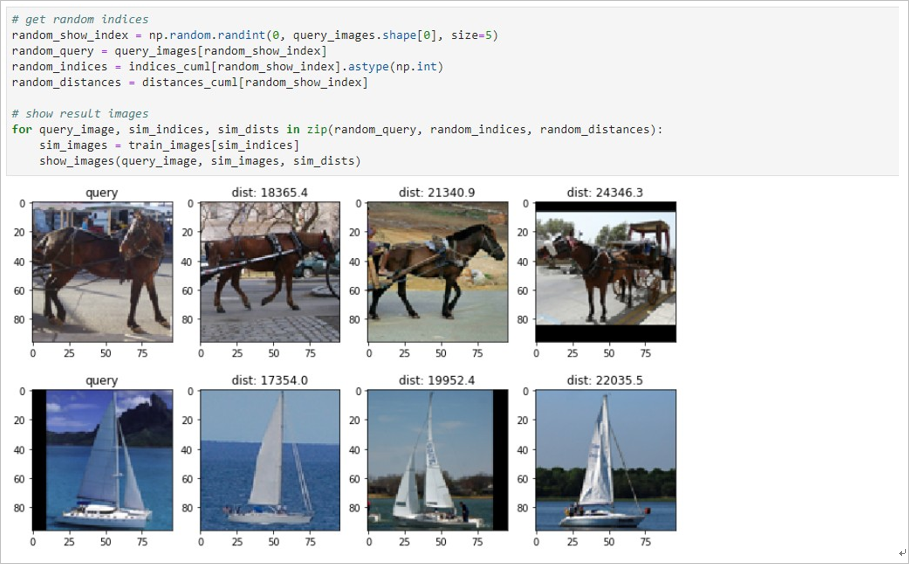
图片搜索结果
本案例从1万张搜索图片中随机选择5张图片并搜索相似图片,最终展示出5行4列图片。
第一列为搜索图片,第二列至第四列为图片索引库中的相似图片,且相似性依次递减。每张相似图片的标题为计算的距离,数值越大相似性越低。