
nproc_per_node=1
CUDA_VISIBLE_DEVICES=0,1,2,3 \
torchrun \
--nproc_per_node=$nproc_per_node \
--master_port 29500 \
llm_sft.py \
--model_type modelscope-agent-7b \
--sft_type lora \
--output_dir runs \
--dataset dataset.jsonl \
--dataset_sample -1 \
--num_train_epochs 3 \
--dataset_test_size 0.02 \
--max_length 2048 \
--dtype bf16 \
--lora_rank 8 \
--lora_alpha 32 \
--lora_dropout_p 0.01 \
--batch_size 1 \
--learning_rate 1e-4 \
--eval_steps 1 \
--save_steps 1 \
--save_total_limit 2 \
--logging_steps 20 \
--use_flash_attn true \
--ddp_backend nccl \
--gradient_accumulation_steps $(expr 16 / $nproc_per_node) \ModelScope中 我自己的dataset.jsonl数据量少,一千条左右,我设的参数如上,推理好像没学到特征,能帮我看下吗?报错,--lora_target_modules ALL这个参数,要和其他参数一起调整吗?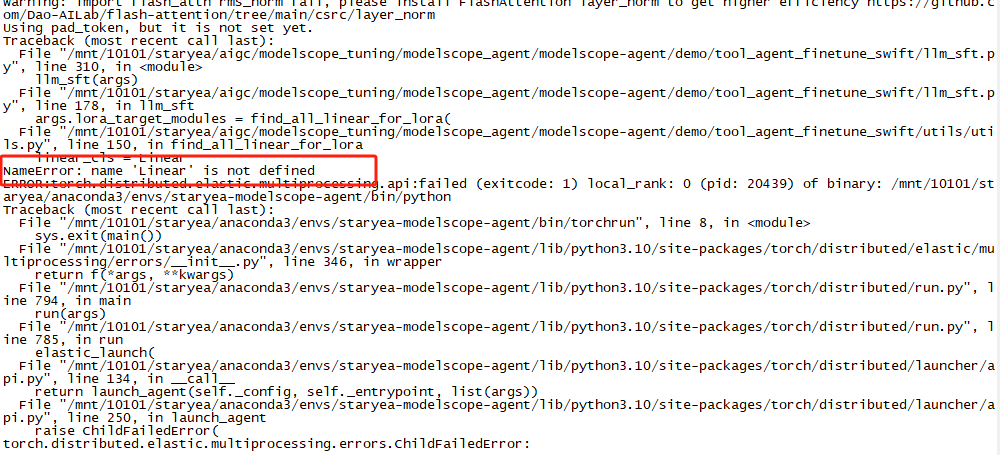
pip show ms-swift看下。--lora_target_modules ALL加个这个试试。看下这个文档,
https://github.com/modelscope/swift/blob/main/docs/source/LLM/Agent%E5%BE%AE%E8%B0%83%E6%9C%80%E4%BD%B3%E5%AE%9E%E8%B7%B5.md
。此回答来自钉群魔搭ModelScope开发者联盟群 ①。
ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!欢迎加入技术交流群:微信公众号:魔搭ModelScope社区,钉钉答疑群:44837352
