






DeepMesh:3D建模革命!清华团队让AI自动优化拓扑,1秒生成工业级网格
DeepMesh 是由清华大学和南洋理工大学联合开发的 3D 网格生成框架,基于强化学习和自回归变换器,能够生成高质量的 3D 网格,适用于虚拟环境构建、动态内容生成、角色动画等多种场景。

Soundwave:语音对齐黑科技!开源模型秒解翻译问答,听懂情绪波动
Soundwave 是香港中文大学(深圳)开源的语音理解大模型,专注于语音与文本的智能对齐和理解,支持语音翻译、语音问答、情绪识别等功能,广泛应用于智能语音助手、语言学习等领域。
4G显存部署Flux,2分钟Wan2.1-14B视频生成,DiffSynth-Engine引擎开源!
魔搭社区的开源项目 DiffSynth-Studio 自推出以来,凭借其前沿的技术探索和卓越的创新能力,持续受到开源社区的高度关注与广泛好评。截至目前,该项目已在 GitHub 上斩获超过 8,000 颗星,成为备受瞩目的开源项目之一。作为以技术探索为核心理念的实践平台,DiffSynth-Studio 基于扩散模型(Diffusion Model),在图像生成和视频生成领域孵化出了一系列富有创意且实用的技术成果,其中包括 ExVideo、ArtAug、EliGen 等代表性模块。
上周多模态论文推荐:MAPS、MapGlue、OmniGeo、OThink-MR1
由西安交通大学、新加坡国立大学和南洋理工大学联合提出,该工作推出了MAPS框架,利用基于Big Seven人格理论的七个智能体和苏格拉底式引导,解决多模态科学问题(MSPs)。通过四阶段求解策略和批判性反思智能体,MAPS在EMMA、Olympiad和MathVista数据集上超越当前最佳模型15.84%,展现了卓越的多模态推理与泛化能力。

GPT-4o-mini-transcribe:OpenAI 推出实时语音秒转文本模型!高性价比每分钟0.003美元
GPT-4o-mini-transcribe 是 OpenAI 推出的语音转文本模型,基于 GPT-4o-mini 架构,采用知识蒸馏技术,适合在资源受限的设备上运行,具有高效、实时和高性价比的特点。

Second Me:硅基生命或成现实?如何用AI克隆自己,打造你的AI数字身份!
Second Me 是一个开源AI身份系统,允许用户创建完全私有的个性化AI代理,代表用户的真实自我,支持本地训练和部署,保护用户隐私和数据安全。

SpatialLM:手机视频秒建3D场景!开源空间认知模型颠覆机器人训练
SpatialLM 是群核科技开源的空间理解多模态模型,能够通过普通手机拍摄的视频重建 3D 场景布局,赋予机器人类似人类的空间认知能力,适用于具身智能训练、自动导航、AR/VR 等领域。

Multi-Agent Orchestrator:亚马逊开源AI智能体自动协作黑科技!重构人机交互逻辑,1秒精准分配任务
Multi-Agent Orchestrator 是亚马逊开源的多智能体框架,能够动态分配代理、维护上下文、支持多种代理类型,适用于客户服务、智能交通、物流配送等复杂场景。
用通义万象做一个动态海报庆祝4月24日中国航天日
这段文案描述了一幅动画海报的设计理念,融合传统与现代、科技与梦想。画面以上海黄浦江为背景,明月升起象征传统,火箭升空代表科技探索。穿着旗袍的女孩和多元人群展现文化传承,火箭化为飞船遨游宇宙寓意人类追求未知。古代天文仪器与现代科技呼应,体现历史与未来的对话。整体传达对科技成就的喜悦及对未来的美好期许,致敬中国科学家与宇航员,祝福祖国繁荣昌盛。
不写一行代码,用MCP+魔搭API-Inference 搭建一个本地数据助手! 附所有工具和清单
还在为大模型开发的复杂技术栈、框架不兼容和工具调用问题头疼吗?MCP(Model Context Protocol servers)来拯救你了!它用统一的技术栈、兼容主流框架和简化工具调用的方式,让大模型开发变得简单高效。
今日论文推荐:DeepMesh、TULIP、Cube、STEVE及LEGION
由上海 AI 实验室、西安交通大学等机构提出的 φ-Decoding,是一种全新的推理时间优化策略。该工作通过前瞻采样和聚类技术,平衡了探索与利用的关系,显著提升了大语言模型(LLM)的推理性能。实验表明,其在七个基准测试中超越了强基线,且具备跨模型通用性和计算预算扩展性。

Agent TARS:一键让AI托管电脑!字节开源PC端多模态AI助手,无缝集成浏览器与系统操作
Agent TARS 是一款开源的多模态AI助手,能够通过视觉解析网页并无缝集成命令行和文件系统,帮助用户高效完成复杂任务。

Dify-Plus:企业级AI管理核弹!开源方案吊打SaaS,额度+密钥+鉴权系统全面集成
Dify-Plus 是基于 Dify 二次开发的企业级增强版项目,新增用户额度、密钥管理、Web 登录鉴权等功能,优化权限管理,适合企业场景使用。
GPT-4o-Transcribe:OpenAI 推出高性能语音转文本模型!错误率暴降90%+方言通杀,Whisper当场退役
GPT-4o-Transcribe 是 OpenAI 推出的高性能语音转文本模型,支持多语言和方言,适用于复杂场景如呼叫中心和会议记录,定价为每分钟 0.006 美元。

GPT-4o mini TTS:OpenAI 推出轻量级文本转语音模型!情感操控+白菜价冲击配音圈
GPT-4o mini TTS 是 OpenAI 推出的轻量级文本转语音模型,支持多语言、多情感控制,适用于智能客服、教育学习、智能助手等多种场景。
Crack Coder:在线面试“AI外挂”!编程问题秒出答案,完全绕过屏幕监控,连录屏都抓不到痕迹!
Crack Coder 是一款开源的隐形 AI 辅助工具,专为技术面试设计,支持多种编程语言,提供实时编程问题解决方案,帮助面试者高效解决问题。
阶跃星辰开源Step-Video-TI2V 图生视频模型介绍
在今年 2 月,阶跃星辰开源了两款 Step 系列多模态大模型——Step-Video-T2V 视频生成模型和 Step-Audio 语音模型,为开源社区贡献了自己的多模态力量。

RWKV-7革新序列建模,Impossible Videos探索超现实,Creation-MMBench点燃创意火花: 今日论文
由 RWKV 项目(Linux Foundation AI & Data)和 EleutherAI 等机构提出的 RWKV-7 "Goose",是一种全新的序列建模架构。它在30亿参数规模上刷新了多语言任务的下游性能纪录,媲美顶级英文语言模型,同时仅需恒定内存和推理时间。核心创新包括广义delta规则和上下文学习率优化,超越了传统Transformer的表达能力。作者还开源了3.1万亿token的多语言数据集和代码,助力社区研究。
Umi-OCR:31K Star!离线OCR终结者!公式+二维码+多语种,开源免费吊打付费
Umi-OCR 是一款免费开源的离线 OCR 文字识别工具,支持截图、批量图片、PDF 扫描件的文字识别,内置多语言识别库,提供命令行和 HTTP 接口调用功能。

Step-Video-TI2V:开源视频生成核弹!300亿参数+102帧电影运镜
Step-Video-TI2V 是阶跃星辰推出的开源图生视频模型,支持根据文本和图像生成高质量视频,具备动态性调节和多种镜头运动控制功能,适用于动画制作、短视频创作等场景。
YT Navigator:AI秒搜YouTube!自然语言直达视频关键帧
YT Navigator 是一款 AI 驱动的 YouTube 内容搜索工具,通过自然语言查询快速定位视频中的关键信息,支持与视频内容对话,适用于研究人员、学生和内容创作者。
Manus再遭复刻!开源多智能体协作工具,实时查看每个AI员工的"脑回路"
LangManus 是一个基于分层多智能体系统的 AI 自动化框架,支持多种语言模型和工具集成,能够高效完成复杂任务,适用于人力资源、房产决策、旅行规划等多个场景。
Instella:AMD开源30亿参数语言模型!训练效率碾压同级选手
Instella是AMD推出的30亿参数开源语言模型,基于自回归Transformer架构,支持多轮对话、指令跟随和自然语言理解,适用于智能客服、内容创作和教育辅导等多个领域。
ReCamMaster:视频运镜AI革命!单镜头秒变多机位,AI重渲染颠覆创作
ReCamMaster 是由浙江大学与快手科技联合推出的视频重渲染框架,能够根据用户指定的相机轨迹重新生成视频内容,广泛应用于视频创作、后期制作、教育等领域,提升创作自由度和质量。
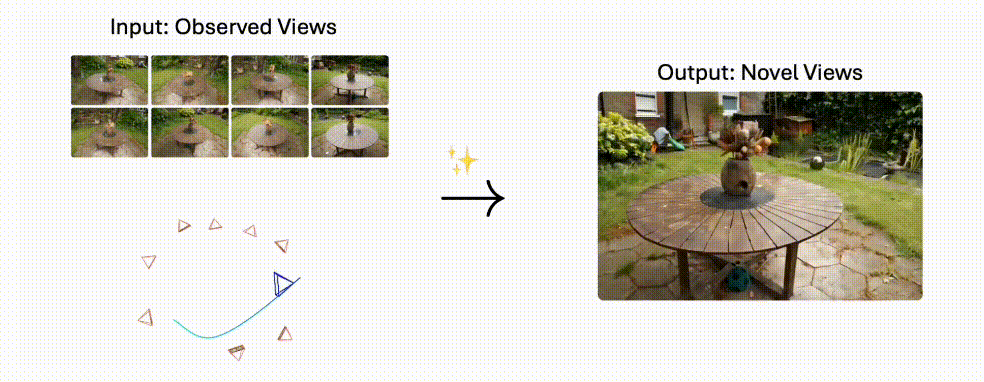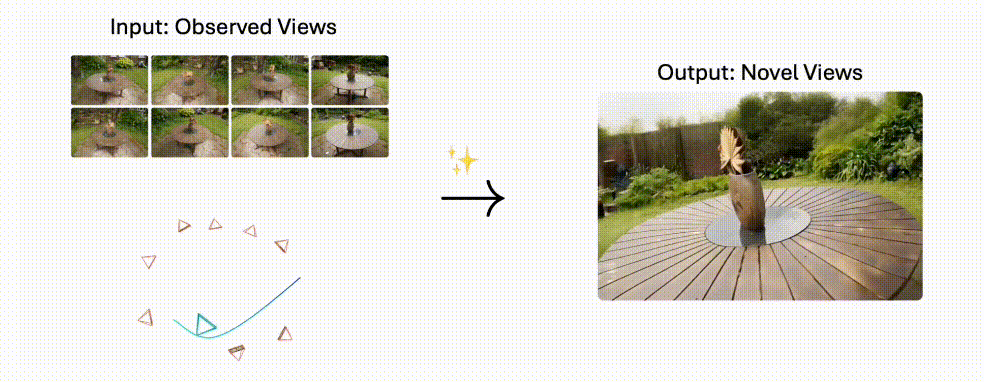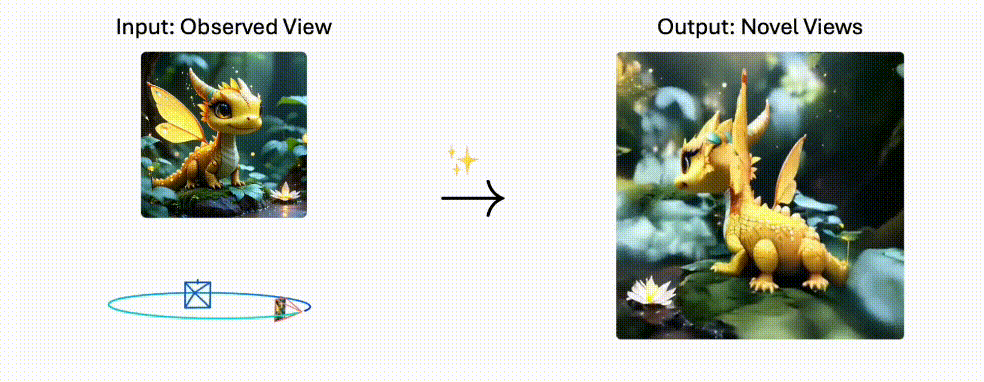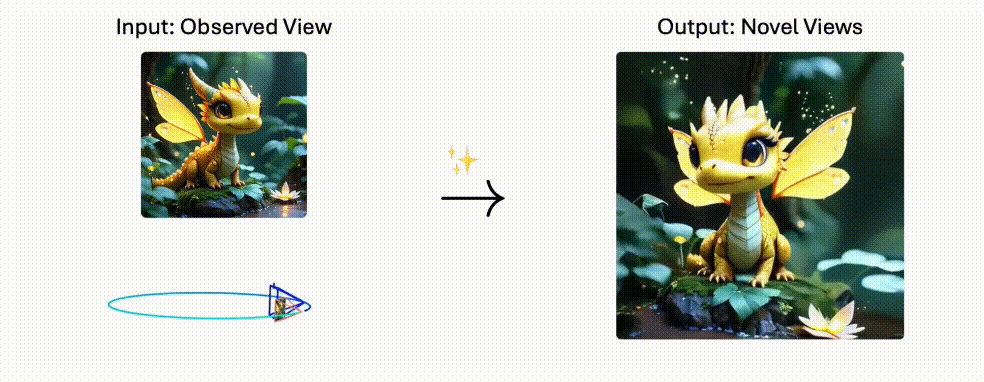
Stable Virtual Camera:2D秒变3D电影!Stability AI黑科技解锁无限运镜,自定义轨迹一键生成
Stable Virtual Camera 是 Stability AI 推出的 AI 模型,能够将 2D 图像转换为具有真实深度和透视感的 3D 视频,支持自定义相机轨迹和多种动态路径,生成高质量且时间平滑的视频。
SmolDocling:256M多模态小模型秒转文档!开源OCR效率提升10倍
SmolDocling 是一款轻量级的多模态文档处理模型,能够将图像文档高效转换为结构化文本,支持文本、公式、图表等多种元素识别,适用于学术论文、技术报告等多类型文档。
MiniMax开源超长文本处理神器,魔搭社区助力开发者推理部署
Transfermor架构与生俱来的二次计算复杂度,及其所带来的上下文窗口瓶颈,一直为业界所关注。此前,MiniMax开源了MiniMax-01系列模型,采用创新的线性注意力架构,使得模型能够在100万个token长度的上下文窗口上进行预训练;而在推理时,实现了高效处理全球最长400万token的上下文,是目前最长上下文窗口的20倍。
Gemma3:Google开源多模态神器,轻量高效,精通140+语言,解锁文本与图像任务
在当今快速发展的 AI 领域,多模态模型正逐渐成为推动技术革新的重要力量。Google 最新推出的 Gemma 3 模型,凭借其轻量级、多模态的特性,为文本生成和图像理解任务带来了全新的可能性。它不仅支持文本和图像输入,还具备强大的语言处理能力,覆盖超过 140 种语言,并且能够在资源有限的设备上高效运行。从问答到摘要,从推理到图像分析,Gemma 3 正在重新定义 AI 模型的边界,为开发者和研究人员提供了一个极具潜力的工具。
今日热门论文推荐:多模态CoT综述、BlobCtrl、Being-0、DreamRenderer、WideRange4D 等
这篇调查论文是首个系统回顾多模态思维链(MCoT)推理的综述。论文阐明了相关基础概念和定义,提供了全面的分类法,并从不同角度对当前方法进行了深入分析。MCoT将思维链推理的优势扩展到多模态环境中,设计了各种方法和创新推理范式来解决图像、视频、语音、音频、3D和结构化数据等不同模态的独特挑战,在机器人技术、医疗保健、自动驾驶和多模态生成等应用中取得了广泛成功。

今日AI论文推荐:ReCamMaster、PLADIS、SmolDocling、FlowTok
由浙江大学、快手科技等机构提出的ReCamMaster是一个相机控制的生成式视频重渲染框架,可以使用新的相机轨迹重现输入视频的动态场景。该工作的核心创新在于利用预训练的文本到视频模型的生成能力,通过一种简单但强大的视频条件机制。为克服高质量训练数据的稀缺问题,研究者使用虚幻引擎5构建了一个全面的多相机同步视频数据集,涵盖多样化的场景和相机运动。
琶洲算法大赛首场高校巡回赛中山大学站圆满收官
近日,琶洲算法大赛高校巡回赛全国首站在中山大学珠海校区圆满收官。琶洲算法大赛定位为国际性算法领域权威赛事,旨在推动人工智能技术创新与产业融合,举办三届以来,琶洲已经评选出41位琶洲领军算法师,落地人才团队170个,极大程度扩充丰富了本地算法人才数量和层级。

小白尖叫!DeepSeek安装竟偷占C盘?这样做路径配置 直接根治存储焦虑
惊! 完蛋了! DeepSeek占满了我的C盘~~~~ DeepSeek让我C盘爆炸~~~再见了,DeepSeek

Cursor 上线最新 AI 模型 Claude 3.7 Max:200k上下文+200次工具调用!史上最强代码助手硬核上线
Claude 3.7 Max 是 Cursor 推出的最新 AI 模型,支持 200k 上下文窗口和 200 次工具调用,专为复杂代码任务设计,适合硬核开发者和大型项目。

I2V3D:微软+港城大黑科技!单图秒变3D动态视频,相机轨迹自由操控
I2V3D 是由香港城市大学和微软联合开发的图像到视频生成框架,支持将静态图像转换为动态视频,基于3D几何引导实现精确的动画控制,适用于动画制作、视频编辑和内容创作等领域。
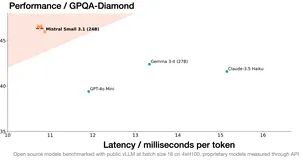
Mistral Small 3.1:240亿参数多模态黑马!128k长文本+图像分析,推理速度150token/秒
Mistral Small 3.1 是 Mistral AI 开源的多模态人工智能模型,具备 240 亿参数,支持文本和图像处理,推理速度快,适合多种应用场景。

OpenBioMed:开源生物医学AI革命!20+工具链破解药物研发「死亡谷」
OpenBioMed 是清华大学智能产业研究院(AIR)和水木分子共同推出的开源平台,专注于 AI 驱动的生物医学研究,提供多模态数据处理、丰富的预训练模型和多样化的计算工具,助力药物研发、精准医疗和多模态理解。

Hunyuan3D 2.0:腾讯混元开源3D生成大模型!图生/文生秒建高精度模型,细节纹理自动合成
Hunyuan3D 2.0 是腾讯推出的大规模 3D 资产生成系统,专注于从文本和图像生成高分辨率的 3D 模型,支持几何生成和纹理合成。

昆仑万维开源 Skywork R1V:开源多模态推理核弹!视觉链式分析超越人类专家
Skywork R1V 是昆仑万维开源的多模态思维链推理模型,具备强大的视觉链式推理能力,能够在多个权威基准测试中取得领先成绩,推动多模态推理模型的发展。
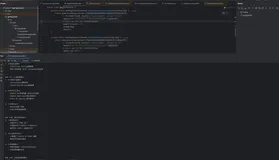
JAVA接入DeepSeek大模型接口开发---阿里云的百炼模型
随着大模型的越来越盛行,现在很多企业开始接入大模型的接口,今天我从java开发角度来写一个demo的示例,用于接入DeepSeek大模型,国内的大模型有很多的接入渠道,今天主要介绍下阿里云的百炼模型,因为这个模型是免费的,只要注册一个账户,就会免费送百万的token进行学习,今天就从一个简单的可以执行的示例开始进行介绍,希望可以分享给各位正在学习的同学们。
ModelScope魔搭25年3月发布月报
在这个春天里,小鲸鱼的DeepSeek-R1系列在模型社区掀起的巨大浪潮尚未平息,我们又迎来了千问的QwQ-32B正式版本,社区在Reasoning模型上的热情还在升温。除此之外,业界其他模型在过去一
本周 AI Benchmark 方向论文推荐
由北京大学和微软亚洲研究院的魏李等人提出的 FEA-Bench,是一个专为评估大型语言模型(LLMs)在代码库级别进行增量开发能力的基准测试。它从 83 个 GitHub 仓库中收集了 1,401 个任务实例,专注于新功能的实现。研究表明,即使是先进的 LLMs 在此任务中的表现仍远低于预期,揭示了仓库级代码开发的重大挑战。
论文推荐:R1-Omni、VisualPRM、4D LangSplat、Vision-R1、GoT
简要介绍:由复旦大学、上海AI实验室等机构提出了首个统一多模态理解和生成的奖励模型UnifiedReward。该工作构建了大规模人类偏好数据集,包含图像和视频生成/理解任务,并利用该模型进行自动构建高质量偏好对数据,最终通过DPO优化视觉模型。实验结果表明,联合学习评估多样化视觉任务可以带来显著的相互益处。
论文推荐:CoSTAast、Transformers without Normalization
由马里兰大学团队提出的CoSTA*,针对多轮图像编辑任务设计了一种成本敏感的工具路径代理。该工作结合大语言模型(LLM)的子任务规划与A搜索算法,构建了一个高效的工具选择路径,不仅降低了计算成本,还提升了图像编辑质量。通过视觉语言模型评估子任务输出,CoSTA能在失败时快速调整路径,并在全新多轮图像编辑基准测试中超越现有最佳模型。
热门论文推荐:TPDiff、Block Diffusion、Reangle-A-Video、GTR
由新加坡国立大学Show Lab的Lingmin Ran和Mike Zheng Shou提出,TPDiff是一个创新的视频扩散模型框架,针对视频生成的高计算需求问题,通过分阶段逐步提高帧率优化了训练和推理效率。核心贡献包括提出“时间金字塔”方法和阶段式扩散训练策略,实验表明训练成本降低50%,推理效率提升1.5倍。
驱动“超真人”虚拟助手Maya的实时语音对话模型CSM-1b开源!
3月14日,创造出病毒级虚拟助手 Maya 的Sesame团队开源了他们的语音生成模型 CSM-1b,可根据文本和音频输入生成 RVQ 音频代码。这意味着,我们每个人都可以0成本拥有一个真正的AI伴侣了,甚至可以自己动手搭建、测试和改进模型。
有效的思考:模型思考效率评测
随着大语言模型的迅速发展,模型的推理能力得到了显著提升。特别是长推理模型(Long Reasoning Models),如OpenAI的o1、DeepSeek-R1、QwQ-32B和Kimi K1.5等,因其展现出类似人类的深度思考能力而备受关注。这些模型通过长时间推理(Inference-Time Scaling),能够在解码阶段不断思考并尝试新的思路来得到正确的答案。
Quick BI 评测报告
本文详细记录了一名项目经理对阿里云Quick BI的全面评测过程。从申请试用账号到数据上传、数据集创建,再到可视化分析与智能功能体验,作者深入探讨了Quick BI的各项功能。文中提到Quick BI具备强大的数据处理能力和友好的用户界面,尤其在可视化和智能化方面表现出色。但同时也指出了数据清洗功能不足、图表配置有限及智能助手能力需提升等问题。整体而言,Quick BI是一款适合项目经理高效分析数据的工具,未来若能优化上述问题,将更具竞争力。

MedRAG:医学AI革命!知识图谱+四层诊断,临床准确率飙升11.32%
MedRAG是南洋理工大学推出的医学诊断模型,结合知识图谱与大语言模型,提升诊断准确率11.32%,支持多模态输入与智能提问,适用于急诊、慢性病管理等多种场景。


