













Opencv(二)—图像分割之分水岭算法
做图像处理时,我们可能会遇到一个问题:我们只需要图片的一部分区域,如何把图片中的某部分区域提取出来 或者 图像想要的区域用某种颜色(与其它区域颜色不一致)标记起来 ,以上描述的问题在像处理领域称为 图像分割

ITK 基础(二) — 图像分割 General Threshold
上篇文章介绍了 ITK 中的二值化分割,最终得到的是 二值图像(图像中只有两种像素值) 但有时我们会遇到另外一种需求,只改变某一阈值范围的像素值,其他部分保留;这时二值化分割已经满足不了我们的基本需求了,需要寻求另外一种方法。 本篇教程介绍 ITK 中的 General Threshold ,是二值化的改进版,可以只改变某一范围内的像素值,并且其它范围内像素值得到保留。
ThinkPHP6.0 实现 图片审核+文本内容审核(敏感词过滤)
应用场景 用户评论过滤:对网站用户的评论信息进行检测,审核出涉及违规内容,保证良好的用户体验 注册信息筛查:对用户的注册信息进行筛查,避免黑产通过用户名实现违规信息的推广 文章内容审核:对UGC文章内容进行多个维度的审核,避免因内容违规导致的APP下架等损失

阿里云智能视觉生产图像处理裁剪/尺寸变换Python SDK使用说明
裁剪/尺寸变换用于对输入的图片进行指定尺寸变换,自动判断主体区域位置,使用最佳的裁剪方式完成裁剪。本文介绍如何使用阿里云智能视觉生产图像处理裁剪/尺寸变换Python SDK,包括SDK的安装方法及SDK代码示例。

ICCV2021 | MicroNet:以极低的 FLOPs 改进图像识别
这篇论文旨在以极低的计算成本解决性能大幅下降的问题。提出了微分解卷积,将卷积矩阵分解为低秩矩阵,将稀疏连接整合到卷积中。提出了一个新的动态激活函数-- Dynamic Shift Max,通过最大化输入特征图与其循环通道移位之间的多个动态融合来改善非线性。

文字识别OCR开源框架的对比--Tesseract vs EasyOCR
OCR文字识别在目前有着比较好的应用,也出现了很多的文字识别软件,但软件是面向用户的。对于我们技术人员来说,有时难免需要在计算机视觉任务中加入文字识别,如车牌号识别,票据识别等,因此软件对我们是没用的,我们需要自己实现文字识别。

基于图像识别的启发式UI自动化测试介绍
使用图像识别技术进行客户端游戏自动化是一种比较通用快捷的做法,是一种不依赖游戏客户端的外部自动化操作。在结合方便的脚本编辑工具后,使得这种自动化测试方式和按键精灵一样门槛极低。 将游戏客户端屏幕内容进行截图。在windows平台需要调用系统获取屏幕内容API进行屏幕画面保存。在Android平台可以调用adb命名进行截图保存。

机器学习(五)聚类之图像分割
灰度、颜色、纹理、形状等特征,把图像分成若干个互不重叠的区域,并使这些特征在同一区域内呈现相似性,在不同的区域之间存在明显的差异性。然后就可以将分割的图像中具有独特
阿里云文字识别(OCR)个人证照识别-身份证识别产品说明
阿里云读光通用识别类OCR识别产品,可将各类常见文档图片或文档扫描件中的文字信息按照文档原有的格式进行文本识别和还原。为了能够更好的还原文字信息和文档结构,读光文档识别在通用全文识别能力(文字定位、行分析、文字识别)的基础上,增加了文档结构的版面分析和文档图像处理能力,使得文档类图像也能按照结构化的方式进行文档元素提取,进一步提升文档识别的产品体验。本文着重介绍个人证照识别-身份证识别产品各参数说明。
阿里云文字识别(OCR)通用文字识别-全文识别高精版产品说明
阿里云读光通用识别类OCR识别产品,可将各类常见文档图片或文档扫描件中的文字信息按照文档原有的格式进行文本识别和还原。为了能够更好的还原文字信息和文档结构,读光文档识别在通用全文识别能力(文字定位、行分析、文字识别)的基础上,增加了文档结构的版面分析和文档图像处理能力,使得文档类图像也能按照结构化的方式进行文档元素提取,进一步提升文档识别的产品体验。本文着重介绍通用文字识别-全文识别高精版产品各参数说明。

【动手学计算机视觉】第三讲:图像预处理之图像分割
图像分割是一种把图像分成若干个独立子区域的技术和过程。在图像的研究和应用中,很多时候我们关注的仅是图像中的目标或前景(其他部分称为背景),它们对应图像中特定的、具有独特性质的区域。为了分割目标,需要将这些区域分离提取出来,在此基础上才有可能进一步利用,如进行特征提取、目标识别。因此,图像分割是由图像处理进到图像分析的关键步骤,在图像领域占据着至关重要的地位。

【动手学计算机视觉】第二讲:图像预处理之图像增强
计算机视觉主要有两部分组成: 特征提取 模型训练 其中第一条特征提取在计算机视觉中占据着至关重要的位置,尤其是在传统的计算机视觉算法中,更为明显,例如比较著名的HOG、DPM等目标识别模型,主要的研究经历都是在图像特征提取方面。图像增强能够有效的增强图像中有价值的信息,改善图像质量,能够满足一些特征分析的需求,因此,可以用于计算机视觉数据预处理中,能够有效的改善图像的质量,进而提升目标识别的精度。
阿里云智能视觉生产图像处理裁剪/尺寸变换Java SDK使用说明
裁剪/尺寸变换用于对输入的图片进行指定尺寸变换,自动判断主体区域位置,使用最佳的裁剪方式完成裁剪。本文介绍如何使用阿里云智能视觉生产图像处理裁剪/尺寸变换Java SDK,包括SDK的安装方法及SDK代码示例。


阿里云内容安全java SDK实现本土图片审核
内容安全是一款多媒体内容智能识别服务,支持对图片、视频、文本、语音等对象进行多样化场景检测,帮助您有效降低内容违规风险。 此篇文章将简单介绍通过javasdk实现本地图片的安全检测
阿里云智能视觉生产图像分析色板分析Java SDK使用说明
色板分析用于对输入图的颜色信息进行分析,给出颜色值(RGB形式和HEX格式)与对应的占比信息。本文介绍如何使用阿里云智能视觉生产图像分析色板分析Java SDK,包括SDK的安装方法及SDK代码示例。
阿里云智能视觉生产图像分析元素识别定位Java SDK使用说明
元素识别定位用于识别输入图中所包含的元素,用矩形框标注出其位置,并区分其对应的基本类型(人/物、修饰、文案)。本文介绍如何使用阿里云智能视觉生产图像分析元素识别定位Java SDK,包括SDK的安装方法及SDK代码示例。
阿里云智能视觉生产图像处理裁剪/尺寸变换Java SDK使用说明
裁剪/尺寸变换用于对输入的图片进行指定尺寸变换,自动判断主体区域位置,使用最佳的裁剪方式完成裁剪。本文介绍如何使用阿里云智能视觉生产图像处理裁剪/尺寸变换Java SDK,包括SDK的安装方法及SDK代码示例。
阿里云智能视觉生产图像处理人像分割Java SDK使用说明
人像分割用于识别输入图像中的人体轮廓,与背景进行分离,返回分割后的前景人像图(4通道),适用于单人、多人、复杂背景、各类人体姿态等场景。本文介绍如何使用阿里云智能视觉生产图像处理人体分割Java SDK,包括SDK的安装方法及SDK代码示例。
阿里云智能视觉生产图像处理通用分割Java SDK使用说明
通用分割是对输入图中主体进行分割,输出对应的png透明图,支持包括人体、动物、物品等。本文介绍如何使用阿里云智能视觉生产图像处理通用分割Java SDK,包括SDK的安装方法及SDK代码示例。

阿里云文字识别(OCR)票据凭证识别Python SDK调用
阿里云文字识别(Optical Character Recognition,OCR)可以将图片中的文字信息转换为可编辑文本,根据客户的业务场景和需求,将产品分为了通用文字识别、个人证照识别、票据凭证识别、教育场景识别、车辆物流识别、企业资质识别、小语种文字识别等,满足各种客户的图片识别需求。此片文章将简单介绍票据凭证识别的python调用


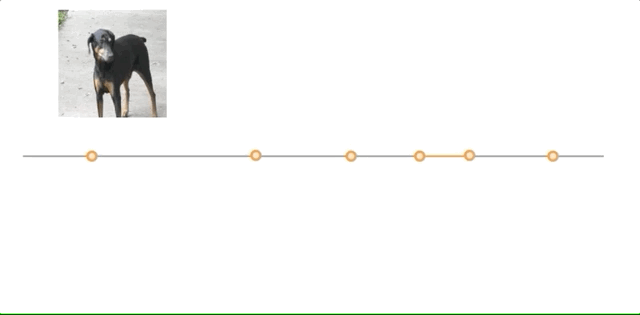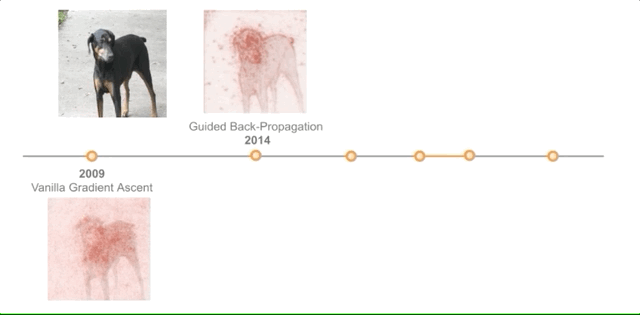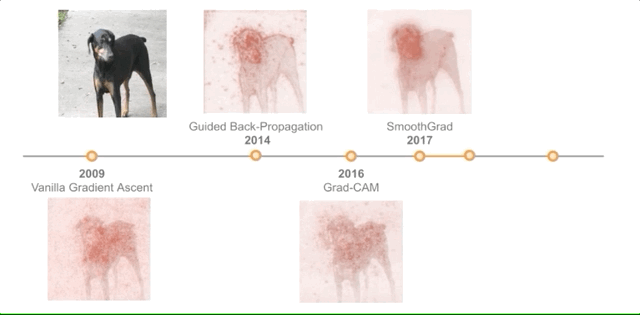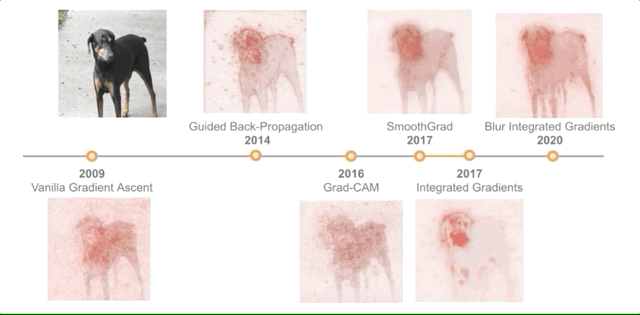

全球最大的图像识别数据库ImageNet不行了?谷歌DeepMind新方法提升精度
来自苏黎世谷歌大脑和DeepMind London的研究人员认为,世界上最受欢迎的图像数据库之一ImageNet需要改造。ImageNet是一个无与伦比的计算机视觉数据集,拥有超过1400万张标记图像。它是为对象识别研究而设计的,并按照WordNet的层次结构进行组织。层次结构的每个节点都由成百上千的图像描述,目前每个节点平均有超过500个图像。

ResNet图像识别准确率暴降40个点!这个ObjectNet让世界最强视觉模型秒变水货
MIT和IBM的研究团队近日发布一个不同寻常的目标识别数据集ObjectNet,包含50000张特意拍摄的照片,尽可能接近真实世界。该数据集让AlexNet、ResNet、Inception等最先进的图像识别模型纷纷栽倒,性能暴降40%~45%。

告别 PlantUML渲染错误:Graphviz安装指南与避坑经验
本文分享了解决Graphviz安装问题的实践经验,针对绘制plantUML类图时出现的报错,提供了两种安装方案。方案1通过Homebrew安装Graphviz,但可能失败;方案2推荐先安装MacPorts,再使用命令`sudo port install graphviz`完成安装。作者为一位资深技术专家,专注于分布式系统与AIGC应用开发,实战经验丰富,更多内容可关注其专栏或访问编程严选网。



吴恩达《Machine Learning》精炼笔记 12:大规模机器学习和图片文字识别 OCR
吴恩达《Machine Learning》精炼笔记 12:大规模机器学习和图片文字识别 OCR




Python 深度学习AI - 利用训练好的模型库进行图像分割、一键抠图实例演示,百度深度学习平台飞浆paddlepaddle-gpu的安装与使用
Python 深度学习AI - 利用训练好的模型库进行图像分割、一键抠图实例演示,百度深度学习平台飞浆paddlepaddle-gpu的安装与使用




基于PYTHON调用阿里云分割抠图-商品分割接口
分割抠图技术基于阿里云深度学习技术,结合检测识别技术,为您提供高精度视觉分割能力。 分割抠图技术可以实现秒级全自动主体、场景像素级识别,制作4通道透明素材。不仅实现了发丝级精抠,对高度镂空主体、复杂背景等场景都有很好的效果,同时支持人、货、场三种类型需求,可广泛应用于电子商务、零售、泛文娱、个人应用等多种场景。 本文章将实现基于python调用商品分割接口,纪念下刚学的python基础

阿里云人工智能印刷文字识别
随着智能手机和移动设备的普及,越来越多的图片被产生,也有越来越多的图片文字识别需求。典型的应用场景有证件信息的自动识别和提取,自然场景中的文字识别,文档或者宣传资料中的文字检测识别等。同时,由于深度学习和图像检测技术的发展,使得上述场景中的文字的检测和识别效果越来越好,使得机器自动识别成为可能,在业务审核中给公司节省了大量的人力。
图像分割库segmentation_models.pytorch和Albumentations 实现图像分割
图像分割库segmentation_models.pytorch和Albumentations 实现图像分割

阿里云市场读光OCR印刷文字识别-身份证识别API调用Java 示例参考
读光是一款由阿里巴巴集团达摩院团队打造的OCR云产品,多年来, 不断整合前沿技术和行业经验,打磨出了能够承载跨行业应用的技术架构,形成了完备的图像文字定位、文字识别和文字理解的技术体系。经过多种数据类型的洗礼和实战经验,读光OCR的识别准确率和处理性能稳居业界领先水平。读光身份证识别支持二代身份证正反面所有字段的识别。支持实拍复印件判断和人脸位置检测。基于达摩院强大的深度学习算法和OCR技术,各字段精度均处于业界领先水平,身份证号码识别准确率达到99.9%以上。本文将介绍身份证识别的快速调试和基于Java的调用。
阿里云市场读光OCR印刷文字识别-身份证识别API调用Java 示例参考
读光是一款由阿里巴巴集团达摩院团队打造的OCR云产品,多年来, 不断整合前沿技术和行业经验,打磨出了能够承载跨行业应用的技术架构,形成了完备的图像文字定位、文字识别和文字理解的技术体系。经过多种数据类型的洗礼和实战经验,读光OCR的识别准确率和处理性能稳居业界领先水平。读光身份证识别支持二代身份证正反面所有字段的识别。支持实拍复印件判断和人脸位置检测。基于达摩院强大的深度学习算法和OCR技术,各字段精度均处于业界领先水平,身份证号码识别准确率达到99.9%以上。本文将介绍身份证识别的快速调试和基于Java的调用。

DL之MaskR-CNN:基于类MaskR-CNN算法(RetinaNet+mask head)训练自己的数据集(.h5文件)从而实现图像分割daiding
DL之MaskR-CNN:基于类MaskR-CNN算法(RetinaNet+mask head)训练自己的数据集(.h5文件)从而实现图像分割daiding
DL之MaskR-CNN:基于类MaskR-CNN算法(RetinaNet+mask head)利用数据集(resnet50_coco_v0.2.0.h5)实现图像分割(二)
DL之MaskR-CNN:基于类MaskR-CNN算法(RetinaNet+mask head)利用数据集(resnet50_coco_v0.2.0.h5)实现图像分割

