背景说明
- Blink提交采用进程模型(包装flink info/run命令)进行作业执行计划的生成和作业的提交,这个基本是大数据计算引擎jstorm/spark/flink的共识,采用该方式的优点在于:
- 简单:
- 用户只需在自己的jar包中进行逻辑处理
- 引擎client负责以方法调用形式调用用户main方法,然后编译、提交
- 干净
- 进程模型用户包用完销毁,引擎版本包通过目录隔离,不用考虑多版本问题。
- 但这也到来了缺点,每次都得走一遍大量class 加载、校验等jvm启动全流程。同时,大多数作业的的执行计划生成耗时是在20秒以内,也就是说此时瓶颈不在编译阶段,此时jvm启动开销就成为了瓶颈。尤其当这些操作极其高频时,带来的开销不容小视。
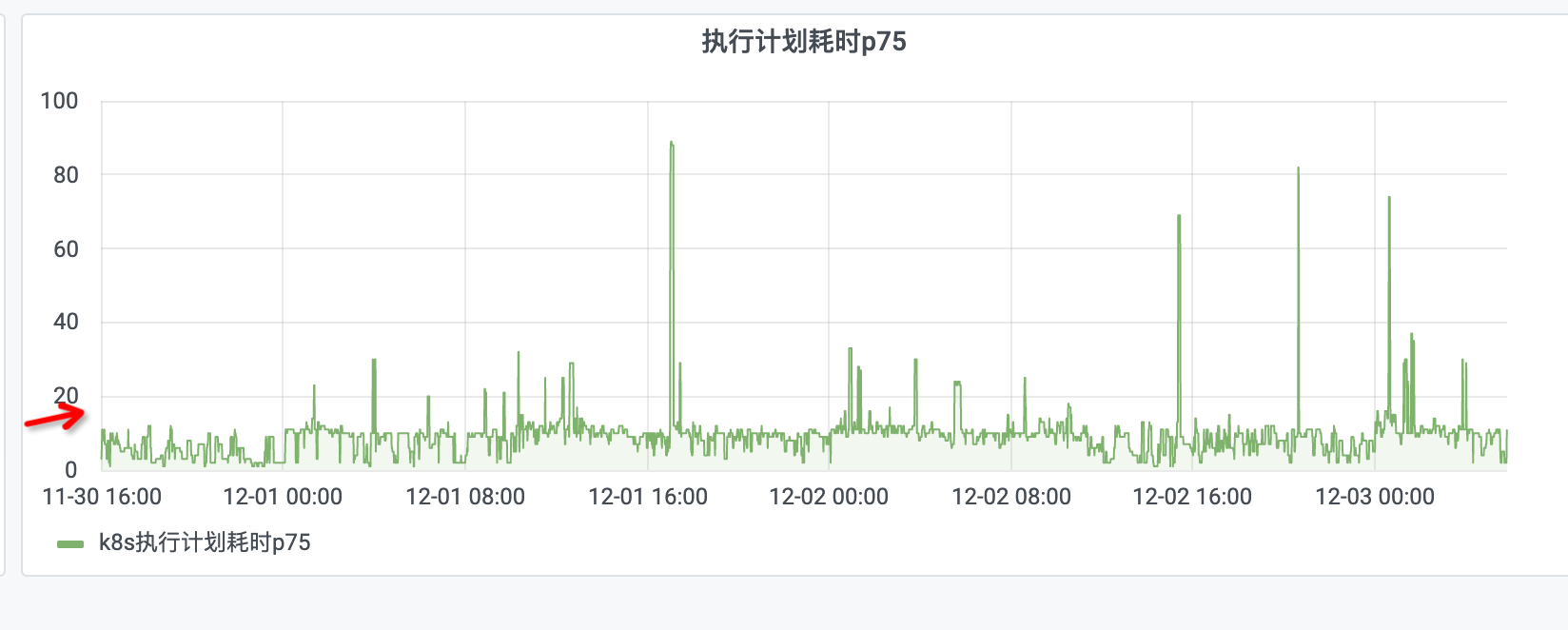
- 下图是blink作业模式下的plan生成和提交的耗时情况。

技术演进
JVM 进程冷启动层面优化
- 下图展示的是一个典型的Java应用各模块执行时间的分布情况。从JVM启动到应用程序开始执行需要经历:VM加载,字节码文件加载,以及JIT(just in time)编译技术对解释执行的字节码进行优化,生成本地执行代码的过程,还需加上JVM内部垃圾回收所耗费的时间。 典型的Java应用加载时间通常是秒级起步,如果遇到比较大的应用初始花费几分钟都是正常的。

CDS
- CDS全称是 Class-Data Sharing,其可以让类可以被预处理放到一个归档文件中,后续 Java 程序启动时将该归档文件映射到内存中,类加载器复用上一次进程启动时曾经加载、验证过的类信息,以节约应用启动的时间。换句话就是避免每次进程冷启动。
缺点:
通过CDS方案改进提交,虽然有些效果,但是总体上差强人意,核心缺点却不容忽视:
- 仅能做到作业级别class复用
- 原因:由于不同用户作业很大可能依赖不同版本的包,做class缓存时就会存在冲突。
- 间接带来的问题:
- 每个作业需要缓存大量class,对brs服务磁盘带来巨大压力(单个作业缓存数据100MB以上)。
- 引入CDS清理机制:由于blink作业操作并不复合近期操作原则,此时后续作业操作cds命中不了。
AOT
- AOT提前编译也不是一个新鲜的概念,在Java之前、很多其他的语言已经提出了AOT。DK9 引入了AOT(Ahead of Time) 编译技术,核心思想是在程序运行之前将class编译成native的code,程序运行阶段从原先的解释执行变成执行native code,从而减少冷启动问题。

缺点:
- 有较多限制,同时业界并没有大规模使用:
- 1、暂不支持自定义ClassLoader
- 2、不支持CMS和ZGC
- 在我们场景测试下来,效果并不好
常驻服务生成
- 常驻服务生成方案:
- 可以在blink rest server机器上,部署额外服务,负责生成plan/jobgraph(该服务和blink rest server同属一个进程)
- 面临核心痛点问题:
- 引擎版本间的兼容性没有保证,如何支持引擎多版本?
- 方案1:多进程方案(每个版本额外启动一个常驻进程)
- 为了更快速地支持业务需求、快速迭代,我们团队基本保持着半个月内发版的频率。
- 为了尽快fix用户问题,也会发布临时版本
- 基于此,该方案不可行,否则会有大量进场。
- 方案2:多classloader方案
- 每个版本一个classloader,通过classloader做jar包隔离。
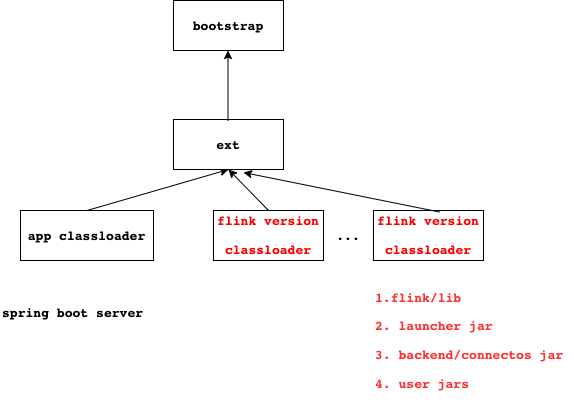
引擎多版本classloader方案实现思路
- 先做下简要背景说明,作业包可分为下面4种情况
- flink/lib依赖包
- launcher包:包涵和引擎交互的包。如plan/jobgraph的生成、资源plan apply到jobgraph中、热更新等
- user jar用户jar包: 作业级别
- connnector/backend插件包
- 引擎当前为了支持平台包优先级高于引擎端而设计
- 可以当做用户jar包来看
引入version classloader
- 可以简单使用该classloader层级关系做隔离
- 由于每个作业的user jar包不同,则version classloader没法复用
- version classloader用完及释放,此时和进程模型相比也就没有太大区别,即性能会不好。
进一步引入reuqest level classloader
- 思路:
- 由于version级别的classloader,很少或者不变动,可复用。
- request级别的classloader每次用完立即释放
- 由于每个作业的用户jar不同,没法复用
- launcher包的功能如何暴露给spring boot server(即blink rest server)使用呢?
- spring boot server通过反射调用launcher包中的方法即可
- 但是遵循一下规则即可:
- 由于该spring boot server和flink打交道通过launcher包,暴露的方法参数务必注意只能是jdk的类
- 假如暴露的参数使用的是开源库的类,哪怕version classloader和spring boot的app都有该jar包,但是此时类是不同的classloader加载了,会导致LinkageError问题。
- 优点:
- version classloader和spring boot的app classloader没有继承关系,做到了干净隔离,因此该spring boot可以随便依赖flink、甚至blink或者其他依赖,并不影响该服务
- 将version classloader cache起来,复用率非常高
- 当同版本更新发布或者测试环境希望仅仅更新某变更jar包做验证时,通过监听版本包目录jar包变更,让classloader缓存失效,重新构建即可。

思考
- 为啥hive/spark/flink计算引擎都是通过自定义classloader方案,不采用类似上面的方案,如下图1所示呢?
- 自定义classloader本质上是想解决用户jar和引擎包冲突的问题
- 但是用户包和引擎包的交互:
- 1) 不可能像上面方案交互是单向的
- 上面方案:spring boot server仅单向访问引擎launcher提供的接口
- 而对于计算引擎来说,user code访问引擎代码,引擎代码依赖user code的返回值是不可避免的。
- 2) 不可能像上面方案约束暴露的方法参数必须为jdk的类
- 否则用户用起来一定很不爽
- 基于上面两点,计算引擎自然不可能使用下面图1方案,而是图2方案。

图1:flink classloader方案改造

图2:flink 自定义classloader 引擎当前方案
- 那么计算引擎使用图2的方案存在什么问题呢?
- LinkageError无法避免
- 由于相互交互,同一个类被不同的classloader加载然后相互引用,细节见笔者分析的文档链接
- 虽然flink对此做了很多改进,但是该问题无法根本解决
- 比如引擎已经约束好哪些包是必须交给app classloader加载,防止被user classloader加载,那么相互引用就不会有问题
- 但不可能放进去很多,否则不同版本三方包冲突问题不就随之而来。所以又暴露了用户级别配置,用户作业运行时报LinkageError问题,用户把对应的包路径塞入配置即可。但如果两个classloader比如需要且引用,则没有办法解
- ClassNotFoundExceotion报错诡异,让人困惑
- 一般地,用户插件包该错,很简单,user jar打上依赖即可
- 但是有些情况,就比较绕。
- 先铺垫下基础知识, classloader类加载机制3原则:
- 全盘负责:所谓全盘负责,就是当一个类加载器负责加载某个Class时,该Class所依赖和引用其他Class也将由该类加载器负责载入,除非显示使用另外一个类加载器来载入,如class.forName(, classloader)。
- 双亲委派:所谓的双亲委派,则是先让父类加载器试图加载该Class,只有在父类加载器无法加载该类时才尝试从自己的类路径中加载该类。通俗的讲,就是某个特定的类加载器在接到加载类的请求时,首先将加载任务委托给父加载器,依次递归,如果父加载器可以完成类加载任务,就成功返回;只有父加载器无法完成此加载任务时,才自己去加载。
- 缓存机制:缓存机制将会保证所有加载过的Class都会被缓存,当程序中需要使用某个Class时,类加载器先从缓存区中搜寻该Class,只有当缓存区中不存在该Class对象时,系统才会读取该类对应的二进制数据,并将其转换成Class对象,存入缓冲区中。这就是为很么修改了Class后,必须重新启动JVM,程序所做的修改才会生效的原因。
- 举例:A, B, C三个类依赖关系如下图,但是类B对应的jar在两个classloader中都有。
- 此时B在进程启动时,已经被父classloader加载。然后调用user code时,调用了A -> B -> C。由于B已经被父classloader加载,根据全盘负责原则此时C将交给父classloader加载,而父classloader没有该C的jar包,则报ClassNotFoundExceotion。
- 但是用户就很困惑,调用链明明是我的代码,而且我的包中已经有该class,为什么会报这个错呢
- 解决办法:
- 将B从父classpath去除。不可行,这样父classloader在进程启动前,就报ClassNotFoundExceotion了
- 对user code中B 做shade改包名,一般该解法可行。但是比较trick的是用户代码依赖的B不是依赖形式使用,而是以hard code编码方式。如果让用户改动依赖代码,就很麻烦。
- 最终临时是将该依赖打入到父classpath。但是对于引擎来说,就会有较大改动。如果是广泛使用的包,又会很容易和其他用户作业冲突。

效果
- 通过多版本classloader方案优化后,经测试简单作业plan耗时从10秒降低到1秒以内,有数量级级别的提升
- 同时,从背景说明章节的图中可看到绝大多数作业都为简单作业

作业提交和jobgraph生成解耦
- blink/flink核心在于jobgraph,而session/perjob/application模式核心仅仅在于生成job graph的位置不同、是否支持多作业而已。具体细节见笔者之前写的文档链接
- blink 采用single job的session模式,提交作业时先拉起JobManager,然后同步方式等pod拉起之后(拉起需要申请pod比较耗时),之后在编译作业生成jobgraph。如果发现不兼容再退出JM作业,则前面耗时的工作白做了
- 基于此,我们实现flink支持k8s per job模式,解耦作业提交和jobgraph生成。在客户端提前生成jobgraph,如果不兼容直接报错了,无需拉起JobManager。
- 解耦后,可以做很多优化。运维态不变更作业。可以直接复用已经生成的jobgraph,无需再重复生成等。
- 同时,为了统一代码栈,降低开发成本,也扩展datastream作业支持per job模式提交。

结语
- 提交主要分为两个阶段client段和服务端,本文主要从客户端优化出发,对于服务端提交优化,蚂蚁实时计算团队还做了其他大量工作,如镜像加速(镜像拉取的优化)、集群模式(申请TaskManager资源时,不走sigma镜像方式,直接起进程方式)、热更新(对用户作业不修改情况下,不走整个提交流程,复用k8s的flink集群)。
参考文档链接:
[1]https://www.yuque.com/g/jackylau-sc7w6/bve18l/rgy8y7e47abmw17c/collaborator/join?token=dGXoLPcmNkj0ILEP#%20《包冲突常见解法》
[2]https://www.yuque.com/g/jackylau-sc7w6/bve18l/tui3w27uq7rush3o/collaborator/join?token=oVoqrCtZYs3152jY#%20《Flink%20JobGraph核心信息》
