1. 可观测变成系统不可或缺的能力
IT系统经过多年的快速发展,无论是规模、架构、部署方式等方面都经历过多次优化。这些优化带来了很多好处,如提高了开发和部署效率。然而,优化也带来了一些问题,系统变得更加复杂,运行环境和人员变得更加动态和不确定。为了解决优化带来的问题,IT系统迫切需要系统化、体系化的观测手段。这种观测手段将会带来以下好处:
- 更早发现问题:通过实时监测和分析系统的各种指标和日志数据,我们可以在问题发生之前及时发现异常情况,从而提前采取措施避免问题的扩大化。
- 快速问题处理:通过收集系统的可观测数据,我们可以更准确地定位和诊断问题的根源,从而加快问题处理的速度,减少故障的恢复时间。
- 提升系统稳定性:通过对系统的运行情况进行持续监测和分析,我们可以发现并解决潜在问题,从而提高系统的稳定性和可靠性。
- 降低成本:通过可观测性的优化,我们可以更加高效地利用资源,减少系统维护和故障排查的成本,从而降低整体运营成本。
NewRelic去年发布了一份关于可观测技术趋势的调查报告,该报告采集了1600多份样本,覆盖了14个国家,这份报告从可观测部署情况,工具使用情况,投入等多个方面提炼了10个趋势和观点。以下是从报告中摘取的关键数字,通过调查提供的数字我们可以看出几个点:
- 可观测涉及了多种能力,每一种能力都代表一种观测系统的角度,融合可观测数据并提供一站式的可观测体验是可观测平台的核心竞争力;
- 可观测相关的能力越来越被人们所认可,但多种可观测工具以及数据不在一个地方必然造成排障困难,如何自动化和智能化去关联分析,将成为可观测平台核心需要解决的问题。

2. Trace能力在可观测中承担作用
可观测三个核心数据分别是Log、Trace、Metric。日志负责记录系统中发生的事件和活动,包括错误、警告、信息等;指标是对系统性能和行为的度量,包括各种性能指标、资源利用率等。Trace记录系统中的请求路径和执行过程,帮助我们了解请求的处理情况和性能指标。可观测数据间也可以相互产生关系,例如:Tracing和Logging数据相结合可以得到请求级别所发生的事件;Tracing与Metric数据相结合可以得到请求级别的指标等。接下来将详细介绍Trace能力在可观测中承担的作用。

2.1 记录方法耗时以及方法调用顺序,快速定位问题根因
Trace最早来源于Google的Drapper论文,它解决分布式系统中的可观测性问题。在大规模分布式系统中,由于系统的复杂性和规模,往往难以准确地追踪和监控请求的执行路径以及系统的性能指标。这导致了难以发现和解决系统中的问题,如性能瓶颈、错误和故障等。Tracing系统通过在请求路径中嵌入唯一标识符(Trace ID),跟踪请求的执行路径和在系统中的各个组件上的操作。

例如:当系统出现响应时间延长的情况时,我们可以通过追踪数据找到具体的方法调用链,确定是哪些方法消耗了大量的时间,进而进行性能优化;在一个电子商务平台中,当用户反馈某个订单处理时间过长时,我们可以通过追踪数据发现订单处理流程中的具体方法调用,从而快速定位问题所在,并加以优化。
2.2 了解服务运行情况及其依赖关系,有助于服务治理
通过聚合Trace数据,我们可以得到系统的拓扑图,从而更好地进行服务治理和系统优化。同时将各个服务的指标和日志信息整合起来,形成系统级的视图,帮助我们全面了解系统的运行情况和性能表现。通过分析整个系统的指标和日志信息,我们可以识别出系统中的瓶颈和性能瓶颈,从而制定合理的服务调度策略和容错机制。例如,通过拓扑图,我们可以发现某个服务的响应时间较长,可以考虑对其进行性能优化或升级;或者发现某些服务之间存在较高的依赖关系,可以考虑对这些服务进行拆分或重构,以降低系统的耦合度和提高可伸缩性。

2.3 关联可观测数据能力,有助于做问题根因分析
相比Log和Metric数据,Trace数据具备内容丰富、拥有上下文等特点。这使得Trace数据成为可观测数据的一种重要润滑剂,可以通过关联其他可观测数据来获得更全面的系统运行信息和问题诊断能力。例如Trace数据可以与实例信息和日志信息进行关联。
通过关联实例信息,我们可以将Trace数据与特定的服务实例或主机进行关联。这样一来,我们可以更准确地了解每个Trace是由哪个实例处理的,从而帮助我们在分布式系统中定位问题和进行故障排查。例如,通过关联实例信息,我们可以快速确定某个Trace是由哪个具体的服务实例处理的,从而定位到具体的服务节点,便于快速定位问题。

同时,通过关联日志信息,我们可以将Trace数据与特定的日志记录进行关联。这样一来,我们可以将Trace的执行过程与系统日志进行对比和分析,从而深入了解每个Trace在执行过程中的细节和异常情况。例如,通过关联日志信息,我们可以查找与特定Trace相关的日志记录,从而更加全面地了解Trace执行过程中发生的事件和异常情况,有助于问题的定位和分析。
3. 全栈可观测App - Trace能力
全栈可观测App是SLS提供的可观测平台,全栈可观App提供可观测数据(Trace,Log,Metric,Profiling)关联分析分析能力以及可视化的能力,接下来将介绍一下全栈可观测App下的Trace的能力。
3.1 服务依赖图
服务依赖关系是系统服务的鸟瞰图,它直观地展示了服务之间的依赖关系。通过观察服务依赖关系,我们可以获取系统中各个服务之间的调用关系和交互方式。这对于服务治理和系统优化具有重要意义。
通过分析服务依赖关系,我们可以识别出服务之间的耦合和依赖程度,进而制定合理的服务调度策略和容错机制。例如,如果发现某个服务的调用频率过高,可以考虑进行负载均衡或缓存优化;如果发现某个服务的响应时间较慢,可以考虑对其进行性能优化或升级。

服务依赖关系还可以帮助我们优化系统架构。通过观察服务之间的依赖关系,我们可以发现潜在的性能瓶颈和单点故障,从而进行架构调整和容错设计。例如,如果某个服务成为了系统的瓶颈,我们可以考虑对其进行水平扩展或拆分成多个微服务。通过优化服务之间的依赖关系,我们可以提升整体系统的可伸缩性、稳定性和性能。
另外,服务依赖关系还可以帮助我们进行故障隔离和故障排查。通过观察服务之间的依赖关系,我们可以快速定位故障的来源和影响范围,并采取相应的措施进行故障隔离和修复。这有助于提高系统的可用性和稳定性。
3.2 Trace Explorer
Trace详情展现了请求的整个过程,通过图形化的方式展示Trace数据,用户可以清晰地了解系统的运行情况。这种图形化展示形式可以将请求的调用流程呈现为一个时间线,每个节点表示一个调用操作,节点之间的连接表示调用关系。通过这种可视化方式,用户可以直观地了解请求在系统中的流转路径和调用顺序。
除了图形化展示,Trace详情还支持属性和信息的关联跳转到其他观测数据。这意味着用户可以根据需要深入了解特定节点或操作的性能指标、异常情况、日志信息等。例如,用户可以通过点击节点或操作,跳转到关联的性能监控页面,查看与其相关的指标数据;或者跳转到日志检索工具,查看与其相关的日志信息。这种关联跳转功能大大提高了用户的操作效率和问题定位能力。
这种图形化和关联跳转的展示方式,大大提升了用户对系统的监控和分析能力。用户可以更加直观地了解请求的调用路径和执行情况,同时通过关联跳转可以深入了解调用流程中的性能指标和其他相关信息。这使得用户能够更好地理解系统的性能和可靠性,针对问题进行优化和调整,提升系统的整体表现和用户体验。

如果一次请求涉及上千个方法,人工分析如此庞大的数据是不现实的。SLS提供了针对当前调用链的分析结果。分析结果包括调用链的基本信息,异常Span列表、重复调用方法、服务延迟方法排名等数据。
- 异常Span列表显示了调用链中出现异常的Span,可以帮助我们快速定位和排查问题。
- 重复调用方法指出了在同一请求中被多次调用的方法,这可能是因为不必要的重复逻辑或者错误的调用方式。通过查看重复调用方法,我们可以识别并修复这些问题,提升系统的性能和效率。
- 服务延迟方法排名是一个非常有用的指标,它展示了调用链中每个方法的延迟情况,并按照延迟时间进行排序。通过查看延迟方法排名,我们可以确定是哪些方法造成了整体延迟的增加,从而有针对性地进行性能优化和调整。
SLS提供的这些总体分析结果,使我们能够更加快速地定位问题。通过查看异常Span列表、重复调用方法和服务延迟方法排名等指标,我们可以快速识别和解决调用链中存在的问题,提升系统的性能和可靠性。

Trace数据的丰富度高,仅根据Trace ID是远远不能充分发挥其价值的。SLS提供自定义分析查询能力,它可以辅助用户更好地组合各种条件,以便获取目标Trace数据。而且,每个条件组合都会自动提示可选的值,使用户能够更轻松地完成查询操作。例如:用户可以根据自己的需求进行灵活的数据筛选和过滤。用户可以根据时间范围、请求路径、服务名、主机名等条件进行组合查询,从而获取到特定范围内的Trace数据。此外,用户还可以根据自定义的属性和标签进行查询,以便更精确地找到所需的Trace数据。

3.3 业务指标统计查询
通过在Span中添加业务字段,并利用SLS提供的搜索能力,我们可以进行更深入的业务分析。例如,在业务请求中记录了用户ID,通过这个字段,我们可以根据用户ID来查询该用户的整个操作记录。这样可以帮助我们了解用户在系统中的行为和使用情况;又比如假使Trace中记录了订单ID,就可以通过订单ID来查询整个订单的扭转轨迹。

除了通过查询,SLS还提供针对Span中的属性进行统计分析。这种分析主要利用统计学相关的技术,通过按照不同的维度组合进行分析,包括上述提到的Resource和Attribute信息。通过分析不同维度的组合,我们可以发现异常的维度,并深入了解其原因和影响。
例如,我们可以根据不同的Resource属性,比如服务名、主机名等,对调用链路数据分组统计。通过统计每个组的调用次数、平均延迟等指标,我们可以发现是否有某个服务或主机出现了异常情况。这种统计分析可以帮助我们定位和排查问题,找出造成系统异常的具体维度。
另外,我们也可以根据不同的Attribute信息,比如请求类型、错误码等,对调用链路数据进行分组统计。通过统计每个组的占比、频率等指标,我们可以发现异常频繁发生的请求类型或错误码。这有助于我们深入了解系统中的异常情况,并采取相应的优化措施。

3.4 维度分析能力
每条Trace数据代表系统的一次请求,Trace数据会记录运行的环境信息、关键方法的入参等。系统每时每刻都有可能发生异常或慢服务,开发者需要通过庞大且多维的Trace数据挖掘异常数据下的模式。智能分析是日志服务Trace提供的定位异常的工具,通过分析所有异常Span的维度找到异常行为下的模式,帮助您快速定位异常。智能分析过程如下所示。
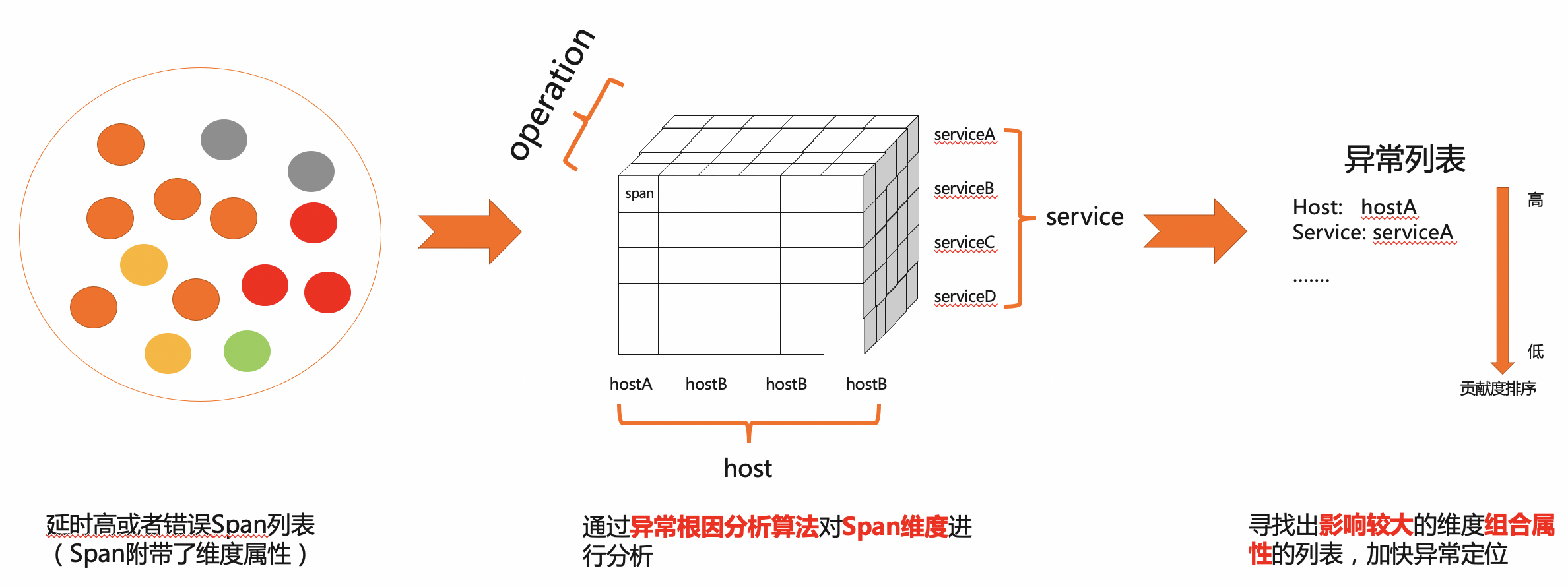
当您在日志服务Trace应用中,打开Trace分析,智能分析将从平均延时和错误率这两个维度分析所查询的Span数据,获得隐藏在数据下的模式。
- 平均延时维度将分析所有超过P95延时的Span数据,获得造成慢请求的维度组合。
- 错误率维度将分析所有错误的Span数据,获得造成错误的维度组合。

智能分析默认从service和name这两个维度进行分析。您也可以选择内置的分析维度进行快速分析或者自定义分析维度,其中有用于分析数据库相关的维度,用于分析系统中HTTP调用相关的维度,用于分析主机相关的维度等等;自定义分析维度您可以选择service、operation、host等字段,自定义分析维度。分析结果主要分为以下几个关键点:维度组合、贡献度、结果值和操作,如下图所示。

维度分析能力结果如下图所示
- 维度组合,造成异常的维度组合。
- 结果值,该维度组合下的结果值。两个维度的结果值不一样。
- 延时分析下的结果值表示该维度组合下Span的P95值。
- 错误率分析下的结果值表示该维度组合下的错误率。
- 贡献度,范围为[0-1]。贡献度越高,表示该组合越是异常根因。
- 查询操作,您可以点击filter By或者Group by,快速查询到对应的Span数据。
3.5 自定义Dashboard能力
每个人对于系统观测的角度和关注点可能有所不同。不同的角色和技术栈会导致需求和排障路径的差异。通过SLS的自定义Dashboard功能,用户可以根据个人需求和关注点自由创建和设计仪表盘。例如,运维同学可能更关注系统的水位、使用率等指标。他们可以在自定义Dashboard中添加与其相关的图表和监控指标,以便实时监测系统的状态。而研发同学则可能更关注错误率、错误日志等问题。他们可以在自定义Dashboard中添加相关图表和日志监控,以便及时发现和解决问题。借助自定义Dashboard,用户能够根据自身角色、技术栈和排障需求,构建适合自己的监控和排障界面。这将提高问题排查的效率,减少时间和人力成本的浪费。

3.6 关联其他可观测数据,联合分析
关联分析是可观测场景中的一个重要分析场景,它可以帮助我们更准确地了解系统的运行情况。通过打通不同的可观测数据,特别是通过Trace关联对应的运行环境的指标,我们可以深入了解系统性能问题的根源,从而采取相应的优化措施。
通过关联分析,我们可以将Trace数据和运行环境的指标进行关联。例如,我们可以将某个Trace的关联日志、监控数据和配置信息等与该Trace的执行时间和服务信息进行关联。这样一来,我们可以更加全面地分析Trace的执行过程,在出现问题时,能够追溯到具体的运行环境指标,从而确定是否是由于某些指标导致了服务出现问题。
通过关联分析,我们还可以发现系统运行过程中的潜在问题。例如,通过关联Trace和日志数据,我们可以发现在某个特定的Trace执行时,是否存在异常的日志记录;通过关联Trace和监控数据,我们可以发现某个Trace的执行时间超过了预期的阈值。这样可以帮助我们更精确地定位问题,并采取相应的解决措施。
关联分析还可以帮助我们进行系统优化。通过分析不同Trace之间的关联关系,我们可以发现系统中存在的瓶颈和热点问题。例如,通过关联分析发现某个高延迟的Trace与某个特定服务或资源有关,我们可以针对该服务或资源进行优化,从而提高整体系统的性能和稳定性。

3.7 自动化 & 智能化能力
当应用每天承载大量用户请求时,处理和分析如此庞大的数据量超出人能处理能力范围。自动发现异常以及异常根因定位功能就显得尤为重要。SLS利用动态阈值算法对用户的请求进行监控和分析。这种算法会根据历史数据和实时数据动态调整阈值,以便更准确地判断哪些请求是异常的。当发现异常请求后,SLS全栈可观测App会进行异常归因。它会将异常请求按照不同的维度进行归类,如主机、服务和方法。通过对异常请求进行归因,SLS全栈可观测App可以帮助用户更好地了解异常发生的背后原因,并进行进一步的分析和解决。例如SLS通过动态阈值算法从17000条请求中过滤出28条异常请求,随后对这28条异常Trace按照主机、服务和方法维度进行归因,并给出维度相应的比例,最后通过仪表盘给出的指标数据得出改时间范围内的异常Trace中由payment应用引起的问题。

4. 总结
可观测性在现代IT系统中变得越来越重要,随之而来的是数据内容的丰富性和数据量的增加。为了应对这些挑战,分析工具的要求也越来越高。全栈可观测App提供了一套完整的分析工具,从数据统计分析能力到数据关联,再到具备智能化和自动化特性的相关工具,以解决人们在可观测性方面所遇到的问题。未来,我们将持续提供更加丰富和强大的分析工具来满足用户的需求。
全栈可观测App作为一套完整的分析工具,具有以下特点和优势:
- 数据统计分析能力:全栈可观测App能够对大量的可观测数据进行统计分析,帮助用户了解系统的运行状况、性能指标和异常情况。通过定制化的仪表盘和报告,用户可以轻松获取所需的关键指标和洞察。
- 数据关联:全栈可观测App具备数据关联的能力,可以将不同来源的数据进行关联,形成更加全面和准确的分析视图。通过将日志、指标和追踪数据等进行关联,用户可以更好地理解系统的整体运行情况,进行问题的定位和优化。
- 智能化和自动化工具:全栈可观测App致力于提供智能化和自动化的相关工具,帮助用户更高效地进行数据分析和问题解决。例如,自动发现异常模式、智能告警和自动化根因分析等功能,可以帮助用户快速定位和解决问题,提高故障处理的效率。
通过以上的特点和优势,全栈可观测App能够帮助用户更好地应对可观测性挑战,提供全面的分析工具来解决问题。随着技术的进步和用户需求的演进,我们将继续不断丰富和扩展我们的分析工具,以满足用户的不断变化的需求。我们致力于提供高效、智能和全面的分析工具,让用户能够更加轻松地进行系统监控、问题诊断和性能优化,实现系统的稳定和价值的最大化。