
ModelScope中sft的时候,只能保存第一个checkpoint,之后就会报超时错误,是哪里的问题呢?这个是启动sft的脚本:
nproc_per_node=4
CUDA_VISIBLE_DEVICES=0,1,2,3 \
torchrun \
--nproc_per_node=$nproc_per_node \
--master_port 29500 \
llm_sft.py \
--model_type qwen-7b \
--sft_type lora \
--output_dir runs \
--dataset /path/to/train_20240430_02.jsonl \
--dataset_sample -1 \
--max_length 2048 \
--lora_rank 8 \
--lora_alpha 32 \
--lora_dropout_p 0.1 \
--batch_size 2 \
--learning_rate 1e-4 \
--eval_steps 10 \
--save_steps 10 \
--save_total_limit 100 \
--logging_steps 10 \
--use_flash_attn false \
--ddp_backend nccl \
--gradient_accumulation_steps $(expr 16 / $nproc_per_node) \
--deepspeed 'scripts/train/ds_stage_2.json' \
这个是错误信息:
[INFO:swift] Saving model checkpoint to runs/qwen-7b/v3-20240501-223843/checkpoint-10
[rank3]:[E ProcessGroupNCCL.cpp:563] [Rank 3] Watchdog caught collective operation timeout: WorkNCCL(SeqNum=11, OpType=ALLREDUCE, NumelIn=1, NumelOut=1, Timeout(ms)=600000) ran for 600069 milliseconds before timing out.
[rank2]:[E ProcessGroupNCCL.cpp:563] [Rank 2] Watchdog caught collective operation timeout: WorkNCCL(SeqNum=11, OpType=ALLREDUCE, NumelIn=1, NumelOut=1, Timeout(ms)=600000) ran for 600023 milliseconds before timing out.
[rank1]:[E ProcessGroupNCCL.cpp:563] [Rank 1] Watchdog caught collective operation timeout: WorkNCCL(SeqNum=11, OpType=ALLREDUCE, NumelIn=1, NumelOut=1, Timeout(ms)=600000) ran for 600060 milliseconds before timing out.
[rank0]:[E ProcessGroupNCCL.cpp:563] [Rank 0] Watchdog caught collective operation timeout: WorkNCCL(SeqNum=13, OpType=ALLREDUCE, NumelIn=20, NumelOut=20, Timeout(ms)=600000) ran for 600063 milliseconds before timing out.
[rank3]:[E ProcessGroupNCCL.cpp:1537] [PG 0 Rank 3] Timeout at NCCL work: 11, last enqueued NCCL work: 11, last completed NCCL work: 10.
[rank3]:[E ProcessGroupNCCL.cpp:577] [Rank 3] Some NCCL operations have failed or timed out. Due to the asynchronous nature of CUDA kernels, subsequent GPU operations might run on corrupted/incomplete data.
[rank3]:[E ProcessGroupNCCL.cpp:583] [Rank 3] To avoid data inconsistency, we are taking the entire process down.
[rank3]:[E ProcessGroupNCCL.cpp:1414] [PG 0 Rank 3] Process group watchdog thread terminated with exception: [Rank 3] Watchdog caught collective operation timeout: WorkNCCL(SeqNum=11, OpType=ALLREDUCE, NumelIn=1, NumelOut=1, Timeout(ms)=600000) ran for 600069 milliseconds before timing out.
Exception raised from checkTimeout at ../torch/csrc/distributed/c10d/ProcessGroupNCCL.cpp:565 (most recent call first):
frame #0: c10::Error::Error(c10::SourceLocation, std::string) + 0x57 (0x7f1f7ad7a897 in /data1/zhangyl/miniconda3/envs/ms-agent-gh/lib/python3.10/site-packages/torch/lib/libc10.so)
frame #1: c10d::ProcessGroupNCCL::WorkNCCL::checkTimeout(std::optional > >) + 0x1d2 (0x7f1f2ea671b2 in /data1/zhangyl/miniconda3/envs/ms-agent-gh/lib/python3.10/site-packages/torch/lib/libtorch_cuda.so)
frame #2: c10d::ProcessGroupNCCL::watchdogHandler() + 0x1a0 (0x7f1f2ea6bfd0 in /data1/zhangyl/miniconda3/envs/ms-agent-gh/lib/python3.10/site-packages/torch/lib/libtorch_cuda.so)
frame #3: c10d::ProcessGroupNCCL::ncclCommWatchdog() + 0x10c (0x7f1f2ea6d31c in /data1/zhangyl/miniconda3/envs/ms-agent-gh/lib/python3.10/site-packages/torch/lib/libtorch_cuda.so)
frame #4: + 0xdbbf4 (0x7f1f7a4c7bf4 in /data1/zhangyl/miniconda3/envs/ms-agent-gh/bin/../lib/libstdc++.so.6)
frame #5: + 0x94ac3 (0x7f1f7bc41ac3 in /lib/x86_64-linux-gnu/libc.so.6)
frame #6: + 0x126850 (0x7f1f7bcd3850 in /lib/x86_64-linux-gnu/libc.so.6)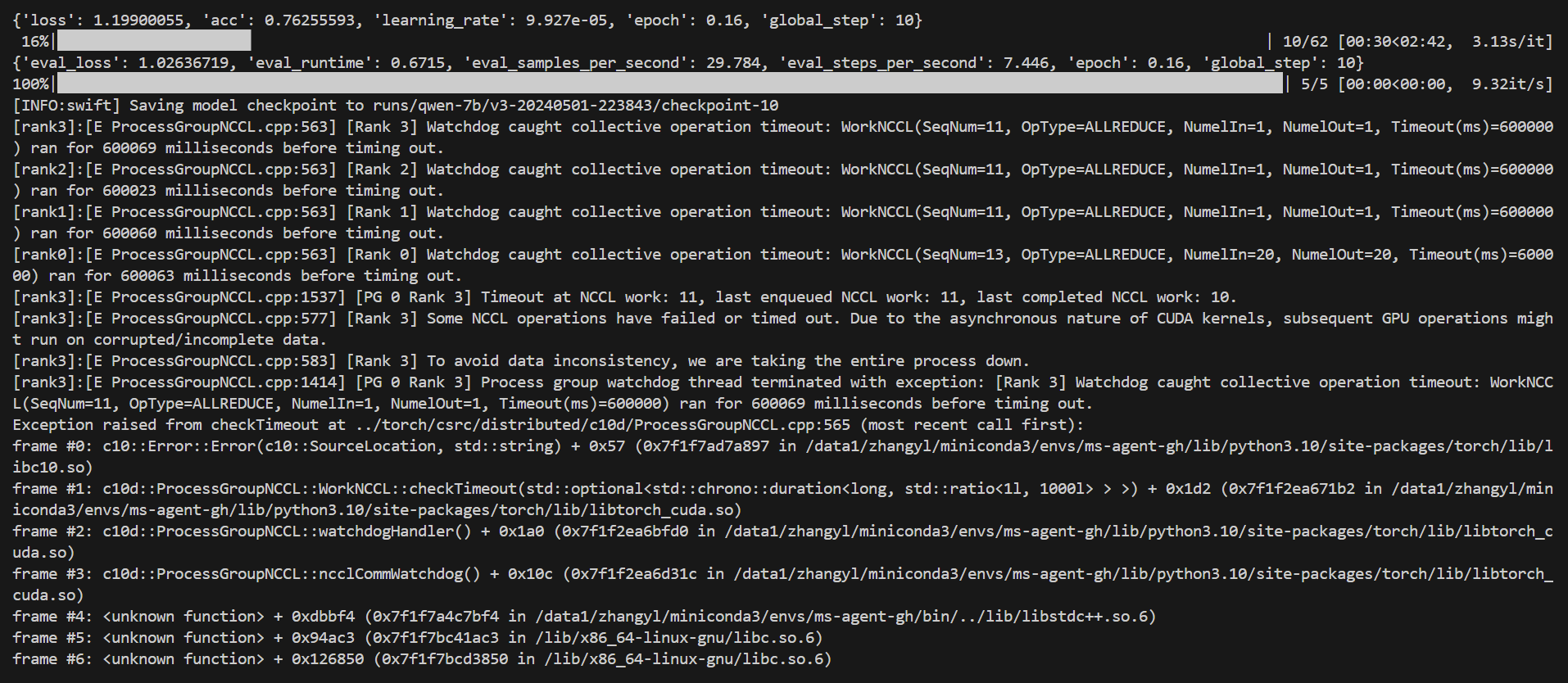
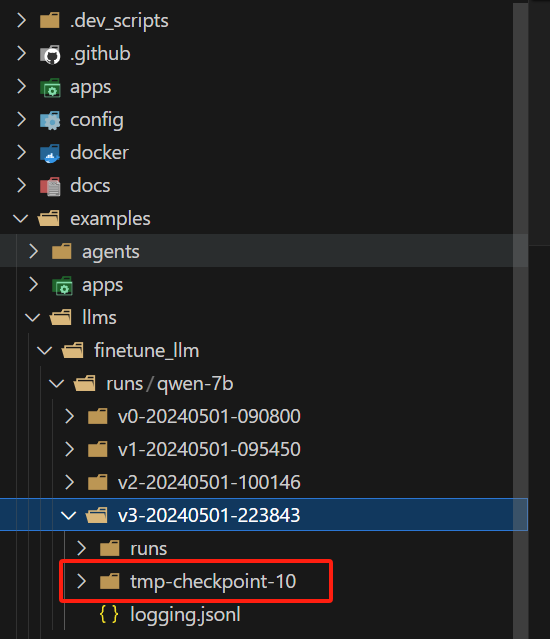
这里成功保存了一个 checkpoint
参考:
https://developer.aliyun.com/article/1486527?spm=a2c6h.17735062.detail.32.5b2a1406jjpzxD ,此回答整理自钉群“魔搭ModelScope开发者联盟群 ①”
ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!欢迎加入技术交流群:微信公众号:魔搭ModelScope社区,钉钉答疑群:44837352
