实时计算 Flink
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

37 手游基于 Flink CDC + Hudi 湖仓一体方案实践
介绍了 37 手游为何选择 Flink 作为计算引擎,并如何基于 Flink CDC + Hudi 构建新的湖仓一体方案。

第三届 Apache Flink 极客挑战赛暨 AAIG CUP:Cluster Serving 概况
Cluster Serving 概况以及 Flink 社区的一些集成,帮你更好地应对极客挑战赛。


8大行业场景!最新 Apache Flink 行业案例集火热出炉
Apache Flink 社区携手一线企业重磅推出8大行业实践案例,本书整理了 Flink 社区近一年的行业案例,供大家参考!

Flink Forward Asia 2021 正式启动!议题火热征集中!
FFA 2021 将于 12 月 4-5 日在北京·国家会议中心举办,议题投递日期截止至 10 月 10 日!








PyFlink 开发环境利器:Zeppelin Notebook
在 Zeppelin notebook 里利用 Conda 来创建 Python env 自动部署到 Yarn 集群中。






回顾 | Apache Flink Meetup · 线上(附 PPT 下载)
8.7 线上 Meetup 视频和 PPT 分享来啦~另外,下一期实时数仓 Meetup 议题征集中!





实时数仓王炸组合-实时计算Flink版 + Hologres,《实时数仓入门训练营》课程配套电子书来啦!
阿里云超强专家阵容倾力打造的实时数仓 “王炸组合”,更有合集电子书免费下载哦!架构、场景、实操全方位解读,实时数仓不再是“纸上谈兵”!

实时数仓入门训练营:Hologres性能调优实践
《实时数仓入门训练营》由阿里云研究员王峰、阿里云高级产品专家刘一鸣等实时计算Flink版和 Hologres 的多名技术/产品一线专家齐上阵,合力搭建此次训练营的课程体系,精心打磨课程内容,直击当下同学们所遇到的痛点问题。由浅入深全方位解析实时数仓的架构、场景、以及实操应用,7 门精品课程帮助你 5 天时间从小白成长为大牛!

实时数仓入门训练营:Hologres 数据导入/导出实践
《实时数仓入门训练营》由阿里云研究员王峰、阿里云高级产品专家刘一鸣等实时计算Flink版和 Hologres 的多名技术/产品一线专家齐上阵,合力搭建此次训练营的课程体系,精心打磨课程内容,直击当下同学们所遇到的痛点问题。由浅入深全方位解析实时数仓的架构、场景、以及实操应用,7 门精品课程帮助你 5 天时间从小白成长为大牛!

实时数仓入门训练营:实时数仓助力互联网实时决策和精准营销
《实时数仓入门训练营》由阿里云研究员王峰、阿里云高级产品专家刘一鸣等实时计算Flink版和 Hologres 的多名技术/产品一线专家齐上阵,合力搭建此次训练营的课程体系,精心打磨课程内容,直击当下同学们所遇到的痛点问题。由浅入深全方位解析实时数仓的架构、场景、以及实操应用,7 门精品课程帮助你 5 天时间从小白成长为大牛!

实时数仓入门训练营:基于Hologres的实时数仓新架构
《实时数仓入门训练营》由阿里云研究员王峰、阿里云高级产品专家刘一鸣等实时计算Flink版和 Hologres 的多名技术/产品一线专家齐上阵,合力搭建此次训练营的课程体系,精心打磨课程内容,直击当下同学们所遇到的痛点问题。由浅入深全方位解析实时数仓的架构、场景、以及实操应用,7 门精品课程帮助你 5 天时间从小白成长为大牛!

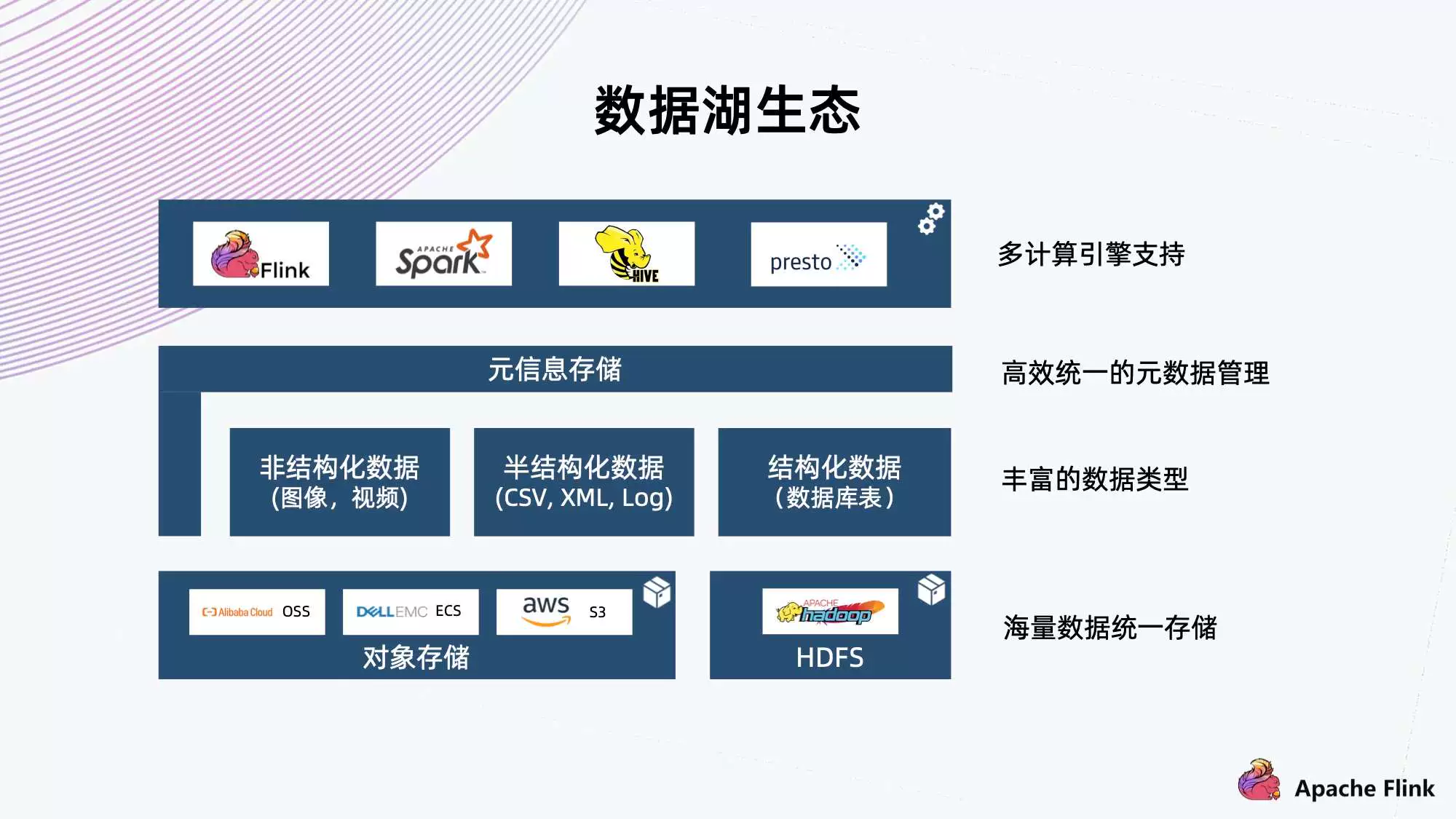

实时数仓入门训练营:基于 Apache Flink + Hologres 的实时推荐系统架构解析
《实时数仓入门训练营》由阿里云研究员王峰、阿里云高级产品专家刘一鸣等实时计算Flink版和 Hologres 的多名技术/产品一线专家齐上阵,合力搭建此次训练营的课程体系,精心打磨课程内容,直击当下同学们所遇到的痛点问题。由浅入深全方位解析实时数仓的架构、场景、以及实操应用,7 门精品课程帮助你 5 天时间从小白成长为大牛!

回顾 | Apache Flink x TiDB Meetup · 北京站(附 PPT 下载)
7.10 日 Apache Flink x TiDB Meetup 视频 & PPT 来啦

实时数仓入门训练营:实时计算 Flink 版 SQL 实践
《实时数仓入门训练营》由阿里云研究员王峰、阿里云高级产品专家刘一鸣等实时计算Flink版和 Hologres 的多名技术/产品一线专家齐上阵,合力搭建此次训练营的课程体系,精心打磨课程内容,直击当下同学们所遇到的痛点问题。由浅入深全方位解析实时数仓的架构、场景、以及实操应用,7 门精品课程帮助你 5 天时间从小白成长为大牛!
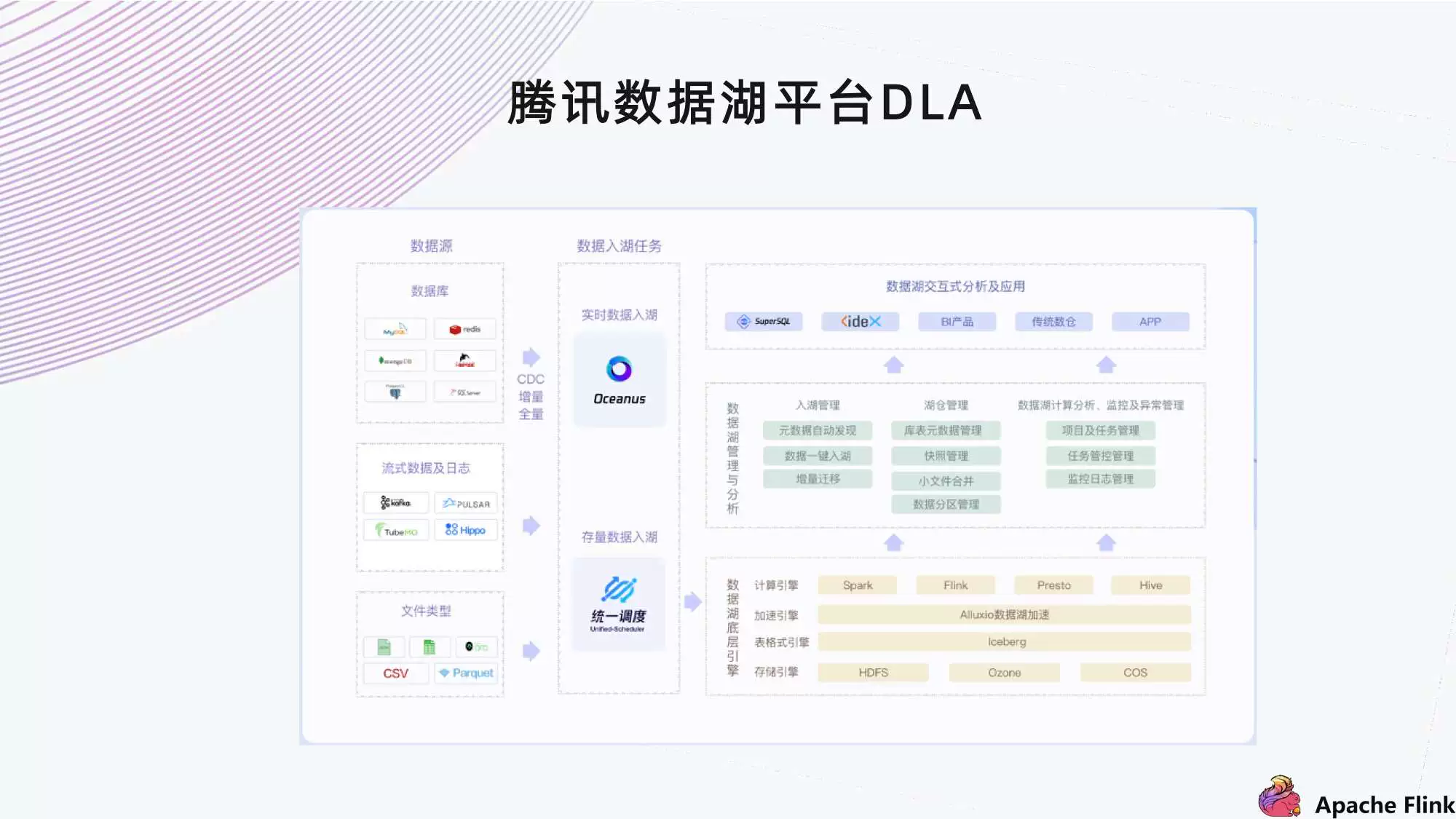
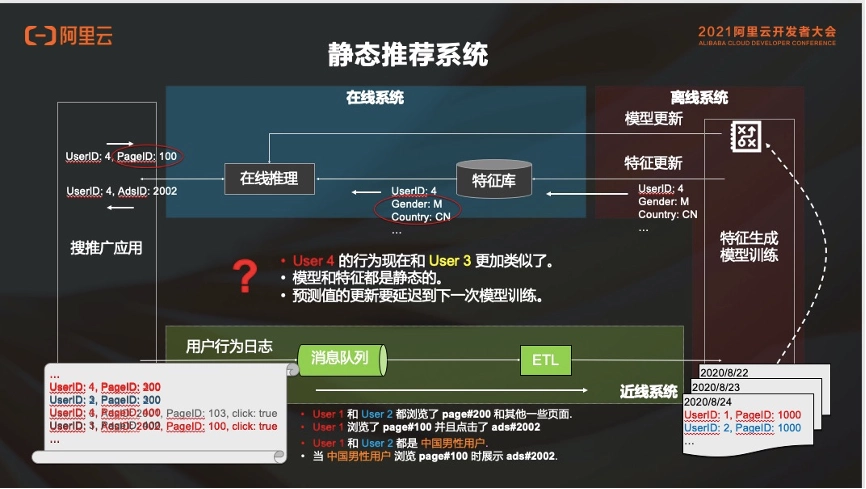
基于实时深度学习的推荐系统架构设计和技术演进
整理自 5 月 29 日 阿里云开发者大会,秦江杰和刘童璇的分享,内容包括实时推荐系统的原理以及什么是实时推荐系统、整体系统的架构及如何在阿里云上面实现,以及关于深度学习的细节介绍
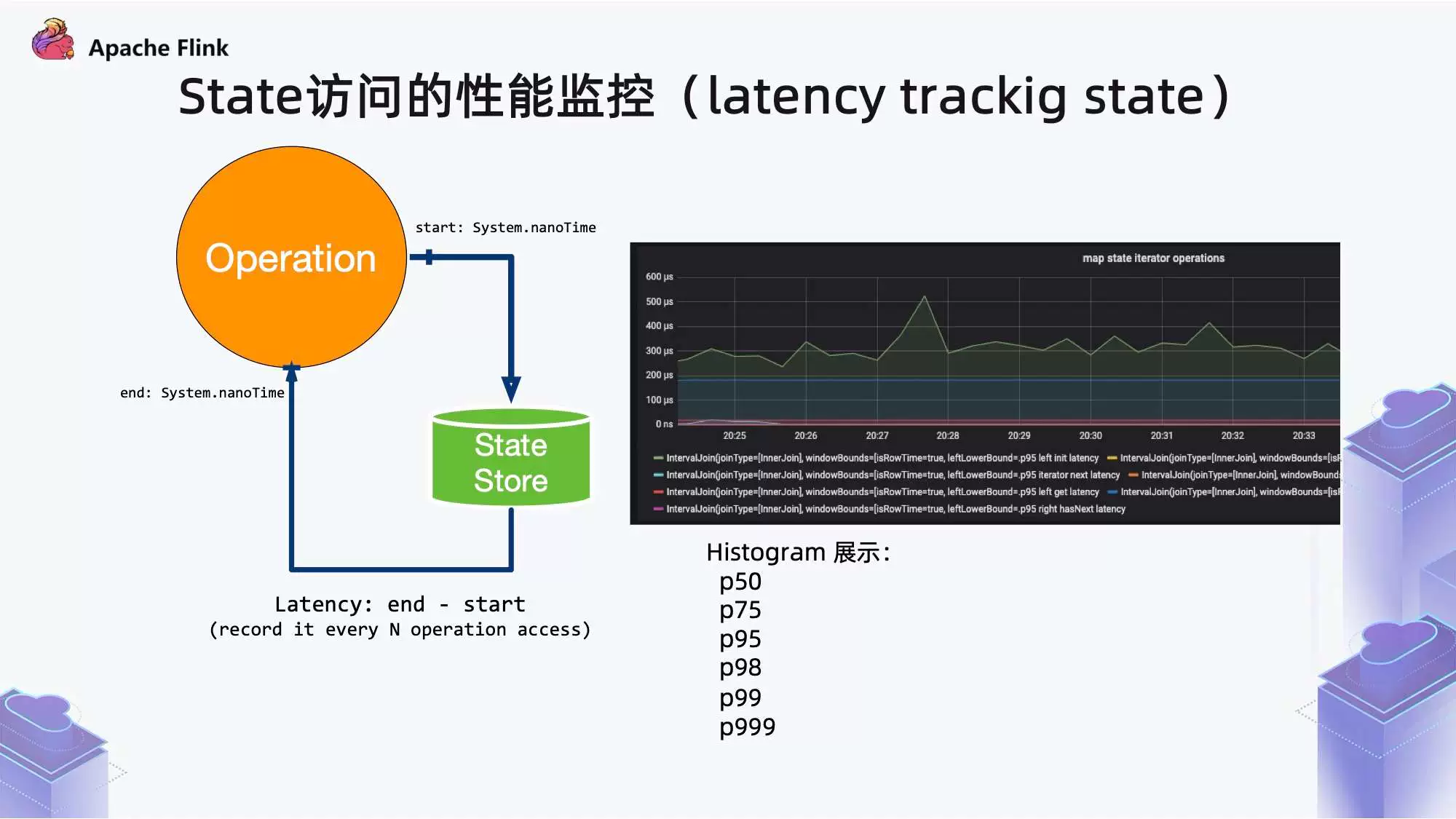
Flink 1.13,State Backend 优化及生产实践分享
Flink 1.13 版本,State Backend 模块就内存管控、访问延迟勘察等方面带来了相关优化与新特性。

Flink 1.13,面向流批一体的运行时与 DataStream API 优化
在 1.13 中,针对流批一体的目标,Flink 优化了大规模作业调度以及批执行模式下网络 Shuffle 的性能,以及在 DataStream API 方面完善有限流作业的退出语义。
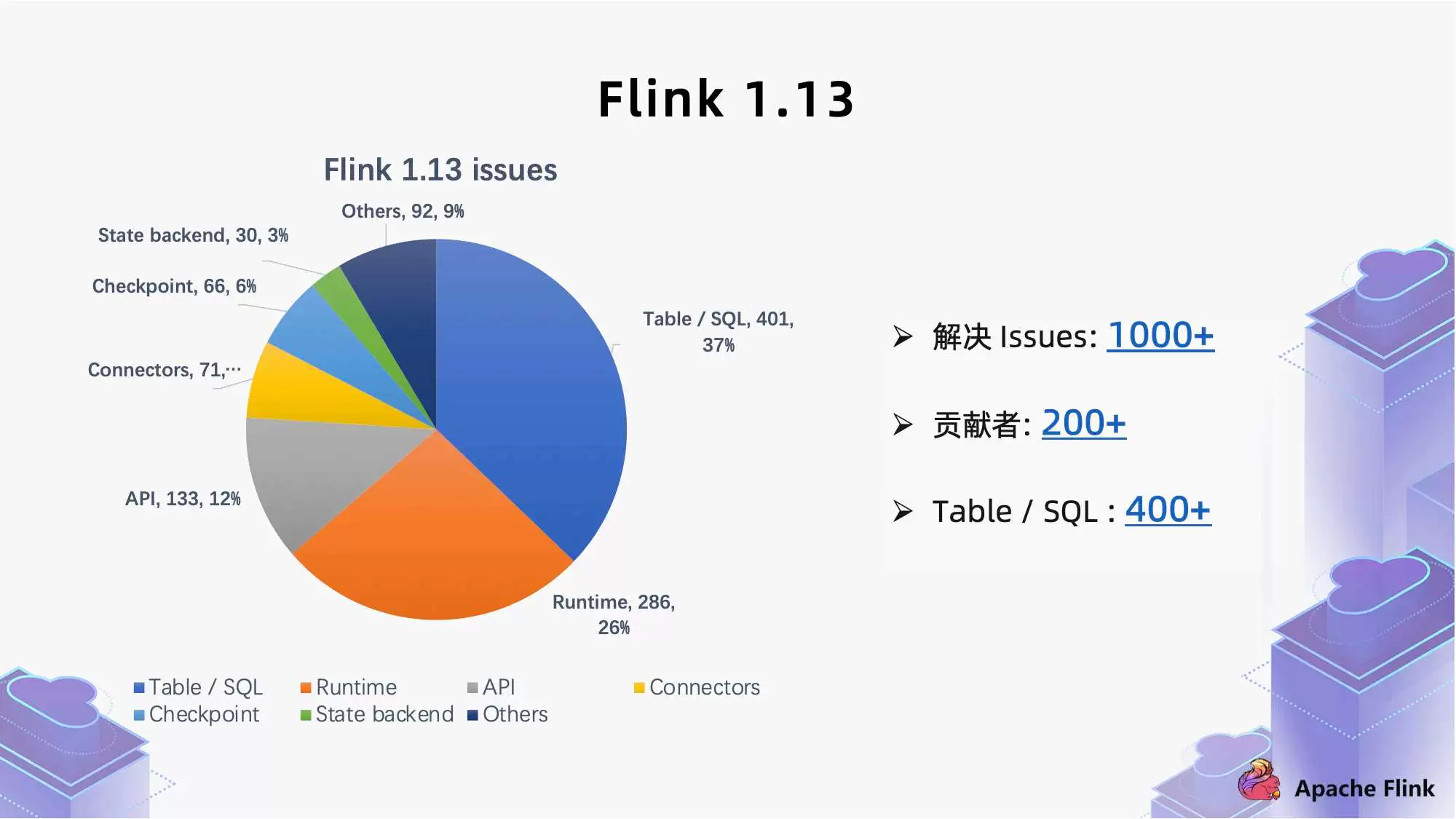
深入解读 Flink SQL 1.13
Apache Flink 社区 5 月 22 日北京站 Meetup 分享内容整理,深入解读 Flink SQL 1.13 中 5 个 FLIP 的实用更新和重要改进。

实时计算正当时!最新电子书轻松get Apache Flink 动向!
本书将助您轻松 Get Apache Flink 1.13 版本最新特征,同时还包含知名厂商多场景 Flink 实战经验,学用一体,干货多多!

Flink 和 Iceberg 如何解决数据入湖面临的挑战
4.17 上海站 Meetup 胡争老师分享内容:数据入湖的挑战有哪些,以及如何用 Flink + Iceberg 解决此类问题。

Flink 中文社区网站 “Flink Learning” 全新上线!文末附最新 Flink 大厂招聘信息~
全新的 Flink 中文社区学习网站 “Flink Learning” 上线啦!


Flink+Hologres助力伊的家电商平台建设新一代实时数仓
Hologres+Flink+DataWorks实时数仓新方案为伊的家业务带来了统一数据、统一服务、统一治理、统一存储的价值,真的做到了开箱即用,所见即所得!

抢报实时数仓入门训练营最后一期!0 元打卡即可免费领取 Flink 马克杯
《实时数仓入门训练营》最后一期,理论与实践的摩擦,概念与案例的碰撞,从 0 到1 快速上手,让自己技能加点,速来报名!