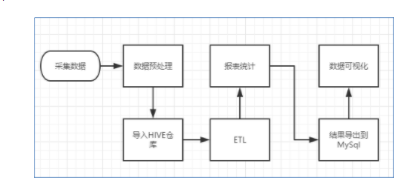
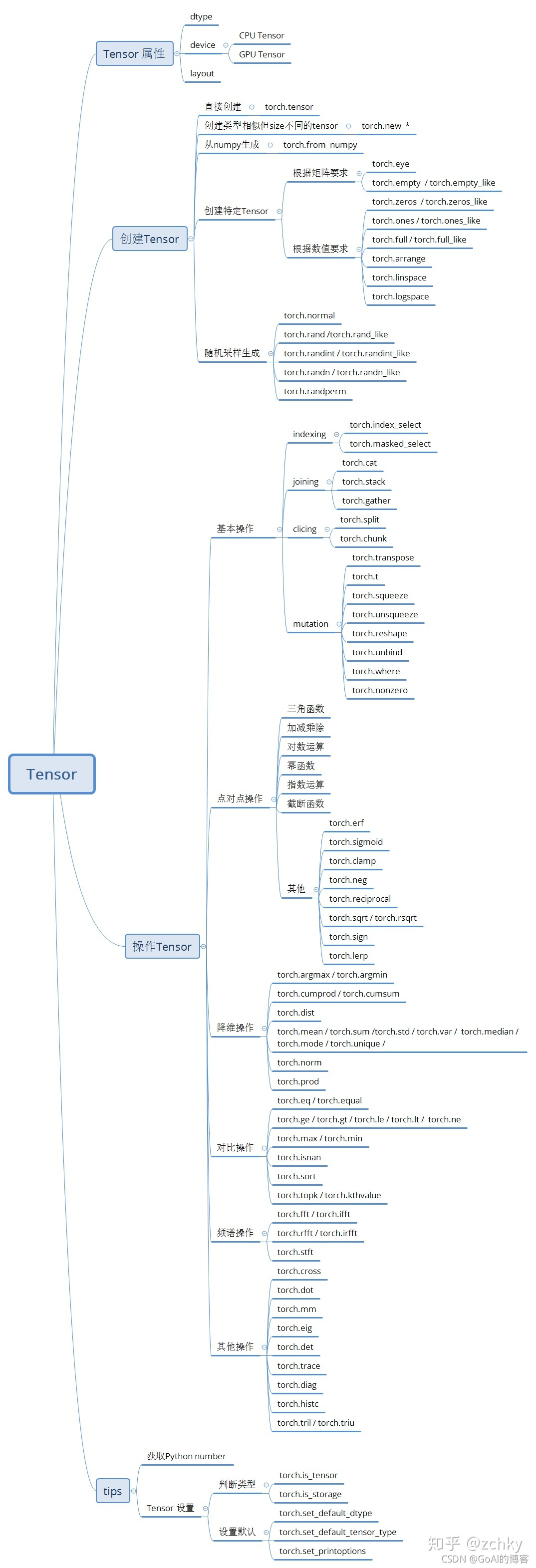
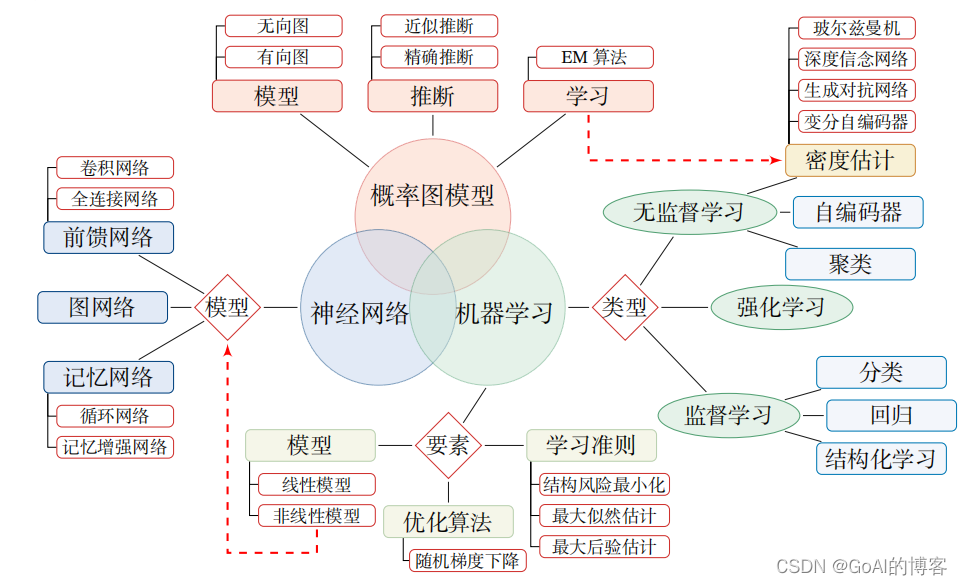
暂时未有相关云产品技术能力~
专注大数据与人工智能技术分享,个人博客:https://blog.csdn.net/qq_36816848
Hadoop:Hadoop是一个分布式存储和计算框架,具有高可靠, 高扩展, 高容错的特点(数据副本和集群);由底层HDFS分布式文件系统负责存储,和MapReduce负责分布式计算,以及后续增加的yarn负责资源协调管理。
分类专栏: Kafka
Kafka常见面试问题
Flume是数据采集,日志收集的框架,通过分布式形式进行采集,(高可用分布式)
Hive调优
HBSAE实践:(先启动zookeeper)
Hive主要解决海量结构化日志的数据统计分析,它是hadoop上的一种数据仓库工具,可以将结构化的数据文件映射成一张表,并提供类似于SQL的查询方式,本质上来说是将Hive转化成MR程序。
Scala学习笔记总结
IDEA官方文档(强推!!!!): README - IntelliJ-IDEA-Tutoria
HBase 本质上是一个数据模型,可以提供快速随机访问海量结构化数据。利用 Hadoop 的文件系统(HDFS)提供的容错能力。它是 Hadoop 的生态系统,使用 HBase 在 HDFS 读取消费/随机访问数据,是 Hadoop 文件系统的一部分。 HBase 是一个面向列的数据库,在表中它由行排序。表模式定义只能列族,也就是键值对。一个表有多个列族以及每一个列族可以有任意数量的列。后续列的值连续地存储在磁盘上。表中的每个单元格值都具有时间戳。总之,在一个 HBase:表是行的集合、行是列族的集合、列族是列的集合、列是键值对的集合。
Spark部署模式与任务提交
基本数据类型对象包装类:是按照面向对象思想将基本数据类型封装成了对象。
基本数据类型对象包装类:是按照面向对象思想将基本数据类型封装成了对象。
1,明确需求。我要做什么? 2,分析思路。我要怎么做?1,2,3。 3,确定步骤。每一个思路部分用到哪些语句,方法,和对象。 4,代码实现。用具体的java语言代码把思路体现出来。 学习新技术的四点: 1,该技术是什么? 2,该技术有什么特点(使用注意): 3,该技术怎么使用。demo 4,该技术什么时候用?test。
Java学习笔记基础
Java学习笔记基础
Hive数仓基本概念介绍
数组和链表组合成的链表散列结构,通过hash算法,尽量将数组中的数据分布均匀,如果hashcode相同再比较equals方法,如果equals方法返回false,那么就将数据以链表的形式存储在数组的对应位置,并将之前在该位置的数据往链表的后面移动,并记录一个next属性,来指示后移的那个数据。注意数组中保存的是entry,其中保存的是键值. HashMap可以接受null键值和值,而HashTable则不能;HashMap是非synchronized;HashMap很快;以及HashMap储存的是键值对等等.
数据结构思维导图汇总
Anaconda基础命令总结
zookeeper3.4.5集群安装
Leader选举是保证分布式数据一致性的关键所在。Leader选举分为Zookeeper集群初始化启动时选举和Zookeeper集群运行期间Leader重新选举两种情况。在讲解Leader选举前先了解一下Zookeeper节点4种可能状态和事务ID概念。
有以下几张数据表,请写出Hive SQL语句,实现以下需求。 注:分区字段为dt,代表日期。
ZooKeeper是一个分布式的,开放源码的,用于分布式应用程序的协调服务。zookeeper服务端有两种模式:单机的独立模式和集群的仲裁模式,所谓仲裁是指一切事件只要满足多数派同意就执行,不需要等到集群中的每个节点反馈才执行。Zookeeper本身也是服从主从架构的,在仲裁模式下会有一个主要的节点作为Leader(领导者),而其余集群中的节点作为Follower(公民),对某一事件是否执行,leader都会先征询各个follower的反馈信息再做决定,如果多数派同意,leader就将命令下发到所有的follower去执行。
数据结构与算法笔记总结
数据结构与算法笔记总结
Python常用函数总结
如果没有显式定义主键,则InnoDB会选择第一个不包含有NULL值的唯一索引作为主键索引。
如果没有显式定义主键,则InnoDB会选择第一个不包含有NULL值的唯一索引作为主键索引。
Git常用命令总结
设计模式有两种分类方法,即根据模式的目的来分和根据模式的作用的范围来分。
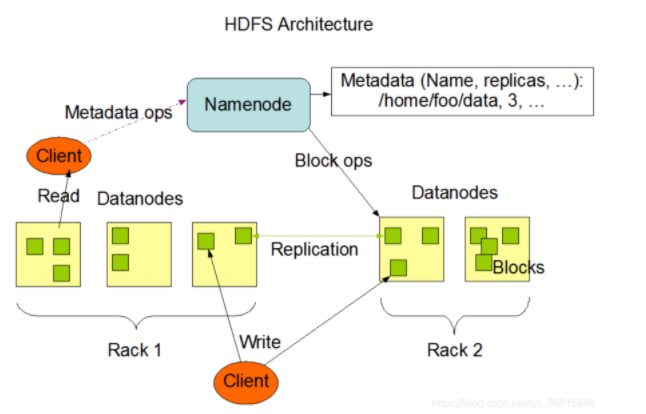
HDFS 是一个分布式文件系统,负责文件存储。它的文件系统和平时看到的Linux很像,有目录结构,顶层目录是/,存放着文件,以及可以对文件进行增删,修改,移动等功能,不同的是它具有分布式的特点,hdfs的文件系统可以横跨多个机器,文件可能是存储在不同机器上的,但用户在使用时会被当作是存储在一台机器上。
Mapreduce概念及流程介绍
Python 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。
Python基础
Linux命令总结
查看数据(查看对象的方法对于Series来说同样适用)
Apache Hadoop YARN 是 apache Software Foundation Hadoop的子项目,为分离Hadoop2.0资源管理和计算组件而引入。YARN的诞生缘于存储于HDFS的数据需要更多的交互模式,不单单是MapReduce模式。Hadoop2.0 的YARN 架构提供了更多的处理框架,不再强迫使用MapReduce框架。
大数据常见端口汇总
首先安装Centos系统修改网络配置: 我的三台机器: master 192.168.179.10 slave1 192.168.179.11 slava2 192.168.179.12 各组件端口号查看: http://www.gaohongwei.cn/530/ CentOS7配置NAT模式网络详细步骤(亲测版) https://blog.csdn.net/Jackson_mvp/article/details/100856966
常见基础命令: • 启动Hadoop • 进入HADOOP_HOME目录。 • 执行sh bin/start-all.sh • 关闭Hadoop • 进入HADOOP_HOME目录。 • 执行sh bin/stop-all.sh
作为python数据分析库,Pandas是基于NumPy数组构建的,使数据预处理、清洗、分析工作变得更快更简单。pandas是专门为处理表格和混杂数据设计的,而NumPy更适合处理统一的数值数组数据。
 发表了文章
2022-10-24
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-20
发表了文章
2022-10-20
发表了文章
2022-10-20
发表了文章
2022-10-20
发表了文章
2022-10-20
发表了文章
2022-10-20
发表了文章
2022-10-24
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-20
发表了文章
2022-10-20
发表了文章
2022-10-20
发表了文章
2022-10-20
发表了文章
2022-10-20
发表了文章
2022-10-20