






告别Agent Skills, 拥抱 Agent Apps
在AI Agent时代,传统GUI为人类设计,而LLM缺乏视觉、双手与持续感知能力。AOTUI(面向Agent的文本界面)应运而生:以语义化Markdown替代像素渲染,用类型化引用(如`Contact:contacts[2]`)实现“选择”,以Tool函数调用替代鼠标操作,构建专为LLM优化的离散快照式交互范式。
大模型应用:大模型性能评估指标:CLUE任务与数据集详解.10
CLUE(中文语言理解评估基准)是专为中文大模型设计的综合性评测体系,涵盖文本分类、自然语言推理、命名实体识别、阅读理解等任务,提供准确率、F1值、精确匹配等多维指标,并支持模块化评估与可视化分析,助力客观、全面衡量模型真实能力。(239字)
【教案生成平台】实战教程二:接入 AI 大模型实现智能教案生成
一款基于 Vue 3 + Vite 的教师辅助工具,聚焦教案智能生成。输入课程主题,AI 流式输出完整教学设计,支持 Markdown 实时预览与 Word 导出,提升备课效率。核心技术涵盖流式 API 调用、提示词工程与文档生成,构建从输入到输出的完整 AI 工作流。
2026年智能体架构综述:从笨重设计到多智能体架构(MAS)
2024是智能体“前哨战”,2026则是生产级智能体的“分水岭”。告别笨重的单体设计,多智能体系统(MAS)正成为主流。通过“路由+执行者”架构与审计机制,实现专业分工、高效协作。AI不再只是工具,而是企业级操作系统,开启智能化协作新纪元。
计算机领域的Nature-大模型攻克NP难题
Google DeepMind提出FunSearch,突破AI“幻觉”困境。它让大模型生成解题代码而非直接答案,通过进化式筛选发现数学规律,成功破解20年未解的“顶盖集”难题,并优化装箱算法,展现人机协同探索科学真理的新范式。
构建AI智能体:九十三、基于OpenAI Whisper-large-v3模型的本地化部署实现语音识别提取摘要
本文介绍基于OpenAI Whisper-large-v3模型与FastAPI构建高精度语音转文字服务的实践。涵盖模型加载优化、多格式音频处理、RESTful API设计及生产级部署方案,分享从零打造高性能、可扩展ASR系统的完整经验。
Qwen3-Omni新升级:声形意合,令出智随!
Qwen3-Omni-Flash-2025-12-01是全新升级的全模态大模型,支持文本、图像、音频、视频输入,实现自然语音与文本同步输出。全面优化音视频理解与生成,支持多轮流畅对话、自定义人设与系统指令,提升多语言及跨模态交互准确性,语音更拟人,图像视频理解更深入,打造“声形意合”的智能交互体验。(239字)
LLM 内存需求计算方式
GPU上大语言模型的内存主要由模型权重和KV缓存构成。70亿参数模型以16位精度加载时,权重占约14GB;KV缓存则随批大小和序列长度线性增长,显著影响显存使用,限制推理吞吐与长上下文处理。

RAG分块技术全景图:5大策略解剖与千万级生产环境验证
本文深入解析RAG系统中的五大文本分块策略,包括固定尺寸、语义、递归、结构和LLM分块,探讨其工程实现与优化方案,帮助提升知识检索精度与LLM生成效果。

AI-Compass LLM合集-多模态模块:30+前沿大模型技术生态,涵盖GPT-4V、Gemini Vision等国际领先与通义千问VL等国产优秀模型
AI-Compass LLM合集-多模态模块:30+前沿大模型技术生态,涵盖GPT-4V、Gemini Vision等国际领先与通义千问VL等国产优秀模型
大模型应用:语料库治理实战:基于 text2vec+BERT 的由浅入深解析.41
本文介绍中小企业及个人开发者如何高效治理小语料库,提出“以质取胜”理念。基于本地部署的text2vec-base-chinese(语义去重)与bert-base-chinese(质量评分)双模型协同方案,覆盖清洗、去重、质检、细筛等六步流程,显著提升模型效果,兼顾安全性与低成本。(239字)
大模型应用:完整语音交互闭环:TTS+ASR融合系统可视化场景实践.22
本文介绍了一个轻量级TTS+ASR融合交互系统,基于HTML/CSS/JS前端与Python Flask后端,集成Whisper语音识别与pyttsx3文本转语音,实现“语音→文本→语音”闭环。支持浏览器录音、实时转写、语音播放及历史管理,无需依赖框架或网络,适合快速部署与二次开发。
英伟达三大AI法宝:CUDA、NVLink、InfiniBand——构筑AI时代的算力基石
英伟达三大AI法宝——CUDA(编程层)、NVLink(芯片互连)、InfiniBand(系统互连),构成软硬协同的全栈加速体系:CUDA释放GPU通用算力,NVLink实现多卡高速协同,InfiniBand支撑万卡集群高效通信,共同筑就AI时代的算力基石。(239字)
OCR与语义分割技术详解:法小师如何智能解析纸质合同
语义分割结合OCR,实现文档像素级理解,精准识别标题、表格、签名等元素,破解传统OCR无法解析版面的难题。通过深度学习与多模态融合,将复杂合同转化为可编辑、可分析的结构化数据,助力智能文档处理迈向“机器认知”新阶段。(238字)

GLM-4.7实战指南:三个梯度测试,解锁国产大模型的代码生成与审美上限
国产大模型 GLM-4.7 在前端代码生成与智能体编程(Agentic Coding)上实现突破,凭借强大的逻辑推理、UI 审美与交互设计能力,可媲美 Claude 3.5 Sonnet。实测显示,其在 SVG 生成、网页游戏开发及高级页面设计中表现惊艳,支持长上下文、高性价比 API,成为开发者高效落地 AI 编程的优选工具。
TensorRT-LLM 推理服务实战指南
`trtllm-serve` 是 TensorRT-LLM 官方推理服务工具,支持一键部署兼容 OpenAI API 的生产级服务,提供模型查询、文本与对话补全等接口,并兼容多模态及分布式部署,助力高效推理。
精通RAG:从“能用”到“好用”的进阶优化与评估之道
你的RAG应用是否总是答非所问,或者检索到的内容质量不高?本文聚焦于RAG系统的进阶优化,深入探讨从查询转换、多路召回与重排序(Rerank)等高级检索策略,到知识库构建的最佳实践。更重要的是,我们将引入强大的`Ragas`评估框架,教你如何用数据驱动的方式,科学地量化和提升你的RAG系统性能。
先SFT后RL但是效果不佳?你可能没用好“离线专家数据”!
通义实验室Trinity-RFT团队提出CHORD框架,通过动态融合SFT与RL,解决大模型训练中“越学越差”“顾此失彼”等问题。该框架引入细粒度Token级权重与软过渡机制,实现从模仿到超越的高效学习,在数学推理与通用任务上均显著提升性能,相关代码已开源。
通义万相新模型开源,首尾帧图一键生成特效视频!
通义万相首尾帧生视频14B模型正式开源,作为首个百亿级参数规模的开源模型,可依据用户提供的开始与结束图片生成720p高清衔接视频,满足延时摄影、变身等定制化需求。用户上传两张图片或输入提示词即可完成复杂视频生成任务,支持运镜控制和特效变化。该模型基于Wan2.1架构改进,训练数据专门构建,确保高分辨率和流畅性。

用自然语言对话云平台:aliyun-cli skills 的一次尝试
`aliyun cli skills` 是一个创新的AI运维工具:让大模型像工程师一样使用阿里云CLI——通过自然语言理解用户意图,动态调用`--help`获取真实命令语法,自动生成、审查并执行结构化CLI命令(支持ECS/VPC/OSS等全产品),实现“说话即运维”。
《大模型 RAG 召回率保卫战:基于 AISO 规范的实体对齐与重排实践》
本文提出AISO规范的语义约束层,通过引入垂直领域知识图谱,在向量检索前实施实体对齐与本体校验,有效缓解长尾Query的语义塌陷问题,显著提升召回稳定性与实体对齐精度(准确率升至0.87),降低LLM纠错开销。
多智能体如何高效协作?AI Agent指挥官与AI调度官的实践方法
本文提出AI Agent“指挥官+调度官”协同治理机制,通过角色分离、统一调度与规则约束,解决多智能体系统中的任务冲突、资源争抢与决策分散问题,提升复杂场景下的可扩展性、稳定性与可解释性。
被Nature旗下刊物收录!我用AgentScope造了个“AI社科实验室”
科学家用AI模拟学术世界!通义实验室联合人大打造虚拟学术宇宙CiteAgent,基于自研多智能体框架AgentScope,实现数万AI科学家协同仿真,复现引文网络三大经典现象。研究获顶刊《Nature》子刊录用,开创社会科学“实验室”,推动“AI for Social Science”新范式。(回复CiteAgent获取论文)

屏幕拍照精准溯源:从“防不住”到“不敢泄”的震慑闭环是如何形成的?
屏幕拍照泄密频发,隐形水印技术以“无感嵌入、拍必留痕”破解防护难题。通过在显示画面中嵌入用户身份、设备信息等溯源数据,实现拍照即锁定责任人,构建“事前威慑、事中记录、事后追责”的全链路闭环,筑牢“不敢泄、不能泄、不想泄”安全防线。
国家网信办发布的第十四批深度合成算法备案综合分析报告
截至2025年11月,全国深度合成算法备案达5100款,广东以1329款居首,服务提供者占比77.1%。第14批新增680款创新高,医疗、教育、企业服务成主流方向,多模态与垂直领域加速发展,AI合规进入“政策+市场”双驱动新阶段。
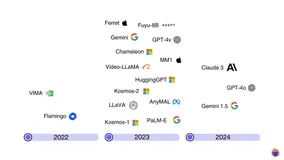
多模态AI重构科研范式:从"读文献"到"理解世界"
2025年,多模态AI正重塑科研:可同时理解文字、图像、公式等,实现文献智能解析、数据自动提取与跨学科融合,大幅提升研究效率。AI助力科研进入“人机协同”新时代,释放创造力,推动知识发现跃迁。
通义灵码+支付 MCP:30 分钟实现创作打赏智能体
本文介绍如何使用通义灵码智能体与 qwen3 和支付 MCP 编写创作打赏智能体,该智能体能够完成日常聊天、诗词创作和请求打赏并生成支付链接功能。
解密Qwen3三连发:强化学习新算法GSPO!
强化学习(RL)是提升语言模型推理与问题求解能力的关键技术。然而,现有算法如 GRPO 在长期训练中存在严重不稳定性,限制了性能提升。为此,我们提出 **Group Sequence Policy Optimization (GSPO)**,通过在序列层面定义重要性比率并进行优化,显著提升了训练效率与稳定性。GSPO 在 MoE 模型训练中表现出色,无需依赖复杂策略即可实现高效训练,简化了 RL 基础设施。该算法已成功应用于 Qwen3 系列模型,推动 RL scaling 边界,释放模型潜能。
ModelEngine思想落地指南:用“智能体 + 插件”构建可复用AI应用.76
ModelEngine是一种AI应用开发范式,通过角色化智能体分工、插件化工具集成与双模式(低代码+代码)开发,解决重复造轮子、流程碎片化、技术门槛高等痛点,实现高效、灵活、可复用的AI应用构建。
大模型应用:快速搭建轻量级智能体:从模型下载到图文输出简单实践.75
本文介绍如何用轻量级Qwen1.5-1.8B-Chat模型(单卡4G显存或CPU即可运行)搭建本地智能体:从高速下载缓存、文本对话交互,到解析用户指令生成绘图参数,并用Pillow绘制文字海报、几何图形、渐变/抽象艺术图,全程代码清晰、开箱即用,适合大模型入门实操。
大模型应用:本地大模型API调用鉴权可视化全解析:从基础实现到业务扩展.45
本文详解本地大模型(如Qwen1.5-1.8B)的轻量级落地方案:基于FastAPI封装带API Key/JWT双鉴权的文本生成API,结合Streamlit构建可视化前端,支持参数调节、IP限流、历史记录与令牌自动刷新,CPU即可运行,兼顾安全性与易用性。
智能体如何被统一管理?AI Agent 指挥官的底层逻辑
AI Agent指挥官是面向多智能体系统的统一调度中枢,通过目标拆解、动态分配、状态管控与闭环约束,解决协作失序、结果不可控等难题,提升自动化系统的稳定性、可解释性与可扩展性,正成为智能体规模化落地的关键基础设施。
大模型应用:情感分析模型微调深度分析:从基础预测到性能优化.6
本文系统讲解中文情感分析模型微调后的深度评估方法,涵盖微调流程、预测置信度分析、混淆矩阵可视化、错误模式挖掘及系统性偏差诊断,强调超越准确率的可解释性分析,助力构建可靠、鲁棒的AI系统。
架构设计实践:如何构建基于 LLM 的 AI Agent "指挥官" (Commander) 模式
本文提出一种基于“指挥官(Commander)”的中心化调度架构,解决多Agent协作中的循环沟通、目标漂移等问题。通过Prompt工程与状态机设计,实现任务拆解、分发与验收,并结合阿里云百炼平台与通义千问模型,提供可落地的代码级实现方案,构建稳定可控的AI多智能体系统。(238字)
大模型应用:基于本地大模型的中文命名实体识别技术实践与应用
本文探讨了基于本地部署的大模型在命名实体识别(NER)任务中的应用优势。通过通用领域中文NER和医疗领域专用NER两个典型案例,展示了本地大模型在数据安全、响应速度和识别精度方面的显著优势。通用领域采用RoBERTa模型在CLUENER2020数据集上微调,可识别10类实体;医疗领域基于BERT架构的专用模型,在CMEEE数据集上训练,准确识别疾病、症状等医疗实体。本地部署不仅满足合规要求,还能通过领域自适应提升专业文本识别效果,为各行业智能化转型提供可靠技术方案。
智能体领航员:2026 开启“智能体互联网 (IoA)”下的全自动商业博弈
2026年,智能体互联网(IoA)爆发,智能体从“替代人工”迈向“自主交易”。通过语义化握手、自主谈判与分布式协议,实现跨域意图拦截与资源套利。领航员将升级为规则制定者,掌控价值对齐与安全边界,开启全自动商业新纪元。
企业AI落地第一步:用RAG技术,让大模型“读懂”你的内部知识库
大家好,我是AI伙伴狸猫算君。本文带你深入浅出了解RAG(检索增强生成)——让大模型“懂”企业私有知识的利器。通过“先检索、再生成”的机制,RAG使AI能基于公司文档精准作答,广泛应用于智能客服、知识库问答等场景。文章详解其原理、四步架构、Python实战代码及评估方法,助力非算法人员也能快速构建企业专属AI助手,实现知识智能化落地。
构建AI智能体:八十七、KM与Chinchilla法则:AI模型发展的两种训练法则完全解析
摘要: 大模型训练中,如何在有限计算预算(C≈6ND)下最优分配模型参数量(N)与训练数据量(D)是关键挑战。KM扩展法则主张“模型优先”,认为增大N的收益高于D(α=0.076<β=0.103),推荐N∝C^0.73、D∝C^0.27。Chinchilla法则则通过实验发现大模型普遍训练不足,提出平衡策略(α=β≈0.38),推荐N∝D∝C^0.5,即在相同预算下减小模型规模并大幅增加数据量,可提升性能。
大模型微调技术入门:从核心概念到实战落地全攻略
本课程系统讲解大模型微调核心技术,涵盖全量微调与高效微调(LoRA/QLoRA)原理、优劣对比及适用场景,深入解析对话定制、领域知识注入、复杂推理等四大应用,并介绍Unsloth、LLaMA-Factory等主流工具与EvalScope评估框架,助力从入门到实战落地。
大模型微调技术入门:从核心概念到实战落地全攻略
本课程系统讲解大模型微调核心技术,涵盖LoRA、QLoRA等高效方法,结合ComfyUI与主流工具实战,从数据准备到模型部署全流程落地,助力开发者低成本定制专属AI模型。
构建AI智能体:七十一、模型评估指南:准确率、精确率、F1分数与ROC/AUC的深度解析
本文系统介绍了机器学习模型评估的核心指标与方法。首先阐述了混淆矩阵的构成(TP/FP/FN/TN),并基于此详细讲解了准确率、精确率、召回率和F1分数的计算原理和适用场景。特别指出准确率在不平衡数据中的局限性,强调精确率(减少误报)和召回率(减少漏报)的权衡关系。然后介绍了ROC曲线和AUC值的解读方法,说明如何通过调整分类阈值来优化模型性能。最后总结了不同业务场景下的指标选择策略:高精度场景侧重精确率,高召回场景关注召回率,平衡场景优选F1分数,不平衡数据则推荐使用AUC评估。
智能体来了!当今高校毕业生新蓝海:成为AI智能体IP操盘手!
AI浪潮重塑就业,“AI智能体IP操盘手”应运而生。大学生可借专业背景与数字技能,打造虚拟IP,实现轻创业。掌握提示词、低代码平台,赋予AI人格与商业价值,开启职业新蓝海。
技术人的知识输出利器:一套高质量知乎回答生成指令模板
本文提供一套系统化知乎高赞回答生成模板,结合AI工具(如DeepSeek、通义千问),助力技术人高效输出高质量内容。涵盖结构框架、质量检查、实战示例与合规建议,提升表达清晰度与内容价值,适用于经验分享、技术科普等多种场景,实现知识输出的标准化与高效化。

Redis-常用语法以及java互联实践案例
本文详细介绍了Redis的数据结构、常用命令及其Java客户端的使用,涵盖String、Hash、List、Set、SortedSet等数据类型及操作,同时提供了Jedis和Spring Boot Data Redis的实战示例,帮助开发者快速掌握Redis在实际项目中的应用。
WEB渗透-文件上传漏洞-下篇
本文详解文件上传安全漏洞,涵盖白名单绕过(如00截断、条件竞争)、图片木马制作与利用、以及IIS、Apache、Nginx等常见解析漏洞原理与防御。结合实战案例,深入剖析攻击手法与修复方案。



