第三章 浅谈GPU虚拟化技术(三)GPU SRIOV及vGPU调度
GPU SRIOV原理
谈起GPU SRIOV那么这个世界上就只有两款产品:S7150和MI25。都出自AMD,当然AMD的产品规划应该是早已安排到几年以后了,未来将看到更多的GPU SRIOV产品的升级换代。S7150针对的是图形渲染的客户群体,而MI25则针对机器学习,AI的用户群体。本文以围绕S7150为主。因为S7150的SRIOV实例在各大公有云市场上都有售卖,而MI25目前看来尚未普及(受限于AMD ROCm生态环境的完备性)。
-
两个术语:SRIOV的PF,VF
(专业人士请自动忽略这部分介绍
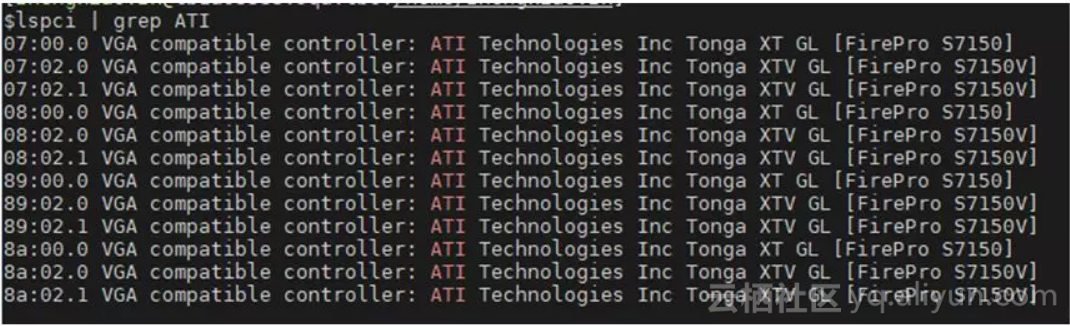
PF:宿主机上的主设备,宿主机上的GPU驱动安装在PF上。PF的驱动是管理者。它就是一个完备的设备驱动,与一般的GPU驱动的区别在于它管理了所有VF设备的生命和调度周期。比如下图的07:00.0便是PF设备
VF:也是一个PCI设备,如下图中的07:02.0和07:02.1。QEMU在启动过程中通过VFIO模块把VF 作为PCI直通设备交由虚拟机,而虚拟机上的操作系统会安装相应的驱动到这个直通的VF PCI 设备上(07:02.0)。VF设备占用了部分GPU资源。比如下图中一个PF上面划分出了两个VF,那么很有可能跑在VF上面的虚拟机GPU图形渲染性能宏观上是PF的1/2。
-
GPU SRIOV的本质
SRIOV的本质是把一个PCI卡资源(PF)拆分成多个小份(VF),这些VF依然是符合PCI规范的endpoint设备。由于VF都带有自己的Bus/Slot/Function号,IOMMU/VTD在收到这些VF的DMA请求的过程中可以顺利查找IOMMU2nd Translation Table从而实现GPA到HPA的地址转换。这一点与GVT-g和Nvidia的GRID vGPU有本质上的区别。GVT-g与Nvidia GRID vGPU并不依赖IOMMU。其分片虚拟化的方案是在宿主机端实现地址转换和安全检查。应该说安全性上SRIOV方法要优于GVT-g和GRID vGPU,因为SRIOV多了一层IOMMU的地址访问保护。SRIOV代价就是性能上大概有5%左右的损失(当然mdev分片虚拟化的MMIO trap的代价更大)。由于SRIOV的优越性和其安全性,不排除后续其他GPU厂商也会推出GPU SRIOV的方案。
-
关于SRIOV 更多的思考
SRIOV也有其不利的地方比如在Scalable的方面没有优势。尤其是GPU SRIOV,我们看到的最多可以开启到16个VM。设想如果有客户想要几百个VM,并都想要带有GPU图形处理能力(但是每个VM对图形渲染的要求都很低),那么SRIOV的方案就不适用了。如果有一种新的方案可以让一个GPU的资源在更小的维度上细分那就完美了。事实上业界已经有这方面的考虑并付诸实践了。
GPU SRIOV内部功能模块
(吃瓜群众可以跳过)
由于没有GPU SRIOV HW的spec与Data Sheet,我们仅能按照一般的常用的方式来猜测GPU SRIOV内部功能模块(纯属虚构,如有雷同概不负责)。
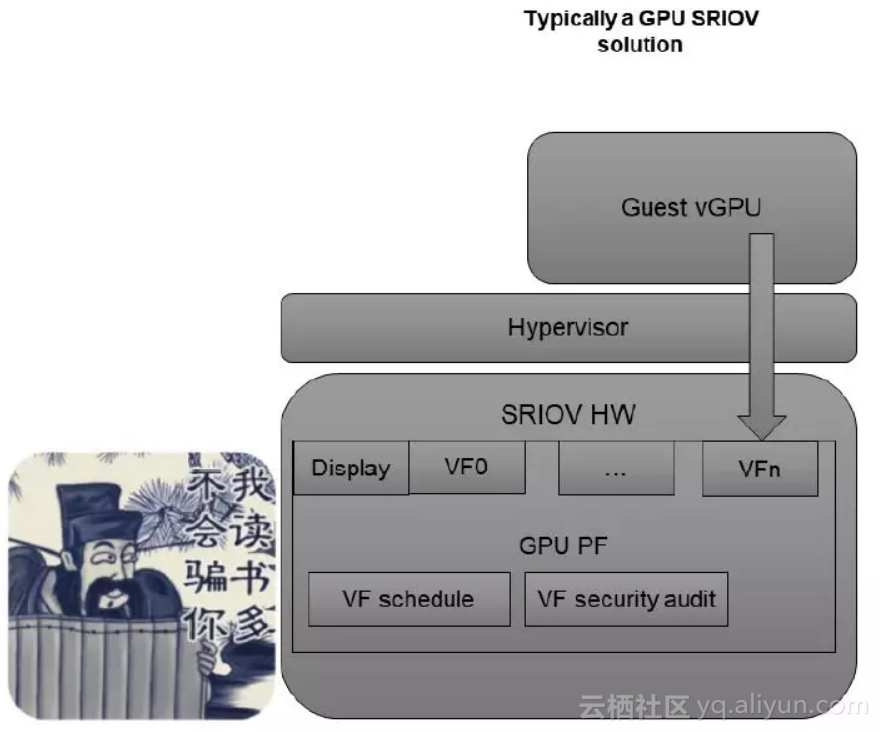
GPU的资源管理涉及到vGPU基本上三块内容是一定会有的:Display,安全检查,资源调度。
-
Display管理
GPU PF需要管理分配给某个VF的FrameBuffer大小,以及管理Display相关的虚拟化。Display的虚拟化一般分为Local Display和Remote Display。比如XenClient就是用的Display Local Virtualization,属于本地虚拟化过程。此过程相当于把显示器硬件单元完全交由当前虚拟机控制。在云计算行业,Display更多的是采用Remote Display的方式。我们后续会讲到行业中Remote Display的问题所在。
-
VF 安全检查
GPU PF或者GPU SRIOV模块需要承担一部分的VF的地址审核(Address Audit)和安全检查,GPU SRIOV的硬件逻辑会保证暴露出的VF Register List并确保不包含特权Register信息,比如针对GPU微处理器和FW的Registers操作,针对电源管理部分的Registers也不会导出到VF中。而VM对所有VF的MMIO读写最终会映射到PF的MMIO地址空间上,并在PF的类似微处理器等地方实现VF设备的部分MMIO模拟。
另外一部分的安全检查则是PF需要确保不同VF直接对GPU FrameBuffer的访问隔离。这部分很有可能需要PF针对不同的VF建立GPU的Pagetable,或者Screen所有的VF提交的GPU BatchBuffer。
-
VF调度
AMD GPU SRIOV从硬件的角度看就是一个对GPU资源的分时复用的过程。因此其运行方式也是与GPU分片虚拟化类似。SRIOV的调度信息后续重点介绍。
GPU SRIOV的调度系统
-
分时复用
VF的调度是GPU虚拟化中的重点,涉及到如何服务VM,和如何确保GPU资源的公平分片。
GPU SRIOV也是一个分时复用的策略。GPU分时复用与CPU在进程间的分时复用是一样的概念。一个简单的调度就是把一个GPU的时间按照特定时间段分片,每个VM拿到特定的时间片。在这些时间片段中,这个VM享用GPU的硬件的全部资源。目前所有的GPU虚拟化方案都是采用了分时复用的方法。但不同的GPU虚拟化方案在时间片的切片中会采用不同的方法。有些方案会在一个GPU Context的当前BatchBuffer/CMDBuffer 执行结束之后启动调度,并把GPU交由下一个时间片的所有者。而有些方案则会严格要求在特定时间片结束的时候切换,强行打断当前GPU的执行,并交予下一个时间片的所有者。这种方式确保GPU资源被平均分摊到不同VM。AMD的GPU SRIOV采用的后一种方式。后续我们会看到如何在一个客户机VM内部去窥探这些调度细节
-
调度开销
然而GPU的调度不同于CPU的地方是GPU上下文的切换会天然的慢很多。一个CPU Core的进程切换在硬件的配合下或许在几个ns之内就完成了。而GPU则高达几百ns(比如0.2ms-0.5ms)。这带来的问题就是GPU调度不能类似CPU一样可以频繁的操作。举一个例子:GPU按照1ms的时间片做调度,那么其中每次调度0.5ms的时间花在了上下文的切换上,只有1ms的时间真正用于服务。GPU资源被极大浪费。客户理论上也只能拿到66%的GPU资源。
-
S7150的调度细节
接下来我们来看一下作为首款GPU SRIOV方案的S7150是如何调度的。由于S7150是中断驱动的结构,所以通过查看虚拟机内部GPU中断的分布情况就可大致判断出GPU SRIOV对这个虚拟机的调度策略。
对于Windows的客户机,我们可以在内部安装Windows Performance kit,并检测"GPU activity"的活动。
对于Linux的客户机,则更简单,直接查看GPU驱动的trace event。当然我们要感谢AMD在提供给Linux内核的SRIOV VF驱动上没有去掉trace event。这让我们有机会可以在VM内部查看到SRIOV的调度细节。(不知道这算不算一种偷窥?)
我们在阿里云上随便开启一台GA1的1/2实例。
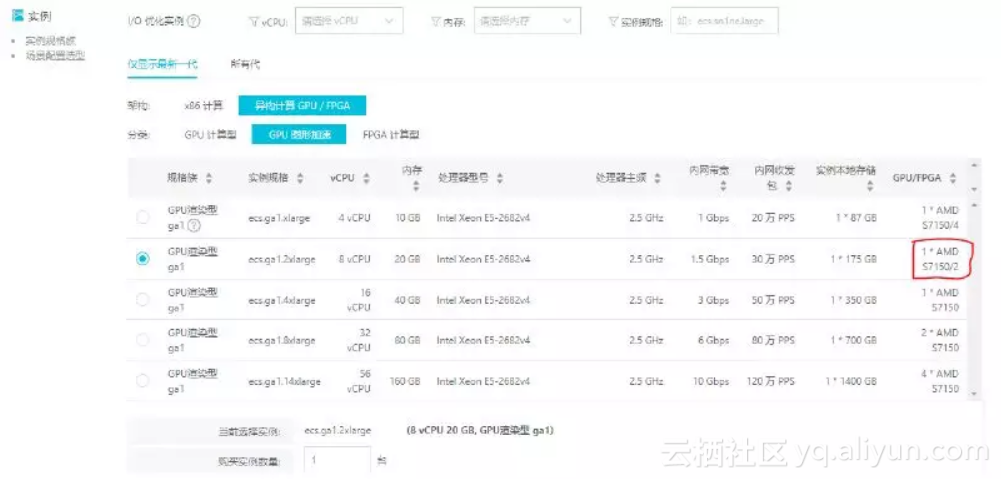
并选择Ubuntu(预装AMD驱动)作为系统镜像;
在Console下查看所有的GPU相关的trace如下表:
很不错,我们发现有两个GPU驱动分发workload的event:amd_sched_job与amd_sched_process_job。
在VNC中开启一个GPU Workload以后(比如Glxgears或者Glmark,当然我们需要先开启x11vnc),我们通过下面Command来采集GPU数据。
查看我们抓取这两个event的事件并记录下来几个有趣的瞬间:

所有的log在一段时间内是连续的,然后断开一段时间,然后又连续的workload提交。
截图上的小红框是我们需要关注的间隔时间。摘取如下表:
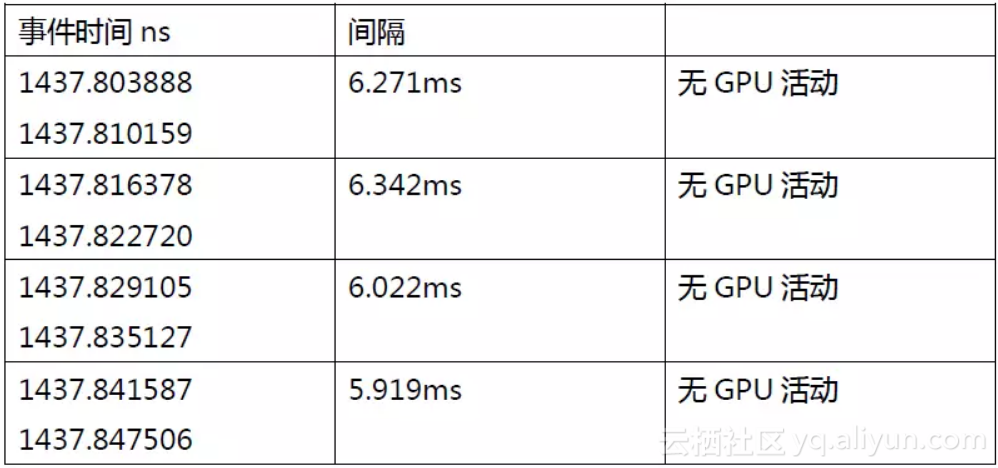
很明显在上述时间窗口期内当前VM的GPU被暂停了,并被切换至服务其他VM。因此当前VM的GPU workload会积压在驱动层次。
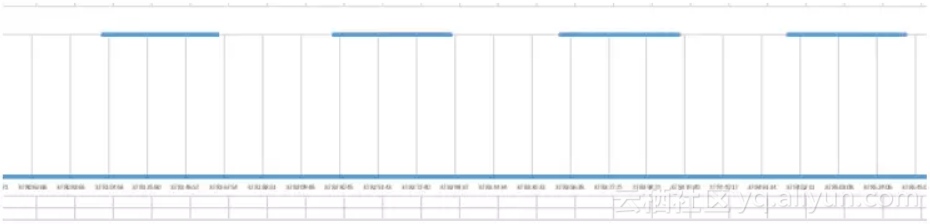
我们把所有的event在图表上打点后就可以发现,对于一个1/2GPU实例的VM来说,它占用的GPU资源是基本上以6ms为时间片单位做切换的。
作图如下:
-
估算vGPU的调度效率
我们假设每次vGPU的调度需要平均用到0.2ms,而调度的时间片段是6ms,而从上图的结果来看,AMD GPU SRIOV是采用严格时间片调度策略。6ms一旦时间用完,则马上切换至下一个VM(哪怕当前只有一个VM,也会被切走)。所以1/2实例的S7150的调度效率可以达到:96.7%如果有两个这样的VM同时满负荷运行,加起来的图形渲染能力可达到GPU直通虚拟化的96.7%以上。
实测结果如下:
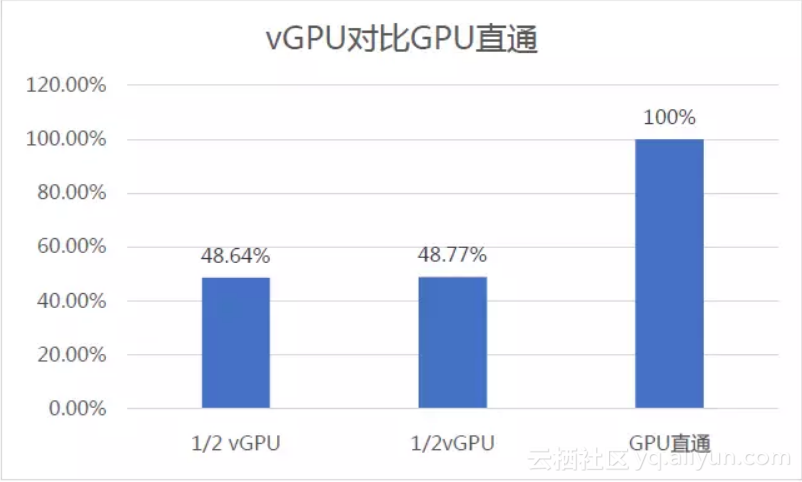
1/2vGPU+ 1/2vGPU = 97.4% (vs GPU直通性能)
每一个vGPU可以达到直通GPU性能的48.x%,整体性能可以达到97.4%,与我们的预估非常接近。
更多的关于GPU虚拟化调度的思考
不得不说AMD S7150在vGPU调度上是非常成功的。AMD的GPU硬件设计保证了可以在任何当前GPU Batch Buffer的执行过程中可以被安全的抢占(GPU Workload Preemption),并切换上下文到一个新的Workload。有了这样卓越的硬件设计,才使得PF驱动在软件层面的调度算法可以如此从容有序。6ms强制调度保证了多VM在共享GPU资源的情况下不会饥饿不会过度占用。调度开销极小(2-3%)。而且这样的设计在VM数量不多的情况下可以进一步调整时间片的大小比如12ms,则GPU的利用率会更进一步提高。那么为什么不能采用100ms调度呢?因为Windows内核对"GPU activity"的活动有监视。任何GPU CMD在2秒内没有响应,Windows就会发起Timeout Detected Recover(TDR),重置GPU驱动。设想如果你有16个VM,调度时间片为100ms的情况下,平均一个VM轮转到GPU资源的最小间隔就有1.6s。加上其他由于PF驱动被Linux内核调度的延迟,很有可能触发Windows Guest内部的TDR。
原文发布时间为:2018-04-24
本文作者:郑晓