
modelscope-funasr微调时 数据量大了 当一个batch处理不完的时候 会有这个报错,怎么解决?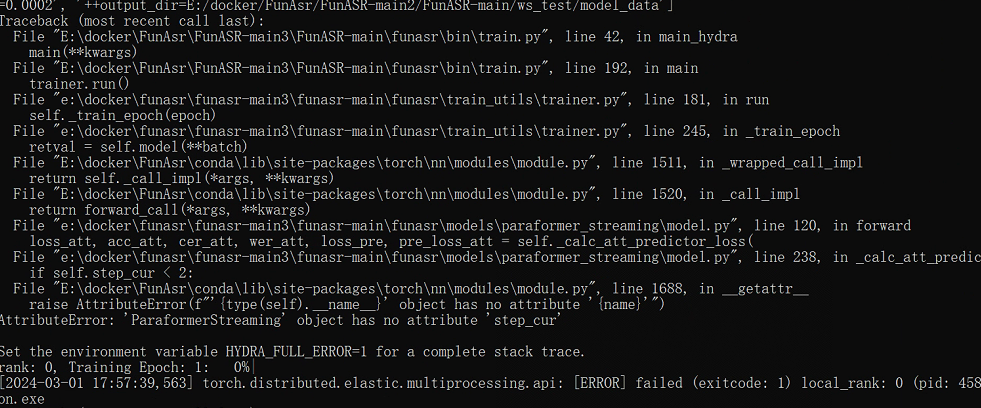
我跑的是 iic/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-online 这个模型
当ModelScope-FunASR在微调过程中遇到数据量过大,导致一个batch处理不完时报错的情况,可以考虑以下方法来解决:
总的来说,解决这类问题需要根据具体情况进行调整和优化,可能需要一些实验和尝试才能找到最佳解决方案。

