有人用minio作为statebackend吗?flink-conf.yml怎么配置的,麻烦给截个图
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
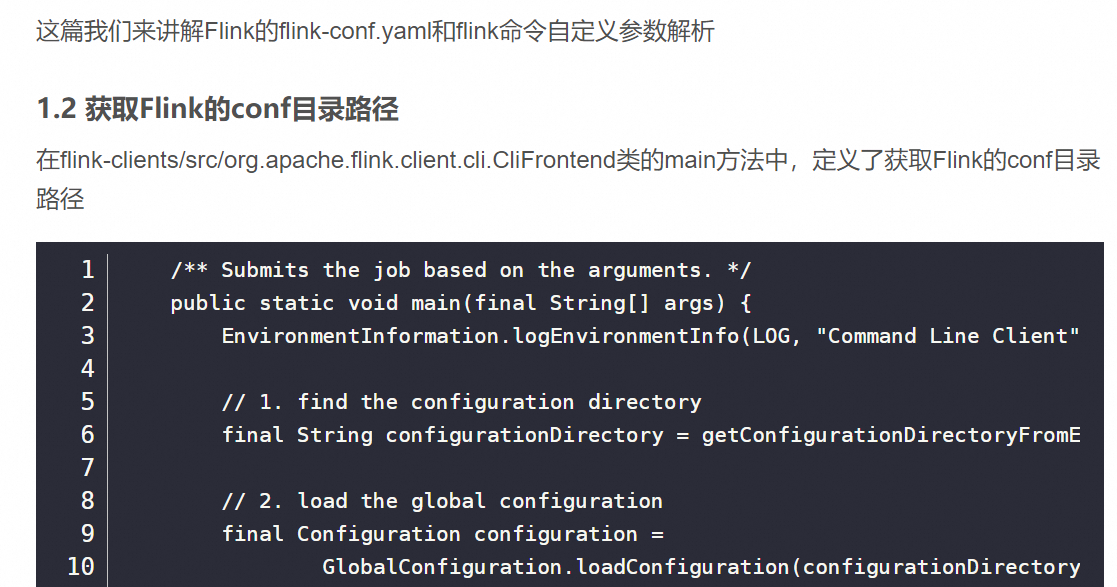
确实有人使用MinIO作为Flink的state backend。在配置Flink以使用MinIO作为其状态后端时,你需要确保已经在Flink的配置文件flink-conf.yaml中进行了适当的设置。
首先,flink-conf.yaml文件是Flink的配置文件,用于设置Flink集群的各种参数。在配置文件中,你需要指定JobManager的地址和端口号,以及其他相关的配置,如JVM堆大小、任务槽的数量等。
然而,关于具体如何在flink-conf.yaml中配置MinIO作为状态后端,Flink的官方文档并没有直接提供详细的步骤。这是因为Flink本身并不直接支持MinIO作为其状态后端,但你可以通过使用兼容S3的文件系统库来实现这一点。
在配置过程中,你可能需要设置以下参数:
state.backend.fs.s3.endpoint: 指定MinIO服务器的URL。
state.backend.fs.s3.access-key: 你的MinIO访问键。
state.backend.fs.s3.secret-key: 你的MinIO秘密键。
state.backend.fs.s3.bucket: 你希望Flink使用的MinIO存储桶的名称。
请注意,这些参数可能会因Flink版本和所使用的S3文件系统库的不同而有所变化。
另外,你还需要确保已经在Flink的类路径中包含了适当的S3文件系统库,以便Flink能够与MinIO进行通信。
总的来说,虽然Flink并不直接支持MinIO作为其状态后端,但通过一些额外的配置和库的使用,你仍然可以实现这一目标。然而,由于这可能需要一些额外的工作和调试,因此建议你在开始之前先熟悉Flink和MinIO的相关文档和社区资源。
是的,有人使用MinIO作为Flink的StateBackend。以下是一个示例的Flink-conf.yml配置文件,用于使用MinIO作为StateBackend:
state.backend: filesystem
state.backend.fs.dir: hdfs://your-hdfs-cluster/flink/checkpoint
state.backend.rocksdb.localdir: "/var/lib/flink/rocksdb"
state.checkpoints.dir: hdfs://your-hdfs-cluster/flink/checkpoints
请注意,上述配置文件中的示例仅适用于使用HDFS作为存储系统的情况。如果你想使用MinIO作为StateBackend,你需要将配置文件中的相关路径和参数进行相应的更改。具体更改方式取决于你的MinIO配置和部署方式。
此外,确保在Flink的classpath中包含MinIO客户端的JAR文件,以便Flink能够与MinIO进行通信。
配置flink-conf.yaml:
state.backend: filesystem (or rocksdb)
state.checkpoints.dir: s3://state/checkpoint
s3.endpoint: http://${ip}:9000
s3.path.style.access: true
s3.access-key: root
s3.secret-key: 12345678
flink代码摘要
public class S3CheckpointKakfa {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(15000, CheckpointingMode.EXACTLY_ONCE);
env.setRestartStrategy(RestartStrategies.noRestart());
CheckpointConfig checkpointConfig = env.getCheckpointConfig();
checkpointConfig.setMaxConcurrentCheckpoints(3);
checkpointConfig.setMinPauseBetweenCheckpoints(3000);
checkpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<String>("mytest"
, new SimpleStringSchema(Charset.defaultCharset())
, consumerConfig());
SingleOutputStreamOperator<String> source = env.addSource(consumer).uid("111").setParallelism(2).filter(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return !StringUtils.isNullOrWhitespaceOnly(value);
}
}).setParallelism(1);
source.addSink(new FlinkKafkaProducer<String>("target", new KafkaSerializationSchema<String>() {
@Override
public ProducerRecord<byte[], byte[]> serialize(String element, @Nullable Long timestamp) {
return new ProducerRecord<>("target", element.getBytes());
}
}, producerConfig(), FlinkKafkaProducer.Semantic.EXACTLY_ONCE, 3)).uid("222").setParallelism(3);
env.execute("s3 test");
}
}
打包 拷贝至容器内部,执行:
docker-compose exec jobmanager bin/flink run -c kafka.S3CheckpointKakfa flink-java-1.0.jar
——参考链接。
使用Minio作为Flink的State Backend。配置文件flink-conf.yml用于定义Flink的配置参数,下面是配置Minio作为State Backend的示例配置:
state.backend: filesystem
state.backend.fs.checkpointdir: s3://bucket-name/flink-checkpoints
state.checkpoints.dir: s3://bucket-name/flink-checkpoints
state.checkpoints.aligned: true
state.savepoints.dir: s3://bucket-name/flink-savepoints
state.backend.fs.s3.endpoint: https://s3.amazonaws.com
state.backend.fs.s3.access-key: access-key
state.backend.fs.s3.secret-key: secret-key
上述配置中使用了Minio作为S3对象存储系统的替代方案。根据你的实际情况,需要将s3://bucket-name替换为你的Minio桶名称,access-key和secret-key替换为你的Minio访问密钥。
另外,如果你使用的是自定义的Minio部署,需要根据实际情况修改state.backend.fs.s3.endpoint参数为你的Minio服务的URL。
可以使用 MinIO 作为 Flink 的状态后端(state backend)。MinIO 是一种开源的对象存储服务,与 Amazon S3 兼容,并且可以轻松部署在本地环境中。
要将 MinIO 配置为 Flink 的状态后端,需要进行以下步骤:
下载和安装 MinIO。根据官方文档进行安装和配置。
创建一个新的存储桶。在 MinIO 中,对象存储需要以存储桶(bucket)的形式进行组织。可以使用 MinIO 客户端或 Web 界面创建一个新的存储桶,并记下其名称和访问密钥(Access Key)和密码(Secret Key)。
在 Flink 的配置文件中配置 MinIO 作为状态后端。可以使用以下配置项来配置 MinIO:
state.backend: filesystem
state.backend.fs.checkpointdir: s3a:///
state.backend.fs.s3a.access-key:
state.backend.fs.s3a.secret-key:
state.backend.fs.s3a.endpoint:
其中, 是之前创建的 MinIO 存储桶的名称, 是 Flink 检查点保存的目录名, 和 是 MinIO 访问的密钥和密码, 是 MinIO 的地址和端口号,例如 http://localhost:9000。
请注意,上述配置中使用了 s3a 协议来访问 MinIO,这是因为 MinIO 兼容 Amazon S3 API。同时,需要将 Hadoop 的 hadoop-aws 和 aws-java-sdk-bundle 两个依赖项添加到 Flink 的类路径中,以支持 S3 文件系统。
flink-conf.yaml:
env.java.opts: "-Djava.library.path=/path/to/hadoop/native/lib -Dorg.apache.flink.shaded.hadoop3.com.google.inject.internal.cglib.core.$ReflectUtils$1=org.apache.flink.shaded.asm.$ClassWriter_"
blob.server.port: 6124
blob.storage.directory: /data/flink/blob
state.backend: filesystem
state.checkpoints.dir: hdfs://hadoop-master:8020/flink/checkpoints
state.backend.fs.checkpointdir: s3a:///
state.backend.fs.s3a.access-key:
state.backend.fs.s3a.secret-key:
state.backend.fs.s3a.endpoint:
state.backend.fs.s3a.path.style.access: true
flink-conf.yaml:
env.java.opts: "-Djava.library.path=/path/to/hadoop/native/lib -Dorg.apache.flink.shaded.hadoop3.com.google.inject.internal.cglib.core.$ReflectUtils$1=org.apache.flink.shaded.asm.$ClassWriter_"
blob.server.port: 6124
blob.storage.directory: /data/flink/blob
state.backend: filesystem
state.checkpoints.dir: hdfs://hadoop-master:8020/flink/checkpoints
state.backend.fs.checkpointdir: s3a:///
state.backend.fs.s3a.access-key:
state.backend.fs.s3a.secret-key:
state.backend.fs.s3a.endpoint:
state.backend.fs.s3a.path.style.access: true
flink-conf.yaml:
env.java.opts: "-Djava.library.path=/path/to/hadoop/native/lib -Dorg.apache.flink.shaded.hadoop3.com.google.inject.internal.cglib.core.$ReflectUtils$1=org.apache.flink.shaded.asm.$ClassWriter_"
blob.server.port: 6124
blob.storage.directory: /data/flink/blob
state.backend: filesystem
state.checkpoints.dir: hdfs://hadoop-master:8020/flink/checkpoints
state.backend.fs.checkpointdir: s3a:///
state.backend.fs.s3a.access-key:
state.backend.fs.s3a.secret-key:
state.backend.fs.s3a.endpoint:
state.backend.fs.s3a.path.style.access: true
启动 Flink 程序并测试。在启动 Flink 程序之前,请确保 MinIO 服务已经启动,并且可以正常访问。启动 Flink 程序后,它将使用 MinIO 作为状态后端,并将检查点保存到指定的存储桶中。可以通过对输入数据进行一些操作来测试 Flink 的状态后端是否正常工作。
请注意,在使用 MinIO 作为状态后端时,需要考虑到网络延迟和带宽等因素对性能的影响。另外,还需要进行充分的测试和评估,以确保 MinIO 可以满足应用程序的实时性能要求。
截至我 statebackend。Flink的statebackend通常用于存储Flink的checkpoint信息,而MinIO是一个对象存储服务,主要用于存储文件、图片、视频和其他类型的数据。
然而,从技术上讲,MinIO可以作为Flink的statebackend,因为Flink的statebackend应该支持所有可以存储文件的存储服务。具体配置方式取决于MinIO的具体实现和Flink的版本,但通常需要设置相应的Flink配置项来指定statebackend的地址和认证信息等。
如果你打算使用MinIO作为Flink的statebackend,建议查阅Flink的官方文档和MinIO的文档,了解如何配置和使用Flink与MinIO进行集成。同时,由于Flink和MinIO的版本更新很快,建议查看官方文档和社区讨论,以获取最新的信息和最佳实践。
在Flink的flink-conf.yaml配置文件中配置MinIO作为State Backend。以下是一个示例配置,将MinIO作为Flink的状态后端:
# flink-conf.yaml
state.backend: org.apache.flink.contrib.streaming.state.RocksDBStateBackend
state.checkpoints.dir: s3://your-minio-bucket/flink/checkpoints
state.backend.fs.preferred-partition-file-system: fs.s3a
# MinIO S3相关的配置
s3.access-key: your_minio_access_key
s3.secret-key: your_minio_secret_key
s3.endpoint: http://your-minio-host:9000 # 替换成你的MinIO服务地址和端口
s3.path.style.access: true # 对于MinIO,通常需要开启路径风格的访问
# Hadoop FileSystem相关的S3配置(适用于Flink 1.10以上版本)
fs.s3a.impl: io.minio.shaded.minio.s3a.S3AFileSystem
fs.s3a.aws.credentials.provider: org.apache.flink.fs.s3base.SharedInstanceProfileCredentialsProvider # 如果使用IAM角色授权,否则配置静态密钥
fs.s3a.connection.maximum: 500 # 可选配置,根据需要调整连接池大小
# 其他可能需要的S3配置,比如SSL设置、缓冲区大小等
这里假设你使用的是RocksDBStateBackend,并将检查点数据存储在MinIO上。另外,由于MinIO兼容S3接口,所以Flink通过s3a协议与MinIO进行交互。
根据你的MinIO实例的安全设置和认证方式,可能还需要调整认证提供者以及其他相关的S3连接属性。务必替换上述配置中的占位符为你自己的MinIO服务的实际凭证和URL。
在某些情况下,可能需要引入MinIO的JAR包作为Flink的依赖,以确保正确支持MinIO的S3兼容接口。如果使用的是较早版本的Flink,配置细节可能有所不同。
MinIO 可用于 Flink State Backend,特别是当你想要将状态保存在对象存储系统中时非常有用。要在 flink-conf.yml 文件中配置 MinIO StateBackend,你需要按照以下步骤操作:
添加 minio 客户端 jar 到 classpath:
# Add the MinIO client JAR to your class path.
hadoop-classic:
include-resource-jars: |
/path/to/minio-java-client.jar,
...
创建一个名为 "minio-state-store.properties" 的属性文件,放置于 $FLINK_CONF_DIR/conf 下面。这个文件应包含如下参数:
state.backend.min.io.bucket-name=my-bucket-name
state.backend.min.io.key-prefix=my-key-prefix
state.backend.min.io.client-id=minio-client-id
state.backend.min.io.region-id=region-id
state.backend.min.io.accesskey-id=accesskey-id
state.backend.min.io.secret-access-key=secret-access-key
state.backend.min.io.endpoint=http(s)://your-minio-endpoint.com
state.backend.min.io.use-https=true|false
state.backend.min.io.tls-enabled=true|false
state.backend.min.io.max-concurrent-retries-per-host=10
state.backend.min.io.multipart-part-size-bytes=1MB
state.backend.min.io.multipart-max-request-count=100
state.backend.min.io.multipart-read-timeout-milliseconds=1000ms
state.backend.min.io.multipart-write-timeout-milliseconds=1000ms
state.backend.min.io.multipart-server-side-compression=false
state.backend.min.io.multipart-gzip-level=-9
state.backend.min.io.multipart-chunksize-bytes=1MB
state.backend.min.io.multipart-expiry-after-writes-in-ms=0s
state.backend.min-io.timeout.ms=1000ms
state.backend.min.io.poll-interval.ms=100ms
state.backend.min.io.read-buffer-size-bytes=1KB
state.backend.min.io.write-buffer-size-bytes=1KB
state.backend.min.io.parallelism-factor=1
state.backend.min.io.checksum-algorithm=CRC32C
具体的内容取决于你的 MinIO 实际配置。替换 bucket 名称、密钥和其他必要的连接参数。
更新 flink-conf.xml 文件,启用 MinIO StateBackend 并指定它的位置:
<!-- Enable the MinIO StateBackend -->
enableStateParallelization: true
<!-- Configure the MinIO StateBackend with properties from 'minio-state-store.properties' file -->
state_BACKEND_MINIO_CLASSPATH=/path/to/minio-state-store.properties
启动 Flink 工作流集群,使 MinIO StateBackend 成功集成进来了。
以上就是在 Flink 中配置 MinIO StateBackend 的大致过程。请注意,由于 MinIO 和 Flink 版本之间的差异,有些配置选项可能有所不同。在实践中,最好查阅 MinIO 文档和 Flink 社区论坛,了解最新可用的配置选项。
是的,有人使用MinIO作为Flink的状态后端。MinIO是一个高性能、可扩展的对象存储服务,可以用于存储Flink作业的状态。
要在Flink中配置MinIO作为状态后端,您需要在flink-conf.yml文件中设置以下属性:
state.backend:
class: org.apache.flink.state.minio.MinioStateBackend
properties:
minio.endpoint:
minio.access-key:
minio.secret-key:
minio.bucket-name:
其中,是您的MinIO服务的URL,和是用于访问MinIO服务的访问密钥和密钥,是用于存储Flink状态的存储桶名称。
以下是一个配置示例:
state.backend:
class: org.apache.flink.state.minio.MinioStateBackend
properties:
minio.endpoint: http://localhost:9000
minio.access-key: my-access-key
minio.secret-key: my-secret-key
minio.bucket-name: my-bucket
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。