
在做微调语音识别模型的时候,max_token_length设置为3000,打印出的log里面显示:total_num of samplers: 157112, ../../../data/list/train.jsonl,这个总的样本数是这么计算的:157112=每轮的总step GPU个数 batch,现在有一个问题是我的总样本数是178460,而且每条音频不超过30秒,我也已经把max_token_length设置为6000了,max_source_length和max_target_length也设置为3000了,结果微调的时候总样本数还是157112条,modelscope-funasr还有两万多条数据是怎么被过滤掉的?
过滤逻辑在这里:https://github.com/alibaba-damo-academy/FunASR/blob/main/funasr/datasets/audio_datasets/index_ds.py#L97 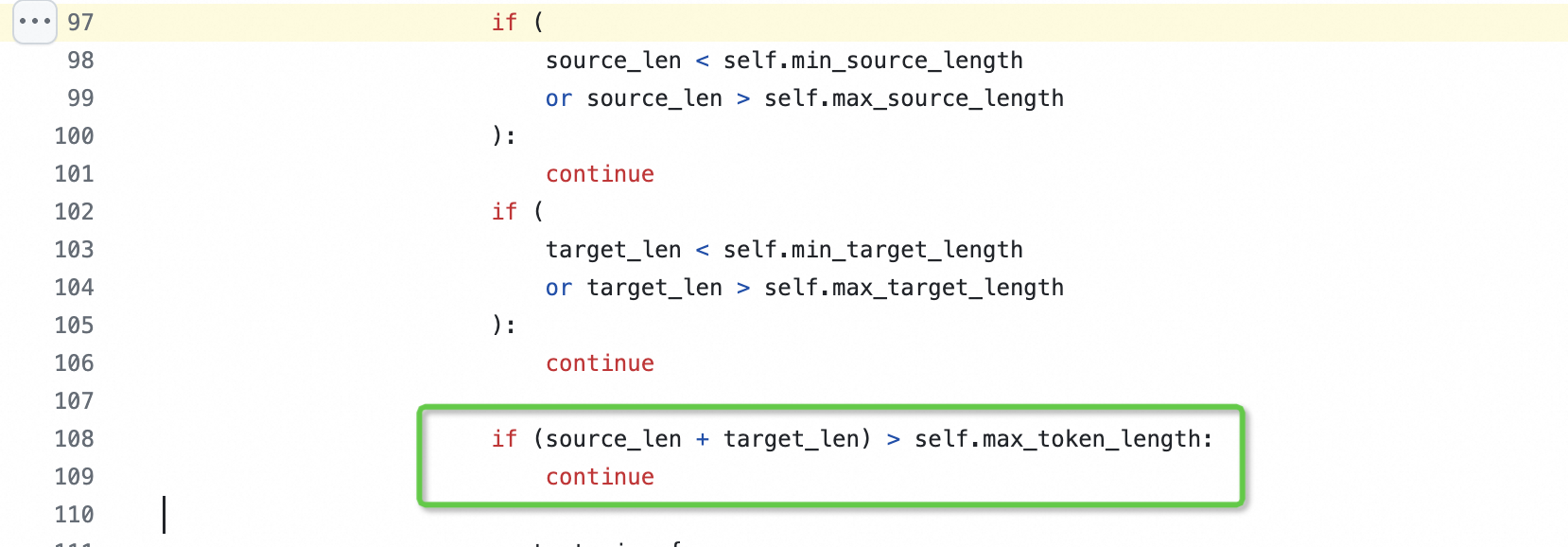
注意这里,是音频+文本 此回答整理自钉群“modelscope-funasr社区交流”
