
企业AI中台为什么要把AI工作助理放在第一优先级!
因为员工真正接触到的不是架构图,而是入口;组织真正积累下来的也不是功能清单,而是入口背后的使用数据、路由逻辑、能力目录和持续反馈。这些东西,才决定平台能不能从技术项目变成组织能力。
别再只依赖 ChatGPT 了:多模型协同,才是 AI 项目走向生产的关键一步
本文剖析AI项目落地困局:ChatGPT Agent类应用用户流失率超70%,根源不在模型不够强,而在于单模型架构难以支撑生产环境——稳定性差、成本高、难治理。文章从数据冲击、痛点直击等五维度论证,提出“多模型协同”是破局关键:按场景选模、统一调度、动态兜底,构建可控、可替换、可长期运行的AI系统架构。
工程师思维看透人心?这个“集成框架”可能颠覆了个人成长领域
《内生力量智慧集成系统》是一套专为技术人设计的“自我认知操作系统”,以系统工程思维重构个人成长:用“七力光谱”扫描内在配置,以“阻滞系数”“一致性指数”等指标动态诊断,支持从调优(1.0–2.0)到重构(3.0)、集成(4.0)乃至超越工具(5.0)的全周期演进。它不贴标签,只提供可测量、可干预、可迭代的元认知框架,助你在AI时代成为自身意识系统的架构师。(239字)

推荐一款可以简单快速部署开源AI模型的桌面软件 Doo AI
Doo AI是一款简洁易用的开源AI模型本地部署工具,支持通义千问3/VL、LLaMA3.1等主流HF格式模型。下载即用,扫描→点击“加载”,可以快速、轻松完成部署;纯本地运行,隐私安全;支持文本对话、图像识别、RAG、角色提示词等实用功能。(239字)

RAGEN:RL训练LLM推理新范式!开源强化学习框架让Agent学会多轮决策
RAGEN是一个基于StarPO框架的开源强化学习系统,通过马尔可夫决策过程形式化Agent与环境的交互,支持PPO、GRPO等多种优化算法,显著提升多轮推理训练的稳定性。

开源8B参数全能扩散模型Flex.2-preview:把线稿变商稿,还能边画边改!
Flex.2-preview是Ostris开源的80亿参数文本到图像扩散模型,支持512token长文本输入和多类型控制引导,内置修复功能并兼容主流AI绘画工具链。

AI生成视频告别剪辑拼接!MAGI-1:开源自回归视频生成模型,支持一镜到底的长视频生成
MAGI-1是Sand AI开源的全球首个自回归视频生成大模型,采用创新架构实现高分辨率流畅视频生成,支持无限扩展和精细控制,在物理行为预测方面表现突出。

机器人训练师狂喜!Infinite Mobility:上海AI Lab造物神器1秒生成可动家具,成本只要1分钱
上海AI Lab推出的Infinite Mobility采用程序化生成技术,可高效生成22类高质量可交互物体,单个生成仅需1秒且成本低至0.01元,已应用于机器人仿真训练等领域。

音乐人必看!OpenUtau:开源AI歌声合成神器,快速打造专业级虚拟歌手,中文日文无缝切换
OpenUtau是一款开源的歌声合成工具,兼容UTAU音源库和重采样器,支持多语言界面及预渲染功能,让音乐创作更加高效便捷。

视觉分词器突破天花板!GigaTok:港大字节联手打造3B参数视觉分词器,突破图像生成瓶颈
GigaTok是香港大学与字节跳动联合研发的3B参数视觉分词器,通过语义正则化技术和创新架构设计,解决了图像重建与生成质量间的矛盾,显著提升自回归模型的表示学习能力。

快速生成商业级高清图!SimpleAR:复旦联合字节推出图像生成黑科技,5亿参数秒出高清大图
SimpleAR是复旦大学与字节Seed团队联合研发的自回归图像生成模型,仅用5亿参数即可生成1024×1024分辨率的高质量图像,在GenEval等基准测试中表现优异。

斯坦福黑科技让笔记本GPU也能玩转AI视频生成!FramePack:压缩输入帧上下文长度!仅需6GB显存即可生成高清动画
斯坦福大学推出的FramePack技术通过压缩输入帧上下文长度,解决视频生成中的"遗忘"和"漂移"问题,仅需6GB显存即可在普通笔记本上实时生成高清视频。

AI视频生成也能自动补全!Wan2.1 FLF2V:阿里通义开源14B视频生成模型,用首尾两帧生成过渡动画
万相首尾帧模型是阿里通义开源的14B参数规模视频生成模型,基于DiT架构和高效视频压缩VAE,能够根据首尾帧图像自动生成5秒720p高清视频,支持多种风格变换和细节复刻。

多模态交互3D建模革命!Neural4D 2o:文本+图像一键生成高精度3D内容
Neural4D 2o是DreamTech推出的突破性3D大模型,通过文本、图像、3D和运动数据的联合训练,实现高精度3D生成与智能编辑,为创作者提供全新的多模态交互体验。

多模态模型卷王诞生!InternVL3:上海AI Lab开源78B多模态大模型,支持图文视频全解析!
上海人工智能实验室开源的InternVL3系列多模态大语言模型,通过原生多模态预训练方法实现文本、图像、视频的统一处理,支持从1B到78B共7种参数规模。

AI对话像真人!交交:上海交大推出全球首个口语对话情感大模型,支持多语言与实时音色克隆
上海交通大学推出的交交是全球首个纯学术界自研的口语对话情感大模型,具备多语言交流、方言理解、角色扮演和情感互动等能力,通过创新技术实现端到端语音对话和实时音色克隆。

导演失业预警!Seaweed-7B:字节7B参数模型让剧本自动变电影!20秒长镜头丝滑生成
Seaweed-7B是字节跳动推出的70亿参数视频生成模型,支持从文本、图像或音频生成高质量视频内容,具备长镜头生成、实时渲染等先进特性,通过优化架构显著降低计算成本。

模型手动绑骨3天,AI花3分钟搞定!UniRig:清华开源通用骨骼自动绑定框架,助力3D动画制作
UniRig是清华大学与VAST联合研发的自动骨骼绑定框架,基于自回归模型与交叉注意力机制,支持多样化3D模型的骨骼生成与蒙皮权重预测,其创新的骨骼树标记化技术显著提升动画制作效率。

告别潜在空间的黑箱操作,直接在原始像素空间建模!PixelFlow:港大团队开源像素级文生图模型
香港大学与Adobe联合研发的PixelFlow模型,通过流匹配和多尺度生成技术实现像素级图像生成,在256×256分辨率任务中取得1.98的FID分数,支持端到端训练并突破传统模型对预训练VAE的依赖。

别让创意卡在工具链!MiniMax MCP Server:MiniMax 开源 MCP 服务打通多模态生成能力,视频语音图像一键全搞定
MiniMax MCP Server 是基于模型上下文协议的多模态生成中间件,支持通过文本指令调用视频生成、图像创作、语音合成及声音克隆等能力,兼容主流客户端实现跨平台调用,采用检索增强生成技术保障内容准确性。

开源学习神器把2小时网课压成5分钟脑图!BiliNote:一键转录哔哩哔哩视频,生成结构化学习文档
本文介绍基于FastAPI与React构建的开源视频笔记工具BiliNote,其整合多模态AI技术实现视频内容结构化解析,支持跨平台视频源处理与本地化部署方案,提供从语音转写到智能摘要的全流程自动化能力。

快速切换多种画风!FlexIP:腾讯开源双适配器图像生成框架,精准平衡身份保持与个性化编辑
本文解析腾讯最新开源的FlexIP图像框架,其通过双适配器架构与动态门控机制实现身份保持与个性化编辑的精准平衡,在CLIP-I指标上取得0.873的高分验证了技术突破。

设计师集体破防!UNO:字节跳动创新AI图像生成框架,多个参考主体同框生成,位置/材质/光影完美对齐
UNO是字节跳动开发的AI图像生成框架,通过渐进式跨模态对齐和通用旋转位置嵌入技术,解决了多主体场景下的生成一致性问题。该框架支持单主体特征保持与多主体组合生成,在虚拟试穿、产品设计等领域展现强大泛化能力。

傅利叶开源人形机器人,提供完整的开源套件!Fourier N1:具备23个自由度和3.5米/秒运动能力
傅利叶推出的开源人形机器人N1搭载自研动力系统与多模态交互模块,具备23个自由度和3.5米/秒运动能力,提供完整开源套件助力开发者验证算法。

传统OCR集体阵亡!Versatile-OCR-Program:开源多语言OCR工具,精准解析表格和数学公式等复杂结构
本文解析开源OCR工具Versatile-OCR-Program的技术实现,其基于多模态融合架构实现90%以上识别准确率,支持数学公式与图表的结构化输出,为教育资料数字化提供高效解决方案。

月之暗面开源16B轻量级多模态视觉语言模型!Kimi-VL:推理仅需激活2.8B,支持128K上下文与高分辨率输入
月之暗面开源的Kimi-VL采用混合专家架构,总参数量16B推理时仅激活2.8B,支持128K上下文窗口与高分辨率视觉输入,通过长链推理微调和强化学习实现复杂任务处理能力。

AI图像质感还原堪比专业摄影!Miracle F1:美图WHEE全新AI图像生成模型,支持超写实与多风格生成
美图WHEE推出的Miracle F1采用扩散模型技术,通过精准语义理解和多风格生成能力,可产出具有真实光影质感的专业级图像作品。

从商业海报到二次元插画多风格通吃!HiDream-I1:智象未来开源文生图模型,17亿参数秒出艺术大作
HiDream-I1是智象未来团队推出的开源图像生成模型,采用扩散模型技术和混合专家架构,在图像质量、提示词遵循能力等方面表现优异,支持多种风格生成。

这个AI能把PSD变视频!人物/场景/道具任意组合!SkyReels-A2:昆仑万维推出的可控多元素视频生成框架
SkyReels-A2是昆仑万维推出的创新视频生成框架,通过扩散模型和图像-文本联合嵌入技术,实现多元素精准组合与高质量视频输出。

OpenRouter 推出百万 token 上下文 AI 模型!Quasar Alpha:提供完全免费的 API 服务,同时支持联网搜索和多模态交互
Quasar Alpha 是 OpenRouter 推出的预发布 AI 模型,具备百万级 token 上下文处理能力,在代码生成、指令遵循和低延迟响应方面表现卓越,同时支持联网搜索和多模态交互。

重定义数字人交互!OmniTalker:阿里推出实时多模态说话头像生成框架,音视频实现唇语级同步
阿里巴巴推出的OmniTalker框架通过Thinker-Talker架构实现文本驱动的实时说话头像生成,创新性采用TMRoPE技术确保音视频同步,支持流式多模态输入处理。

OmniCam:浙大联合上海交大推出多模态视频生成框架,虚拟导演打造百万级影视运镜
OmniCam是由浙江大学与上海交通大学联合研发的多模态视频生成框架,通过LLM与视频扩散模型结合实现高质量视频生成,支持文本、轨迹和图像等多种输入模态。

音乐人狂喜!AbletonMCP:让AI帮你写歌,一句话生成专业编曲,Demo级作品秒出
AbletonMCP 是一个开源项目,通过模型上下文协议(MCP)将 Ableton Live 与 Claude AI 连接,实现 AI 辅助音乐制作,支持创建、修改 MIDI 和音频轨道等操作。

AutoGLM沉思:智谱AI推出首个能"边想边干"的自主智能体!深度研究+多模态交互,颠覆传统AI工作模式
AutoGLM沉思是由智谱AI推出的一款开创性AI智能体,它突破性地将深度研究能力与实际操作能力融为一体,实现了AI从被动响应到主动执行的跨越式发展。

QVQ-Max:阿里通义新一代视觉推理模型!再造多模态「全能眼」秒解图文难题
QVQ-Max是阿里通义推出的新一代视觉推理模型,不仅能解析图像视频内容,还能进行深度推理和创意生成,在数学解题、数据分析、穿搭建议等场景展现强大能力。

Cosmos-Reason1:物理常识觉醒!NVIDIA 56B模型让AI懂重力+时空法则
Cosmos-Reason1是NVIDIA推出的多模态大语言模型系列,具备物理常识理解和具身推理能力,支持视频输入和长链思考,可应用于机器人、自动驾驶等场景。
Mureka V6:10语种AI音乐工厂!昆仑万维「声场黑科技」颠覆作曲
昆仑万维推出的Mureka V6 AI音乐创作基座模型,支持10种语言歌词生成和纯音乐创作,通过自研ICL技术实现声场优化,覆盖爵士/电子/流行等多元风格,为音乐爱好者和专业创作者提供高效工具。

Qwen2.5-VL-32B:阿里开源多模态核弹!32B模型吊打自家72B,数学推理封神
阿里巴巴最新开源的Qwen2.5-VL-32B多模态模型,在数学推理、视觉问答等任务中超越前代72B版本,支持图像细粒度理解和复杂逻辑分析,已在HuggingFace开源。

StarVector:图像秒变矢量代码!开源多模态模型让SVG生成告别手绘
StarVector是由ServiceNow Research等机构联合开发的开源多模态视觉语言模型,能够将图像和文本转换为可编辑的SVG矢量图形,支持1B和8B两种规模,在SVG生成任务中表现出色。

Second Me:硅基生命或成现实?如何用AI克隆自己,打造你的AI数字身份!
Second Me 是一个开源AI身份系统,允许用户创建完全私有的个性化AI代理,代表用户的真实自我,支持本地训练和部署,保护用户隐私和数据安全。

SpatialLM:手机视频秒建3D场景!开源空间认知模型颠覆机器人训练
SpatialLM 是群核科技开源的空间理解多模态模型,能够通过普通手机拍摄的视频重建 3D 场景布局,赋予机器人类似人类的空间认知能力,适用于具身智能训练、自动导航、AR/VR 等领域。

Dify-Plus:企业级AI管理核弹!开源方案吊打SaaS,额度+密钥+鉴权系统全面集成
Dify-Plus 是基于 Dify 二次开发的企业级增强版项目,新增用户额度、密钥管理、Web 登录鉴权等功能,优化权限管理,适合企业场景使用。
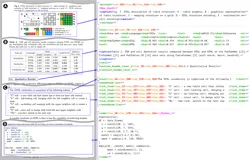
SmolDocling:256M多模态小模型秒转文档!开源OCR效率提升10倍
SmolDocling 是一款轻量级的多模态文档处理模型,能够将图像文档高效转换为结构化文本,支持文本、公式、图表等多种元素识别,适用于学术论文、技术报告等多类型文档。
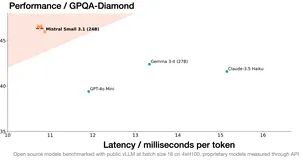
Mistral Small 3.1:240亿参数多模态黑马!128k长文本+图像分析,推理速度150token/秒
Mistral Small 3.1 是 Mistral AI 开源的多模态人工智能模型,具备 240 亿参数,支持文本和图像处理,推理速度快,适合多种应用场景。

OpenBioMed:开源生物医学AI革命!20+工具链破解药物研发「死亡谷」
OpenBioMed 是清华大学智能产业研究院(AIR)和水木分子共同推出的开源平台,专注于 AI 驱动的生物医学研究,提供多模态数据处理、丰富的预训练模型和多样化的计算工具,助力药物研发、精准医疗和多模态理解。

Hunyuan3D 2.0:腾讯混元开源3D生成大模型!图生/文生秒建高精度模型,细节纹理自动合成
Hunyuan3D 2.0 是腾讯推出的大规模 3D 资产生成系统,专注于从文本和图像生成高分辨率的 3D 模型,支持几何生成和纹理合成。

昆仑万维开源 Skywork R1V:开源多模态推理核弹!视觉链式分析超越人类专家
Skywork R1V 是昆仑万维开源的多模态思维链推理模型,具备强大的视觉链式推理能力,能够在多个权威基准测试中取得领先成绩,推动多模态推理模型的发展。
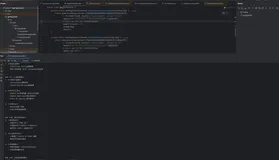
JAVA接入DeepSeek大模型接口开发---阿里云的百炼模型
随着大模型的越来越盛行,现在很多企业开始接入大模型的接口,今天我从java开发角度来写一个demo的示例,用于接入DeepSeek大模型,国内的大模型有很多的接入渠道,今天主要介绍下阿里云的百炼模型,因为这个模型是免费的,只要注册一个账户,就会免费送百万的token进行学习,今天就从一个简单的可以执行的示例开始进行介绍,希望可以分享给各位正在学习的同学们。

MedRAG:医学AI革命!知识图谱+四层诊断,临床准确率飙升11.32%
MedRAG是南洋理工大学推出的医学诊断模型,结合知识图谱与大语言模型,提升诊断准确率11.32%,支持多模态输入与智能提问,适用于急诊、慢性病管理等多种场景。

AudioX:颠覆创作!多模态AI一键生成电影级音效+配乐,耳朵的终极盛宴
AudioX 是香港科技大学和月之暗面联合推出的扩散变换器模型,能够从文本、视频、图像等多种模态生成高质量音频和音乐,具备强大的跨模态学习能力和泛化能力。





