问题一:Flink 1.17.1 Join维表时,对维表字段where过滤或维表中维表字段 这种会有问题吗?
Flink 1.17.1 Join维表时,对维表字段where过滤或维表中Join ... on ... and 维表字段
这种会有问题吗?
参考答案:
在Flink 1.17.1中,对维表字段进行WHERE过滤或者在JOIN语句中使用维表字段进行条件筛选通常是支持的,不会存在根本性的问题。
以下是一些示例:
- 使用WHERE过滤:
SELECT ... FROM mainTable JOIN dimensionTable ON mainTable.joinKey = dimensionTable.joinKey WHERE dimensionTable.filterColumn = 'someValue'
在这个例子中,Flink会在JOIN操作之后对维表(dimensionTable)的数据进行过滤,只保留filterColumn等于'someValue'的记录。
- 在JOIN语句中使用维表字段:
SELECT ... FROM mainTable JOIN dimensionTable ON mainTable.joinKey = dimensionTable.joinKey AND dimensionTable.filterColumn = 'someValue'
在这个例子中,Flink会在JOIN操作之前对维表的数据进行预过滤,只参与JOIN操作的维表记录是那些其filterColumn等于'someValue'的记录。
需要注意的是,这两种方式可能会对性能产生影响,特别是在维表很大的情况下。WHERE过滤和JOIN条件都会减少参与JOIN操作的维表记录数量,从而降低JOIN操作的计算复杂性和内存使用。但是,过于复杂的过滤条件可能会影响查询优化和执行效率。
此外,确保你的JOIN键和过滤条件上的数据类型匹配,并且这些字段已经建立了适当的索引(如果适用),以提高查询性能。在实际使用中,建议根据你的具体业务需求和数据特征来选择合适的JOIN和过滤策略,并进行性能测试和调优。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/583804
问题二:flink 1.17.1有bug公布的网站吗?
flink 1.17.1有bug公布的网站吗?
参考答案:
开源可以看github和jira。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/583803
问题三:在Flink为什么这个地方的水位线会跟现实时间差了8h?
在Flink为什么这个地方的水位线会跟现实时间差了8h?我设置的乱序荣热度是5分钟,跟现在的时间差距应该是5分钟,但是为什么差了8h5min。 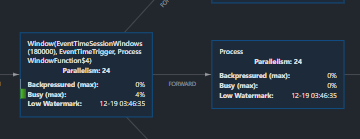
参考答案:
用户在用某个时间戳作为 watermark 的时候,那个时间戳可能是 w/ timezone ,也可能 w/o timezone (他俩之间有8h差),在display 的时候,没有办法底下用的是哪种时间戳,所以总有一方会看到 8h 差。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/583802
问题四:Flink这个问题怎么解决 ?
Flink这个问题怎么解决? 
参考答案:
重启了一下试试。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/583798
问题五:Flink怎么诊断问题出现在哪里呢?或者有没有降低延迟的办法呢?
用DTS从RDS MySQL数据库中同步数据到云Kafka中,增量同步数据延迟时间超过1秒,,连链路规格已经large最高的了,Flink怎么诊断问题出现在哪里呢?或者有没有降低延迟的办法呢? 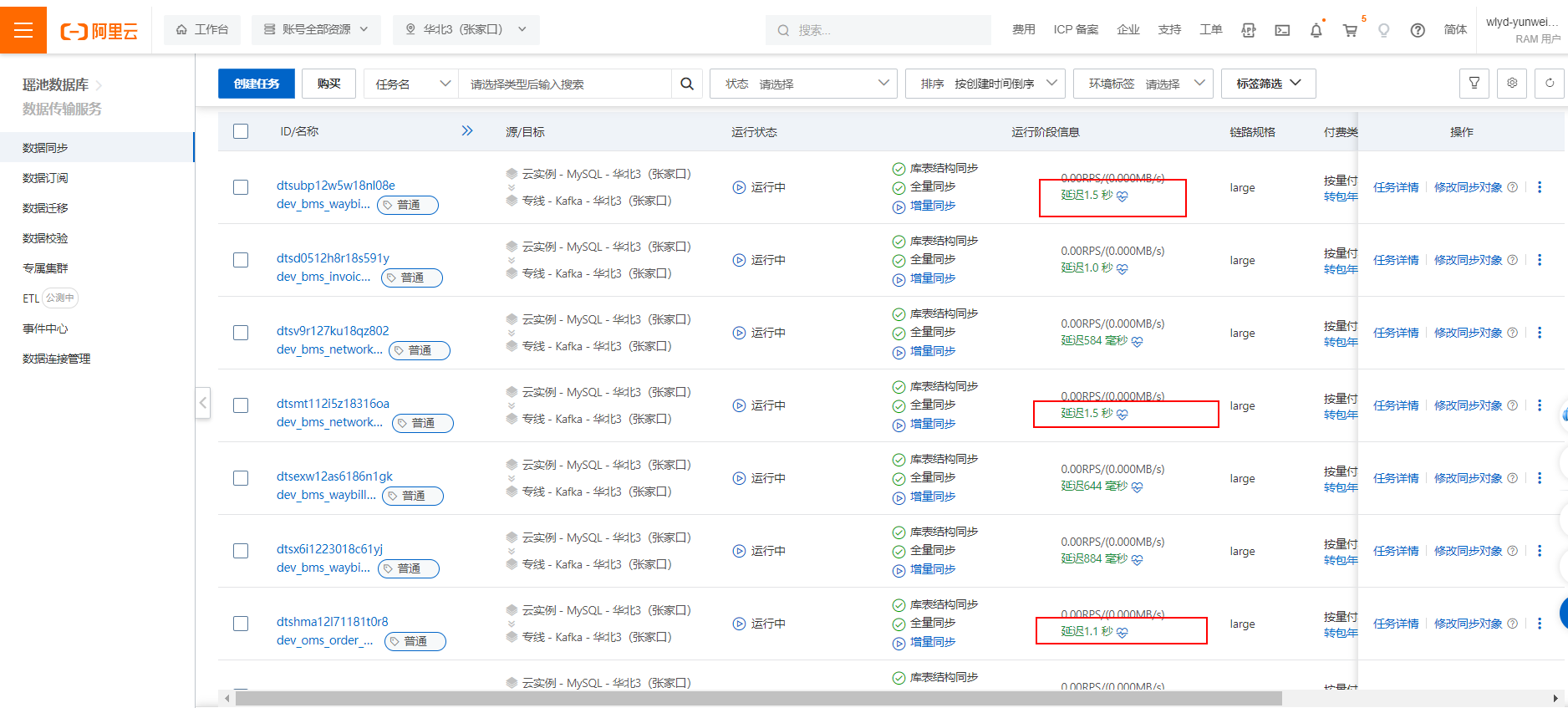
参考答案:
可以逐一排查这些原因:
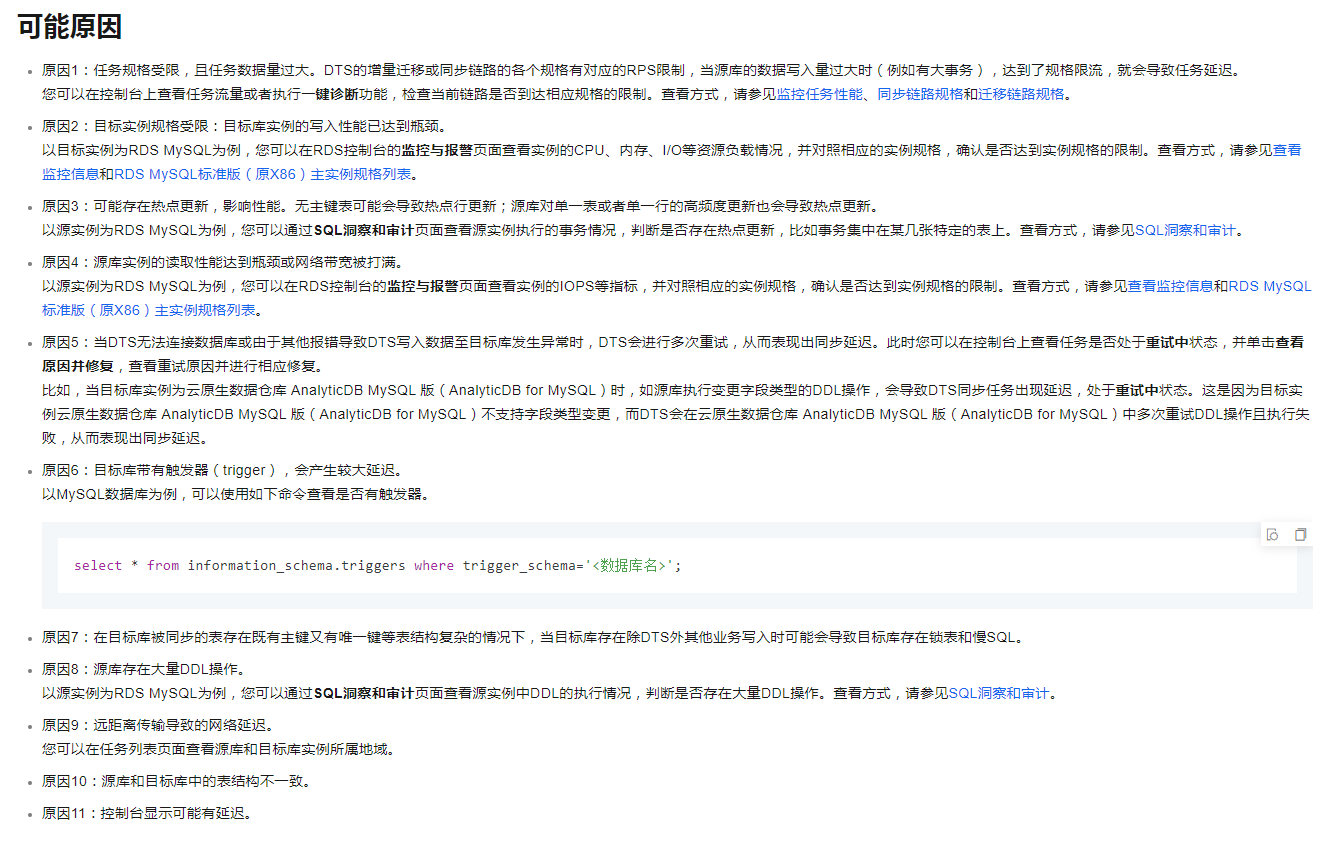
解决方案如下:

——参考来源于阿里云官方文档。
关于本问题的更多回答可点击进行查看:

