
export DASHSCOPE_API_KEY=YOUR_DASHSCOPE_API_KEY
需要使用您的API-KEY替换示例中的 YOUR_DASHSCOPE_API_KEY ,代码才能正常运行。
示例代码需要满足:
python sdk version: dashscope>=1.10.0
java sdk version: >=2.5.0
# For prerequisites running the following sample, visit https://help.aliyun.com/document_detail/611472.html
import pyaudio
import dashscope
from dashscope.audio.asr import (Recognition, RecognitionCallback,
RecognitionResult)
dashscope.api_key='<your-dashscope-api-key>'
mic = None
stream = None
class Callback(RecognitionCallback):
def on_open(self) -> None:
global mic
global stream
print('RecognitionCallback open.')
mic = pyaudio.PyAudio()
stream = mic.open(format=pyaudio.paInt16,
channels=1,
rate=16000,
input=True)
def on_close(self) -> None:
global mic
global stream
print('RecognitionCallback close.')
stream.stop_stream()
stream.close()
mic.terminate()
stream = None
mic = None
def on_event(self, result: RecognitionResult) -> None:
print('RecognitionCallback sentence: ', result.get_sentence())
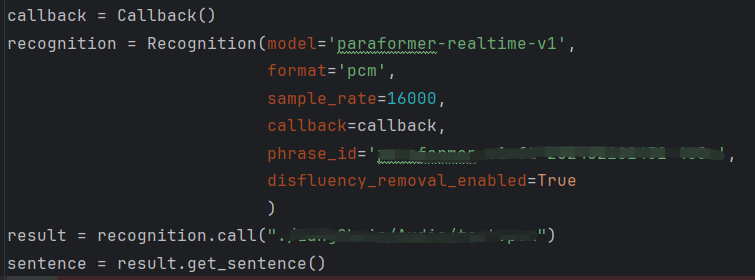
callback = Callback()
recognition = Recognition(model='paraformer-realtime-v1',
format='pcm',
sample_rate=16000,
callback=callback)
recognition.start()
while True:
if stream:
data = stream.read(3200, exception_on_overflow = False)
recognition.send_audio_frame(data)
else:
break
recognition.stop()
package com.alibaba.dashscope.sample.recognition.quickstart;
import com.alibaba.dashscope.audio.asr.recognition.Recognition;
import com.alibaba.dashscope.audio.asr.recognition.RecognitionParam;
import io.reactivex.BackpressureStrategy;
import io.reactivex.Flowable;
import java.nio.ByteBuffer;
import javax.sound.sampled.AudioFormat;
import javax.sound.sampled.AudioSystem;
import javax.sound.sampled.TargetDataLine;
public class Main {
public static void main(String[] args) {
// 创建一个Flowable<ByteBuffer>
Flowable<ByteBuffer> audioSource =
Flowable.create(
emitter -> {
new Thread(
() -> {
try {
// 创建音频格式
AudioFormat audioFormat = new AudioFormat(16000, 16, 1, true, false);
// 根据格式匹配默认录音设备
TargetDataLine targetDataLine =
AudioSystem.getTargetDataLine(audioFormat);
targetDataLine.open(audioFormat);
// 开始录音
targetDataLine.start();
ByteBuffer buffer = ByteBuffer.allocate(1024);
long start = System.currentTimeMillis();
// 录音30s并进行实时转写
while (System.currentTimeMillis() - start < 300000) {
int read = targetDataLine.read(buffer.array(), 0, buffer.capacity());
if (read > 0) {
buffer.limit(read);
// 将录音音频数据发送给流式识别服务
emitter.onNext(buffer);
buffer = ByteBuffer.allocate(1024);
// 录音速率有限,防止cpu占用过高,休眠一小会儿
Thread.sleep(20);
}
}
// 通知结束转写
emitter.onComplete();
} catch (Exception e) {
emitter.onError(e);
}
})
.start();
},
BackpressureStrategy.BUFFER);
// 创建Recognizer
Recognition recognizer = new Recognition();
// 创建RecognitionParam,audioFrames参数中传入上面创建的Flowable<ByteBuffer>
RecognitionParam param =
RecognitionParam.builder()
.model("paraformer-realtime-v1")
.format("pcm")
.sampleRate(16000)
.apiKey("your-dashscope-api-key")
.build();
// 流式调用接口
recognizer
.streamCall(param, audioSource)
// 调用Flowable的subscribe方法订阅结果
.blockingForEach(
result -> {
// 打印最终结果
if (result.isSentenceEnd()) {
System.out.println("Fix:" + result.getSentence().getText());
} else {
System.out.println("Result:" + result.getSentence().getText());
}
});
System.exit(0);
}
}