
藏经阁2.0全新上线!下载本地、线上阅读让你轻松获取技术知识。为了让更多人学习到藏经阁中的优秀技术作品,培养好的阅读习惯,“藏经阁一起读”活动来啦,你阅读,我奖励!
本期书籍:《图解算法小抄》
阅读地址:https://developer.aliyun.com/ebook/8028
书籍简介:本笔记深入讲解数据结构和算法,内容系统完整,覆盖了各种数据结构和算法,包括但不限于字符串匹配算法、分治算法、回溯算法、深度优先搜索 (DFS) 和贪心算法,非常适合想要深入理解数据结构和算法的学习者。
活动规则:阅读书籍,将你对于本书的想法、收获等在评论区留言,评论不少于200字,将选取评论质量最高的前2名送出小米鼠标lite一个。


活动时间:2023年8月7日~8月12日24:00
参与用户务必扫码加入钉群,第一时间了解活动进展、获取得奖信息。

版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
《图解算法小抄》是一本以图文并茂的方式讲解算法原理和实现的书籍,通过阅读这本书,我对算法有了更深入的理解。在这篇心得中,我将分享我从这本书中学到的一些知识,以及如何将这些知识应用到实际问题中。
首先,我认识到了算法的重要性。在计算机科学领域,算法是一种解决问题的步骤和方法,它可以帮助我们更高效地解决复杂问题。算法的设计和优化对于提高程序性能、降低资源消耗具有重要意义。通过学习算法,我们可以更好地理解计算机科学的基本原理,提高自己的编程能力。
在《图解算法小抄》中,作者通过大量的实例和图形详细地介绍了各种常见算法的原理和实现。这些算法包括排序、查找、递归、分治、动态规划等。通过学习这些算法,我对它们的特点、适用范围和优缺点有了更清晰的认识。例如,排序算法可以帮助我们对数据进行有序处理,而查找算法可以帮助我们在数据集中快速定位到目标元素。了解这些算法的原理和实现,对于我们在实际问题中选择合适的算法具有重要的指导意义。
此外,我还学到了一些高级的算法设计技巧。例如,回溯法是一种常用的搜索算法,它通过尝试所有可能的解决方案来寻找问题的解。回溯法的关键在于正确地定义搜索空间和剪枝策略,以避免无效的搜索和重复计算。通过学习回溯法,我了解到了如何将一个问题分解为更小的子问题,从而更容易地找到解决方案。这种分解思维对于解决复杂问题具有重要意义。
在实际应用中,我发现《图解算法小抄》中的许多算法都可以应用于不同的场景。例如,二分查找算法可以用于在有序数组中快速查找目标元素;快速排序算法可以用于对大量数据进行排序;动态规划算法可以用于解决最优化问题等。通过学习这些算法的实现和应用,我能够更好地解决实际问题,提高工作效率。
当然,仅仅掌握算法原理是不够的,我们还需要学会如何将它们应用到实际编程中。《图解算法小抄》提供了许多实用的编程技巧和注意事项,帮助我避免了许多常见的编程错误。例如,书中提到了使用递归时需要注意栈溢出的问题,以及在使用动态规划时如何避免重复计算等。这些细节对于提高编程能力和代码质量具有重要意义。
总之,《图解算法小抄》是一本非常实用的书籍,它通过图文并茂的方式讲解了算法的原理和实现,使我对算法有了更深入的理解。通过学习这本书,我不仅掌握了一些基本的算法知识和编程技巧,还学会了如何将它们应用到实际问题中。我相信,通过不断地学习和实践,我会成为一名优秀的程序员。
图解算法小抄》是一本深入讲解数据结构和算法的电子书。该书内容系统完整,包括了各种数据结构和算法,如字符串匹配算法、分治算法、回溯算法、深度优先搜索(DFS)和贪心算法。对于想要深入理解数据结构和算法的学习者来说,这本书非常适合。
.
有些模糊;
该书采用了清晰的教学步骤,从应用场景出发,介绍数据结构或算法的原理,分析实现步骤,并提供代码实现。这种教学方式使得内容通俗易懂,帮助读者更好地理解和应用所学的知识。
字符串匹配算法是解决字符串匹配问题的关键技术,它主要用于在一个字符串中查找特定模式的子串。本书对字符串匹配算法进行了深入讲解,包括常见的暴力匹配算法、KMP算法和Boyer-Moore算法等,帮助读者理解和掌握不同算法的优缺点和应用场景。
分治算法是一种将问题分解为更小子问题然后逐个解决的算法思想。本书对分治算法进行了详细讲解,并给出了实际应用的例子,帮助读者理解分治算法的原理和实现方法。
不容易看清楚;
回溯算法是一种通过试错的方式搜索问题的解空间的算法。它在解决组合问题、排列问题和图搜索等方面具有广泛的应用。本书对回溯算法进行了深入剖析,包括回溯的基本思想、递归实现和剪枝策略等内容。
深度优先搜索(DFS)是一种常用的图搜索算法,用于遍历或搜索图的节点。本书详细介绍了DFS算法的原理和应用,帮助读者理解如何使用DFS解决图相关的问题。
贪心算法是一种通过每一步选择局部最优解来达到全局最优解的算法思想。本书对贪心算法进行了全面的介绍,包括贪心选择性质、贪心算法的设计策略和常见应用等方面的内容。
通过阅读《图解算法小抄》,学习者可以系统地学习和理解这些重要的数据结构和算法。它提供了清晰的教学步骤和通俗易懂的讲解,帮助读者掌握算法的原理和实现方法。无论是初学者还是有一定基础的读者,都能从中获得深入的知识和技能。

翻页方式也不是很方便
对于初学者来说,本书提供了一个良好的入门点,引导读者逐步学习和掌握常用的数据结构和算法。对于有一定基础的读者,本书也提供了更深入的内容和实现细节,有助于进一步提升算法设计和优化的能力。
我认为《图解算法小抄》是一本非常适合初学者学习数据结构和算法的书籍。通过简单易懂的语言和图例,本书向读者讲解了各种数据结构和算法的基本原理和应用场景。
本书的作者采用了图例和简洁的文字相结合的方式,使得算法的实现和原理变得非常容易理解。特别是对于一些比较复杂的算法,例如分治算法和回溯算法,通过图例的方式可以让读者更好地理解算法的执行流程和优缺点。
另外,本书覆盖了各种数据结构和算法,包括常见的字符串匹配算法、排序算法、图算法等等。对于每种算法,作者都介绍了它的基本原理、应用场景和实现方式。这些内容对于初学者来说非常实用,可以帮助他们快速掌握数据结构和算法的基本知识。
总之,《图解算法小抄》是一本非常适合初学者学习数据结构和算法的书籍。通过本书的学习,读者可以掌握数据结构和算法的基本原理和应用场景,为进一步深入学习打下坚实的基础。
《图解算法小抄》是一本介绍算法和数据结构的图解入门书籍。我在阅读这本书的过程中,对于算法的理解有了较大的提升,同时也获得了一些实用的技巧和方法。
首先,本书以图解的方式呈现算法和数据结构的概念,使得抽象的概念更加直观和易于理解。通过清晰的示意图和简洁的说明,我能够更好地理解算法的原理和运行过程。相比于其他纯文字的算法书籍,图解的方式更适合我这样的视觉学习者,能够更直观地理解算法的本质。
此外,本书还介绍了一些常见的算法和数据结构,如排序算法、查找算法、树、图等。通过学习这些基础的算法和数据结构,我对于如何解决实际问题有了更清晰的思路。例如,在解决一个查找问题时,我可以选择使用二分查找算法,而不是简单地遍历整个数据集。这样不仅可以提高查找的效率,还能减少时间和空间的消耗。
除了基本的算法和数据结构,本书还介绍了一些高级的算法思想,如贪心算法、动态规划和回溯算法等。这些算法思想在解决复杂的问题时非常有用。通过学习这些思想,我能够更灵活地应用算法解决各种实际问题。
总的来说,阅读《图解算法小抄》让我对于算法和数据结构有了更深入的理解和认识。通过图解的方式,我能够更直观地理解算法的原理和运行过程。同时,通过学习基本的算法和数据结构,我能够更好地应用算法解决实际问题。这本书不仅适合初学者入门,也适合有一定算法基础的人进一步加深理解。我相信这本书对于我的算法学习之路会有很大的帮助。
《图解算法小抄》是一本非常适合初学者学习数据结构和算法的书籍。通过简单易懂的语言和图例,作者向读者讲解了各种数据结构和算法的基本原理和应用场景。
我认为本书的一个亮点是它的讲解方式。作者采用了图例和简洁的文字相结合的方式,使得算法的实现和原理变得非常容易理解。特别是对于一些比较复杂的算法,例如分治算法和回溯算法,通过图例的方式可以让读者更好地理解算法的执行流程和优缺点。
另外,本书覆盖了各种数据结构和算法,包括常见的字符串匹配算法、排序算法、图算法等等。对于每种算法,作者都介绍了它的基本原理、应用场景和实现方式。这些内容对于初学者来说非常实用,可以帮助他们快速掌握数据结构和算法的基本知识。
总之,《图解算法小抄》是一本非常适合初学者学习数据结构和算法的书籍。通过本书的学习,读者可以掌握数据结构和算法的基本原理和应用场景,为进一步深入学习打下坚实的基础。
1.1 引言
你将学习使用K最近邻算法编写推荐系统;
有些问题在有限的时间内是不可解的!书中讨论NP完全问题的部分将告诉你,如何识别这样的问题以及如何设计找到近似答案的算法。
1.2 二分查找
如果你的用户名为karlmageddon, Facebook可从以A打头的部分开始查找,但更合乎逻辑的做法是从中间开始查找。
二分查找是一种算法,其输入是一个有序的元素列表(必须有序的原因稍后解释)。
你可能不记得什么是对数了,但很可能记得什么是幂。log10100相当于问“将多少个10相乘的结果为100”。答案是两个:10 × 10=100。因此,log10100=2。对数运算是幂运算的逆运算。
1.3 大O表示法
实际上,Bob错了,而且错得离谱。列表包含10亿个元素时,简单查找需要10亿毫秒,相当于11天!为什么会这样呢?因为二分查找和简单查找的运行时间的增速不同。
也就是说,随着元素数量的增加,二分查找需要的额外时间并不多,而简单查找需要的额外时间却很多。
大O表示法指出了最糟情况下的运行时间
除最糟情况下的运行时间外,还应考虑平均情况的运行时间,这很重要。最糟情况和平均情况将在第4章讨论。
O(n),也叫线性时间,这样的算法包括简单查找。❑ O(n * log n),这样的算法包括第4章将介绍的快速排序——一种速度较快的排序算法。❑ O(n2),这样的算法包括第2章将介绍的选择排序——一种速度较慢的排序算法。❑ O(n! ),这样的算法包括接下来将介绍的旅行商问题的解决方案——一种非常慢的算法。
算法的速度指的并非时间,而是操作数的增速。
谈论算法的速度时,我们说的是随着输入的增加,其运行时间将以什么样的速度增加。
O(log n)比O(n)快,当需要搜索的元素越多时,前者比后者快得越多。
1.4 小结
算法运行时间并不以秒为单位。
算法运行时间是从其增速的角度度量的。
2.1 内存的工作原理
计算机就像是很多抽屉的集合体,每个抽屉都有地址。
接下来介绍数组和链表以及它们的优缺点。
2.2 数组和链表
一种解决之道是“预留座位”:即便当前只有3个待办事项,也请计算机提供10个位置,以防需要添加待办事项。这样,只要待办事项不超过10个,就无需转移。这是一个不错的权变措施,但你应该明白,它存在如下两个缺点。
❑ 你额外请求的位置可能根本用不上,这将浪费内存。你没有使用,别人也用不了。❑ 待办事项超过10个后,你还得转移。
对于这种问题,可使用链表来解决。
这犹如寻宝游戏。
排行榜网站使用卑鄙的手段来增加页面浏览量。它们不在一个页面中显示整个排行榜,而将排行榜的每项内容都放在一个页面中,并让你单击Next来查看下一项内容。例如,显示十大电视反派时,不在一个页面中显示整个排行榜,而是先显示第十大反派(Newman)。你必须在每个页面中单击Next,才能看到第一大反派(Gustavo Fring)。这让网站能够在10个页面中显示广告,但用户需要单击Next九次才能看到第一个,真的是很烦。
[插图]链表存在类似的问题。
但如果你需要跳跃,链表的效率真的很低。
元素的位置称为索引。
3.1 递归
这个盒子里有盒子,而盒子里的盒子又有盒子。钥匙就在某个盒子中。为找到钥匙,你将使用什么算法?
(1) 检查盒子中的每样东西。(2) 如果是盒子,就回到第一步。(3) 如果是钥匙,就大功告成!
递归只是让解决方案更清晰,并没有性能上的优势。实际上,在有些情况下,使用循环的性能更好。我很喜欢Leigh Caldwell在StackOverflow上说的一句话:“如果使用循环,程序的性能可能更高;如果使用递归,程序可能更容易理解。如何选择要看什么对你来说更重要。”
很多算法都使用了递归,因此理解这种概念很重要。
3.3 栈
[插图]本节将介绍一个重要的编程概念——调用栈(call stack)。调用栈不仅对编程来说很重要,使用递归时也必须理解这个概念。
递归函数也使用调用栈!
原来“盒子堆”存储在了栈中!这个栈包含未完成的函数调用,每个函数调用都包含还未检查完的盒子。使用栈很方便,因为你无需自己跟踪盒子堆——栈替你这样做了。
使用栈虽然很方便,但是也要付出代价:存储详尽的信息可能占用大量的内存。每个函数调用都要占用一定的内存,如果栈很高,就意味着计算机存储了大量函数调用的信息。在这种情况下,你有两种选择。
❑ 重新编写代码,转而使用循环。❑ 使用尾递归。这是一个高级递归主题,不在本书的讨论范围内。另外,并非所有的语言都支持尾递归。
3.4 小结
每个递归函数都有两个条件:基线条件和递归条件。
所有函数调用都进入调用栈。
调用栈可能很长,这将占用大量的内存。
4.1 分而治之
使用D&C解决问题的过程包括两个步骤。(1) 找出基线条件,这种条件必须尽可能简单。(2) 不断将问题分解(或者说缩小规模),直到符合基线条件。
首先,找出基线条件。最容易处理的情况是,一条边的长度是另一条边的整数倍。
如果一边长25m,另一边长50m,那么可使用的最大方块为25m×25m。
现在需要找出递归条件,这正是D&C的用武之地。根据D&C的定义,每次递归调用都必须缩小问题的规模。如何缩小前述问题的规模呢?我们首先找出这块地可容纳的最大方块。
欧几里得算法前面说“适用于这小块地的最大方块,也是适用于整块地的最大方块”,如果你觉得这一点不好理解,也不用担心。这确实不好理解,但遗憾的是,要证明这一点,需要的篇幅有点长,在本书中无法这样做,因此你只能选择相信这种说法是正确的。如果你想搞明白其中的原因,可参阅欧几里得算法。
接下来,从这块土地中划出最大的方块,余下一块更小的土地。
余下的这块土地满足基线条件,因为160是80的整数倍。将这块土地分成两个方块后,将不会余下任何土地!
第一步:找出基线条件。最简单的数组什么样呢?请想想这个问题,再接着往下读。如果数组不包含任何元素或只包含一个元素,计算总和将非常容易。
第二步:每次递归调用都必须离空数组更近一步。
别忘了,递归记录了状态。
提示编写涉及数组的递归函数时,基线条件通常是数组为空或只包含一个元素。陷入困境时,请检查基线条件是不是这样的。
诸如Haskell等函数式编程语言没有循环,因此你只能使用递归来编写这样的函数。如果你对递归有深入的认识,函数式编程语言学习起来将更容易。
符合基线条件时运行第一个定义,符合递归条件时运行第二个定义。
4.2 快速排序
快速排序是一种常用的排序算法,比选择排序快得多。例如,C语言标准库中的函数qsort实现的就是快速排序。快速排序也使用了D&C。
下面来使用快速排序对数组进行排序。对排序算法来说,最简单的数组什么样呢?还记得前一节的“提示”吗?就是根本不需要排序的数组。
接下来,找出比基准值小的元素以及比基准值大的元素。
这被称为分区(partitioning)。现在你有:❑ 一个由所有小于基准值的数字组成的子数组;❑ 基准值;❑ 一个由所有大于基准值的数组组成的子数组。
这里只是进行了分区,得到的两个子数组是无序的。但如果这两个数组是有序的,对整个数组进行排序将非常容易。
如果子数组是有序的,就可以像下面这样合并得到一个有序的数组:左边的数组+基准值+右边的数组。
这个子数组都只有一个元素,而你知道如何对这些数组进行排序。
(1) 选择基准值。(2) 将数组分成两个子数组:小于基准值的元素和大于基准值的元素。(3) 对这两个子数组进行快速排序。
归纳证明刚才你大致见识了归纳证明!归纳证明是一种证明算法行之有效的方式,它分两步:基线条件和归纳条件。是不是有点似曾相识的感觉?例如,假设我要证明我能爬到梯子的最上面。递归条件是这样的:如果我站在一个横档上,就能将脚放到上一个横档上。换言之,如果我站在第二个横档上,就能爬到第三个横档。这就是归纳条件。而基线条件是这样的,即我已经站在第一个横档上。因此,通过每次爬一个横档,我就能爬到梯子最顶端。
4.3 再谈大O表示法
快速排序的独特之处在于,其速度取决于选择的基准值。
来看看第2章介绍的选择排序,其运行时间为O(n2),速度非常慢。
还有一种名为合并排序(merge sort)的排序算法,其运行时间为O(n logn),比选择排序快得多!快速排序的情况比较棘手,在最糟情况下,其运行时间为O(n2)。
与选择排序一样慢!但这是最糟情况。在平均情况下,快速排序的运行时间为O(n log n)。
❑ 这里说的最糟情况和平均情况是什么意思呢?❑ 若快速排序在平均情况下的运行时间为O(n log n),而合并排序的运行时间总是O(n log n),为何不使用合并排序?它不是更快吗?
c是算法所需的固定时间量,被称为常量。例如,print_items所需的时间可能是10毫秒*n,而print_items2所需的时间为1秒 * n。
通常不考虑这个常量,因为如果两种算法的大O运行时间不同,这种常量将无关紧要。
但有时候,常量的影响可能很大,对快速查找和合并查找来说就是如此。
这里要告诉你的是,最佳情况也是平均情况。只要你每次都随机地选择一个数组元素作为基准值,快速排序的平均运行时间就将为O(n log n)。
5.1 散列函数
散列函数是这样的函数,即无论你给它什么数据,它都还你一个数字。
如果用专业术语来表达的话,我们会说,散列函数“将输入映射到数字”。你可能认为散列函数输出的数字没什么规律,但其实散列函数必须满足一些要求。
❑ 它必须是一致的。例如,假设你输入apple时得到的是4,那么每次输入apple时,得到的都必须为4。如果不是这样,散列表将毫无用处。
❑ 它应将不同的输入映射到不同的数字。例如,如果一个散列函数不管输入是什么都返回1,它就不是好的散列函数。最理想的情况是,将不同的输入映射到不同的数字。
散列函数总是将同样的输入映射到相同的索引。每次你输入avocado,得到的都是同一个数字。因此,你可首先使用它来确定将鳄梨的价格存储在什么地方,并在以后使用它来确定鳄梨的价格存储在什么地方。
散列函数知道数组有多大,只返回有效的索引。如果数组包含5个元素,散列函数就不会返回无效索引100。
你可能根本不需要自己去实现散列表,任一优秀的语言都提供了散列表实现。Python提供的散列表实现为字典,你可使用函数dict来创建散列表。
5.2 应用案例
将散列表用于查找
无论你访问哪个网站,其网址都必须转换为IP地址。
这不是将网址映射到IP地址吗?好像非常适合使用散列表啰!这个过程被称为DNS解析(DNS resolution),散列表是提供这种功能的方式之一。
首先来投票的是Tom,上述代码打印letthem vote!。接着Mike来投票,打印的也是let them vote!。然后,Mike又来投票,于是打印的就是kick themout!。
来看最后一个应用案例:缓存。如果你在网站工作,可能听说过进行缓存是一种不错的做法。下面简要地介绍其中的原理。假设你访问网站http://facebook.com。
(1) 你向Facebook的服务器发出请求。(2) 服务器做些处理,生成一个网页并将其发送给你。(3) 你获得一个网页。
现在假设她老问你月球离地球多远,很快你就记住了月球离地球238900英里。因此不必再去Google搜索,你就可以直接告诉她答案。这就是缓存的工作原理:网站将数据记住,而不再重新计算。
如果你登录了Facebook,你看到的所有内容都是为你定制的。你每次访问http://facebook.com,其服务器都需考虑你感兴趣的是什么内容。但如果你没有登录,看到的将是登录页面。每个人看到的登录页面都相同。Facebook被反复要求做同样的事情:“当我注销时,请向我显示主页。”有鉴于此,它不让服务器去生成主页,而是将主页存储起来,并在需要时将其直接发送给用户。
这就是缓存,具有如下两个优点。❑ 用户能够更快地看到网页,就像你记住了月球与地球之间的距离时一样。下次你侄女再问你时,你就不用再使用Google搜索,立刻就可以告诉她答案。❑ Facebook需要做的工作更少。
缓存是一种常用的加速方式,所有大型网站都使用缓存,而缓存的数据则存储在散列表中!
Facebook不仅缓存主页,还缓存About页面、Contact页面、Termsand Conditions页面等众多其他的页面。因此,它需要将页面URL映射到页面数据。
当你访问Facebook的页面时,它首先检查散列表中是否存储了该页面。
仅当URL不在缓存中时,你才让服务器做些处理,并将处理生成的数据存储到缓存中,再返回它。这样,当下次有人请求该URL时,你就可以直接发送缓存中的数据,而不用再让服务器进行处理了。
5.3 冲突
处理冲突的方式很多,最简单的办法如下:如果两个键映射到了同一个位置,就在这个位置存储一个链表。
❑ 散列函数很重要。前面的散列函数将所有的键都映射到一个位置,而最理想的情况是,散列函数将键均匀地映射到散列表的不同位置。❑ 如果散列表存储的链表很长,散列表的速度将急剧下降。然而,如果使用的散列函数很好,这些链表就不会很长!
散列函数很重要,好的散列函数很少导致冲突。那么,如何选择好的散列函数呢?这将在下一节介绍!
5.4 性能
一条水平线,看到了吧?这意味着无论散列表包含一个元素还是10亿个元素,从其中获取数据所需的时间都相同。
6.3 广度优先搜索
广度优先搜索是一种用于图的查找算法,可帮助回答两类问题。❑ 第一类问题:从节点A出发,有前往节点B的路径吗?❑ 第二类问题:从节点A出发,前往节点B的哪条路径最短?
在你看来,一度关系胜过二度关系,二度关系胜过三度关系,以此类推。因此,你应先在一度关系中搜索,确定其中没有芒果销售商后,才在二度关系中搜索。广度优先搜索就是这样做的!
你也可以这样看,一度关系在二度关系之前加入查找名单。
广度优先搜索必用队列 记住这句话
有一个可实现这种目的的数据结构,那就是队列(queue)。
有一个可实现这种目的的数据结构,那就是队列(queue)。
队列的工作原理与现实生活中的队列完全相同。假设你与朋友一起在公交车站排队,如果你排在他前面,你将先上车。队列的工作原理与此相同。队列类似于栈,你不能随机地访问队列中的元素。队列只支持两种操作:入队和出队。
队列是一种先进先出(First In FirstOut, FIFO)的数据结构,而栈是一种后进先出(Last In First Out, LIFO)的数据结构。
6.4 实现图
首先,需要使用代码来实现图。图由多个节点组成。
每个节点都与邻近节点相连,如果表示类似于“你→Bob”这样的关系呢?好在你知道的一种结构让你能够表示这种关系,它就是散列表!
记住,散列表让你能够将键映射到值。在这里,你要将节点映射到其所有邻居。
6.5 实现算法
说明更新队列时,我使用术语“入队”和“出队”,但你也可能遇到术语“压入”和“弹出”。压入大致相当于入队,而弹出大致相当于出队。
首先,创建一个队列。在Python中,可使用函数deque来创建一个双端队列。
这个算法将不断执行,直到满足以下条件之一:❑ 找到一位芒果销售商;❑ 队列变成空的,这意味着你的人际关系网中没有芒果销售商。
检查一个人之前,要确认之前没检查过他,这很重要。为此,你可使用一个列表来记录检查过的人。
7.4 负权边
如果有负权边,就不能使用狄克斯特拉算法。因为负权边会导致这种算法不管用。
8.1 教室调度问题
很多人都跟我说,这个算法太容易、太显而易见,肯定不对。但这正是贪婪算法的优点——简单易行!贪婪算法很简单:每步都采取最优的做法。
8.2 背包问题
从这个示例你得到了如下启示:在有些情况下,完美是优秀的敌人。有时候,你只需找到一个能够大致解决问题的算法,此时贪婪算法正好可派上用场,因为它们实现起来很容易,得到的结果又与正确结果相当接近。
8.3 集合覆盖问题
使用下面的贪婪算法可得到非常接近的解。(1) 选出这样一个广播台,即它覆盖了最多的未覆盖州。即便这个广播台覆盖了一些已覆盖的州,也没有关系。(2) 重复第一步,直到覆盖了所有的州。
判断近似算法优劣的标准如下:❑ 速度有多快;❑ 得到的近似解与最优解的接近程度。
贪婪算法是不错的选择,它们不仅简单,而且通常运行速度很快。在这个例子中,贪婪算法的运行时间为O(n2),其中n为广播台数量。
❑ 集合类似于列表,只是不能包含重复的元素;❑ 你可执行一些有趣的集合运算,如并集、交集和差集。
8.4 NP完全问题
这两条路线相同还是不同你可能认为这两条路线相同,难道从旧金山到马林的距离与从马林到旧金山的距离不同吗?不一定。有些城市(如旧金山)有很多单行线,因此你无法按原路返回。你可能需要离开原路行驶一两英里才能找到上高速的匝道。因此,这两条路线不一定相同。
NP完全问题的简单定义是,以难解著称的问题,如旅行商问题和集合覆盖问题。很多非常聪明的人都认为,根本不可能编写出可快速解决这些问题的算法。
Jonah需要组建一个满足所有这些要求的球队,可名额有限。等等,Jonah突然间意识到,这不就是一个集合覆盖问题吗!
Jonah可使用前面介绍的近似算法来组建球队。(1) 找出符合最多要求的球员。(2) 不断重复这个过程,直到球队满足要求(或球队名额已满)。
NP完全问题无处不在!如果能够判断出要解决的问题属于NP完全问题就好了,这样就不用去寻找完美的解决方案,而是使用近似算法即可。但要判断问题是不是NP完全问题很难,易于解决的问题和NP完全问题的差别通常很小。
简言之,没办法判断问题是不是NP完全问题,但还是有一些蛛丝马迹可循的。❑ 元素较少时算法的运行速度非常快,但随着元素数量的增加,速度会变得非常慢。❑ 涉及“所有组合”的问题通常是NP完全问题。❑ 不能将问题分成小问题,必须考虑各种可能的情况。这可能是NP完全问题。❑ 如果问题涉及序列(如旅行商问题中的城市序列)且难以解决,它可能就是NP完全问题。❑ 如果问题涉及集合(如广播台集合)且难以解决,它可能就是NP完全问题。❑ 如果问题可转换为集合覆盖问题或旅行商问题,那它肯定是NP完全问题。
8.5 小结
❑ 贪婪算法寻找局部最优解,企图以这种方式获得全局最优解。❑ 对于NP完全问题,还没有找到快速解决方案。❑ 面临NP完全问题时,最佳的做法是使用近似算法。❑ 贪婪算法易于实现、运行速度快,是不错的近似算法。
第9章 动态规划
❑ 学习动态规划,这是一种解决棘手问题的方法,它将问题分成小问题,并先着手解决这些小问题。❑ 学习如何设计问题的动态规划解决方案。
9.1 背包问题
对于背包问题,你先解决小背包(子背包)问题,再逐步解决原来的问题。
动态规划是一个难以理解的概念,如果你没有立即搞懂,也不用担心,我们将研究很多示例。
此时你很可能心存疑惑:原来的问题说的是4磅的背包,我们为何要考虑容量为1磅、2磅等的背包呢?前面说过,动态规划从小问题着手,逐步解决大问题。这里解决的子问题将帮助你解决大问题。请接着往下读,稍后你就会明白的。
9.2 背包问题FAQ
使用动态规划时,要么考虑拿走整件商品,要么考虑不拿,而没法判断该不该拿走商品的一部分。
但使用贪婪算法可轻松地处理这种情况!首先,尽可能多地拿价值最高的商品;如果拿光了,再尽可能多地拿价值次高的商品,以此类推。
动态规划功能强大,它能够解决子问题并使用这些答案来解决大问题。但仅当每个子问题都是离散的,即不依赖于其他子问题时,动态规划才管用。
最优解可能导致背包没装满吗完全可能。假设你还可以偷一颗钻石。这颗钻石非常大,重达3.5磅,价值100万美元,比其他商品都值钱得多。你绝对应该把它给偷了!但当你这样做时,余下的容量只有0.5磅,别的什么都装不下。
9.3 最长公共子串
❑ 动态规划可帮助你在给定约束条件下找到最优解。在背包问题中,你必须在背包容量给定的情况下,偷到价值最高的商品。❑ 在问题可分解为彼此独立且离散的子问题时,就可使用动态规划来解决。
要设计出动态规划解决方案可能很难,这正是本节要介绍的。下面是一些通用的小贴士。❑ 每种动态规划解决方案都涉及网格。❑ 单元格中的值通常就是你要优化的值。在前面的背包问题中,单元格的值为商品的价值。❑ 每个单元格都是一个子问题,因此你应考虑如何将问题分成子问题,这有助于你找出网格的坐标轴。
用于解决这个问题的网格是什么样的呢?要确定这一点,你得回答如下问题。❑ 单元格中的值是什么?❑ 如何将这个问题划分为子问题?❑ 网格的坐标轴是什么?
计算机科学家有时会开玩笑说,那就使用费曼算法(Feynmanalgorithm)。这个算法是以著名物理学家理查德·费曼命名的,其步骤如下。(1) 将问题写下来。(2) 好好思考。(3) 将答案写下来。
计算机科学家真是一群不按常理出牌的人啊!
需要注意的一点是,这个问题的最终答案并不在最后一个单元格中!对于前面的背包问题,最终答案总是在最后的单元格中。但对于最长公共子串问题,答案为网格中最大的数字——它可能并不位于最后的单元格中。
我们回到最初的问题:哪个单词与hish更像?hish和fish的最长公共子串包含三个字母,而hish和vista的最长公共子串包含两个字母。因此Alex很可能原本要输入的是fish。
动态规划都有哪些实际应用呢?❑ 生物学家根据最长公共序列来确定DNA链的相似性,进而判断两种动物或疾病有多相似。最长公共序列还被用来寻找多发性硬化症治疗方案。❑ 你使用过诸如git diff等命令吗?它们指出两个文件的差异,也是使用动态规划实现的。❑ 前面讨论了字符串的相似程度。编辑距离(levenshteindistance)指出了两个字符串的相似程度,也是使用动态规划计算得到的。编辑距离算法的用途很多,从拼写检查到判断用户上传的资料是否是盗版,都在其中。❑ 你使用过诸如Microsoft Word等具有断字功能的应用程序吗?它们如何确定在什么地方断字以确保行长一致呢?使用动态规划!
9.4 小结
❑ 需要在给定约束条件下优化某种指标时,动态规划很有用。❑ 问题可分解为离散子问题时,可使用动态规划来解决。❑ 每种动态规划解决方案都涉及网格。❑ 单元格中的值通常就是你要优化的值。❑ 每个单元格都是一个子问题,因此你需要考虑如何将问题分解为子问题。❑ 没有放之四海皆准的计算动态规划解决方案的公式。
第10章 K最近邻算法
❑ 学习使用K最近邻算法创建分类系统。❑ 学习特征抽取。❑ 学习回归,即预测数值,如明天的股价或用户对某部电影的喜欢程度。❑ 学习K最近邻算法的应用案例和局限性。
10.1 橙子还是柚子
请看右边的水果,是橙子还是柚子呢?我知道,柚子通常比橙子更大、更红。
如果判断这个水果是橙子还是柚子呢?一种办法是看它的邻居。来看看离它最近的三个邻居。
在这三个邻居中,橙子比柚子多,因此这个水果很可能是橙子。祝贺你,你刚才就是使用K最近邻(k-nearestneighbours, KNN)算法进行了分类!这个算法非常简单。
KNN算法虽然简单却很有用!要对东西进行分类时,可首先尝试这种算法。下面来看一个更真实的例子。
10.2 创建推荐系统
假设你是Netflix,要为用户创建一个电影推荐系统。从本质上说,这类似于前面的水果问题!
你可以将所有用户都放入一个图表中。[插图]这些用户在图表中的位置取决于其喜好,因此喜好相似的用户距离较近。假设你要向Priyanka推荐电影,可以找出五位与他最接近的用户。
假设在对电影的喜好方面,Justin、JC、Joey、Lance和Chris都与Priyanka差不多,因此他们喜欢的电影很可能Priyanka也喜欢!
有了这样的图表以后,创建推荐系统就将易如反掌:只要是Justin喜欢的电影,就将其推荐给Priyanka。
但还有一个重要的问题没有解决。在前面的图表中,相似的用户相距较近,但如何确定两位用户的相似程度呢?
从上图可知,水果A和B比较像。下面来度量它们有多像。要计算两点的距离,可使用毕达哥拉斯公式。
假设你要比较的是Netflix用户,就需要以某种方式将他们放到图表中。因此,你需要将每位用户都转换为一组坐标,就像前面对水果所做的那样。
下面是一种将用户转换为一组数字的方式。用户注册时,要求他们指出对各种电影的喜欢程度。这样,对于每位用户,都将获得一组数字!
这个距离公式很灵活,即便涉及很多个数字,依然可以使用它来计算距离。你可能会问,涉及5个数字时,距离意味着什么呢?这种距离指出了两组数字之间的相似程度。
太好了!现在要向Priyanka推荐电影将易如反掌:只要是Justin喜欢的电影,就将其推荐给Priyanka,反之亦然。你这就创建了一个电影推荐系统!
如果你是Netflix用户,Netflix将不断提醒你:多给电影评分吧,你评论的电影越多,给你的推荐就越准确。现在你明白了其中的原因:你评论的电影越多,Netflix就越能准确地判断出你与哪些用户类似。
你求这些人打的分的平均值,结果为4.2。这就是回归(regression)。你将使用KNN来做两项基本工作——分类和回归:
❑ 分类就是编组;❑ 回归就是预测结果(如一个数字)。
回归很有用。假设你在伯克利开个小小的面包店,每天都做新鲜面包,需要根据如下一组特征预测当天该烤多少条面包:❑ 天气指数1~5(1表示天气很糟,5表示天气非常好);❑ 是不是周末或节假日(周末或节假日为1,否则为0);❑ 有没有活动(1表示有,0表示没有)。你还有一些历史数据,记录了在各种不同的日子里售出的面包数量。
今天是周末,天气不错。根据这些数据,预测你今天能售出多少条面包呢?我们来使用KNN算法,其中的K为4。首先,找出与今天最接近的4个邻居。
将这些天售出的面包数平均,结果为218.75。这就是你今天要烤的面包数!
余弦相似度前面计算两位用户的距离时,使用的都是距离公式。还有更合适的公式吗?在实际工作中,经常使用余弦相似度(cosine similarity)。假设有两位品味类似的用户,但其中一位打分时更保守。他们都很喜欢Manmohan Desai的电影AmarAkbar Anthony,但Paul给了5星,而Rowan只给4星。如果你使用距离公式,这两位用户可能不是邻居,虽然他们的品味非常接近。余弦相似度不计算两个矢量的距离,而比较它们的角度,因此更适合处理前面所说的情况。本书不讨论余弦相似度,但如果你要使用KNN,就一定要研究研究它!
所谓合适的特征,就是:❑ 与要推荐的电影紧密相关的特征;❑ 不偏不倚的特征(例如,如果只让用户给喜剧片打分,就无法判断他们是否喜欢动作片)。
你认为评分是不错的电影推荐指标吗?我给The Wire的评分可能比HouseHunters高,但实际上我观看HouseHunters的时间更长。该如何改进Netflix的推荐系统呢?
在挑选合适的特征方面,没有放之四海皆准的法则,你必须考虑到各种需要考虑的因素。
10.3 机器学习简介
KNN算法真的是很有用,堪称你进入神奇的机器学习领域的领路人!机器学习旨在让计算机更聪明。你见过一个机器学习的例子:创建推荐系统。下面再来看看其他一些例子。
OCR指的是光学字符识别(opticalcharacter recognition),这意味着你可拍摄印刷页面的照片,计算机将自动识别出其中的文字。Google使用OCR来实现图书数字化。OCR是如何工作的呢?我们来看一个例子。请看下面的数字。
如何自动识别出这个数字是什么呢?可使用KNN。(1) 浏览大量的数字图像,将这些数字的特征提取出来。(2) 遇到新图像时,你提取该图像的特征,再找出它最近的邻居都是谁!
一般而言,OCR算法提取线段、点和曲线等特征。
OCR的第一步是查看大量的数字图像并提取特征,这被称为训练(training)。大多数机器学习算法都包含训练的步骤:要让计算机完成任务,必须先训练它。下一个示例是垃圾邮件过滤器,其中也包含训练的步骤。
垃圾邮件过滤器使用一种简单算法——朴素贝叶斯分类器(Naive Bayesclassifier),你首先需要使用一些数据对这个分类器进行训练。
朴素贝叶斯分类器也是一种简单而极其有效的算法。我们钟爱这样的算法!
未来很难预测,由于涉及的变数太多,这几乎是不可能完成的任务。
11.1 树
对于其中的每个节点,左子节点的值都比它小,而右子节点的值都比它大。
然而,二叉查找树的插入和删除操作的速度要快得多。
如果你对数据库或高级数据结构感兴趣,请研究如下数据结构:B树,红黑树,堆,伸展树。
11.2 反向索引
这种数据结构被称为反向索引(invertedindex),常用于创建搜索引擎。
11.3 傅里叶变换
绝妙、优雅且应用广泛的算法少之又少,傅里叶变换算是一个。BetterExplained是一个杰出的网站,致力于以通俗易懂的语言阐释数学,它就傅里叶变换做了一个绝佳的比喻:给它一杯冰沙,它能告诉你其中包含哪些成分[插图]。换言之,给定一首歌曲,傅里叶变换能够将其中的各种频率分离出来。
这种理念虽然简单,应用却极其广泛。例如,如果能够将歌曲分解为不同的频率,就可强化你关心的部分,如强化低音并隐藏高音。傅里叶变换非常适合用于处理信号,可使用它来压缩音乐。为此,首先需要将音频文件分解为音符。傅里叶变换能够准确地指出各个音符对整个歌曲的贡献,让你能够将不重要的音符删除。这就是MP3格式的工作原理!
数字信号并非只有音乐一种类型。JPG也是一种压缩格式,也采用了刚才说的工作原理。傅里叶变换还被用来地震预测和DNA分析。
使用傅里叶变换可创建类似于Shazam这样的音乐识别软件。傅里叶变换的用途极其广泛,你遇到它的可能性极高!
11.4 并行算法
为提高算法的速度,你需要让它们能够在多个内核中并行地执行!
并行算法设计起来很难,要确保它们能够正确地工作并实现期望的速度提升也很难。有一点是确定的,那就是速度的提升并非线性的,因此即便你的笔记本电脑装备了两个而不是一个内核,算法的速度也不可能提高一倍,其中的原因有两个。
并行性管理开销。假设你要对一个包含1000个元素的数组进行排序,如何在两个内核之间分配这项任务呢?如果让每个内核对其中500个元素进行排序,再将两个排好序的数组合并成一个有序数组,那么合并也是需要时间的。❑ 负载均衡。假设你需要完成10个任务,因此你给每个内核都分配5个任务。但分配给内核A的任务都很容易,10秒钟就完成了,而分配给内核B的任务都很难,1分钟才完成。这意味着有那么50秒,内核B在忙死忙活,而内核A却闲得很!你如何均匀地分配工作,让两个内核都一样忙呢?
要改善性能和可扩展性,并行算法可能是不错的选择!
11.5 MapReduce
有一种特殊的并行算法正越来越流行,它就是分布式算法。在并行算法只需两到四个内核时,完全可以在笔记本电脑上运行它,但如果需要数百个内核呢?在这种情况下,可让算法在多台计算机上运行。MapReduce是一种流行的分布式算法,你可通过流行的开源工具Apache Hadoop来使用它。
分布式算法非常适合用于在短时间内完成海量工作,其中的MapReduce基于两个简单的理念:映射(map)函数和归并(reduce)函数。
归并函数可能令人迷惑,其理念是将很多项归并为一项。映射是将一个数组转换为另一个数组。
而归并是将一个数组转换为一个元素。
11.6 布隆过滤器和HyperLogLog
布隆过滤器是一种概率型数据结构,它提供的答案有可能不对,但很可能是正确的。为判断网页以前是否已搜集,可不使用散列表,而使用布隆过滤器。使用散列表时,答案绝对可靠,而使用布隆过滤器时,答案却是很可能是正确的。
❑ 可能出现错报的情况,即Google可能指出“这个网站已搜集”,但实际上并没有搜集。❑ 不可能出现漏报的情况,即如果布隆过滤器说“这个网站未搜集”,就肯定未搜集。
布隆过滤器的优点在于占用的存储空间很少。使用散列表时,必须存储Google搜集过的所有URL,但使用布隆过滤器时不用这样做。布隆过滤器非常适合用于不要求答案绝对准确的情况,前面所有的示例都是这样的。对http://bit.ly而言,这样说完全可行:“我们认为这个网站可能是恶意的,请倍加小心。”
面临海量数据且只要求答案八九不离十时,可考虑使用概率型算法!
11.7 SHA算法
另一种散列函数是安全散列算法(secure hash algorithm, SHA)函数。
说明SHA生成的散列值很长,这里截短了。你可使用SHA来判断两个文件是否相同,这在比较超大型文件时很有用。假设你有一个4 GB的文件,并要检查朋友是否也有这个大型文件。为此,你不用通过电子邮件将这个大型文件发送给朋友,而可计算它们的SHA散列值,再对结果进行比较。
SHA还让你能在不知道原始字符串的情况下对其进行比较。例如,假设Gmail遭到攻击,攻击者窃取了所有的密码!你的密码暴露了吗?没有,因为Google存储的并非密码,而是密码的SHA散列值!你输入密码时,Google计算其散列值,并将结果同其数据库中的散列值进行比较。
Google只是比较散列值,因此不必存储你的密码!SHA被广泛用于计算密码的散列值。这种散列算法是单向的。你可根据字符串计算出散列值。
当前,最安全的密码散列函数是bcrypt,但没有任何东西是万无一失的。
11.8 局部敏感的散列算法
SHA还有一个重要特征,那就是局部不敏感的。
如果你修改其中的一个字符,再计算其散列值,结果将截然不同![插图]这很好,让攻击者无法通过比较散列值是否类似来破解密码。
有时候,你希望结果相反,即希望散列函数是局部敏感的。
❑ Google使用Simhash来判断网页是否已搜集。❑ 老师可以使用Simhash来判断学生的论文是否是从网上抄的。❑ Scribd允许用户上传文档或图书,以便与人分享,但不希望用户上传有版权的内容!这个网站可使用Simhash来检查上传的内容是否与小说《哈利·波特》类似,如果类似,就自动拒绝。
需要检查两项内容的相似程度时,Simhash很有用。
11.9 Diffie-Hellman密钥交换
这里有必要提一提Diffie-Hellman算法,它以优雅的方式解决了一个古老的问题:如何对消息进行加密,以便只有收件人才能看懂呢?
在二战期间,德国人使用的加密算法比这复杂得多,但还是被破解了。Diffie-Hellman算法解决了如下两个问题。
❑ 双方无需知道加密算法。他们不必会面协商要使用的加密算法。❑ 要破解加密的消息比登天还难。
Diffie-Hellman使用两个密钥:公钥和私钥。顾名思义,公钥就是公开的,可将其发布到网站上,通过电子邮件发送给朋友,或使用其他任何方式来发布。你不必将它藏着掖着。有人要向你发送消息时,他使用公钥对其进行加密。加密后的消息只有使用私钥才能解密。只要只有你知道私钥,就只有你才能解密消息!
11.10 线性规划
最好的东西留到最后介绍。线性规划是我知道的最酷的算法之一。
线性规划是一个宽泛得多的框架,图问题只是其中的一个子集。但愿你听到这一点后心潮澎湃!
11.11 结语
本章简要地介绍了10个算法,唯愿这让你知道还有很多地方等待你去探索。在我看来,最佳的学习方式是找到感兴趣的主题,然后一头扎进去,而本书便为你这样做打下了坚实的基础。
您好,非常感谢您推荐这本《图解算法小抄》。我认真通读后,对该书的内容和特点有了较为全面和深入的理解,现用全汉语详细总结我的阅读感受,由衷希望能符合您的要求。
首先,这本书利用大量生动逼真的图示,辅以简洁通俗的语言,从多个角度直观地讲解了各类基础算法的原理和实现过程。如 “插入排序” 一章就用实际的扑克牌排序过程作为比喻,步步为营地引导读者进入算法思维;“二分查找” 一章则通过折半搜索书本的情景化说明,将抽象问题形象化。这种图文结合的讲解方式,极大地减少了理解算法的难度,启发读者的算法意识。
其次,本书不仅讲解思路,还提供Python代码实现。通过简单的代码案例,巩固算法概念,使读者从被动理解到主动实践。代码风格简洁明了,添加了详细注释,非专业编程读者也能易于上手。代码实现部门对我Algorithm学习大有裨益。
最后,书中算法种类齐全,覆盖排序、查找、动态规划等常见题型,由浅入深,内容丰富,适合作为算法入门读物。参考该书,可以系统地学习算法思想,打牢基础。
总之,这本《图解算法小抄》深入浅出,图文并茂,以直观形象的方式阐释抽象算法概念,是算法学习的难得好书。我衷心推荐算法初学者通读此书,也会经常回顾使用,以进一步提高自己的算法设计与实现能力。非常感谢您给我提供阅读这本质量上乘的算法图书的机会。我会继续努力,针对技术书籍进行充分理解、总结和运用,以提升自身的专业能力。
算法被称为程序的灵魂,因为优秀的算法能在处理海量数据时保持高速计算能力。计算框架和缓存技术的核心功能就源于算法。在实际工作中,一个高效的算法可以使支持数干万在线用户的服务器程序稳定运行。数据结构和算法也是许多一线T公司面试的重要部分。如果程序员不想永远只是编写代码,那么就需要花时间研究数据结构和算法。所以这本书便能够帮助前端的同学充分了解这些数据结构和算法的原理和实现步骤。
读一本书之前,首先要了解书的题目。《图解算法小抄》中题目表面的意思是指这本书是一本关于算法的资料,采用图解的方式呈现算法内容,并且以简明扼要的形式进行介绍。它可能适合初学者快速了解和入门算法,也可供高级读者回顾和巩固知识。这个题目并没有涉及太多其他深层含义,主要是从字面上描述了这本书的主题和学习方式。我总结这个题目有以下几个特点:
突出算法:题目中直接指明了书的内容是关于算法的介绍。这表明该书主要侧重于讲解各种常见的数据结构和算法,包括其基本原理、应用场景和实现方法等。通过这本书,读者可以系统地学习和掌握算法,为进一步提升编程能力打下坚实的基础。
简洁实用:题目中加入了"小抄"一词,暗示了该书的风格可能以简洁明了为主,并且注重实用性。这意味着该书可能剔除了冗长的理论推导和繁琐的术语,而更注重给读者提供实际应用中常见的算法和技巧,使得读者能够快速掌握和运用。
高效学习:题目中的"小抄"一词也暗示了该书可能是一本内容简练、重点突出的算法学习资料。这意味着读者可以通过这本书快速了解和学习各种算法,不需要花费过多时间和精力。这对于那些希望快速入门算法的初学者或需要快速回顾巩固的高级读者来说十分有益。
通过粗略阅读这本书,了解到该文档目录页主要包括数据结构和算法两个部分。根据目录内容,可以初步了解到《图解算法小抄》主要讲述以下内容:


《图解算法小抄》通过图解的方式展示了这些数据结构和算法的概念、原理和应用。 读者可以通过阅读该书来深入理解不同数据结构和算法,并学习如何使用它们解决实际问题。
通过仔细地阅读这本书,可以讲该书总结为一本深入浅出地介绍了数据结构和算法的实用指南。这本书通过清晰的图解和简洁的文字,为读者提供了一种全新的学习算法的方式,将复杂的概念变得易于理解,并帮助读者逐步掌握算法设计和实现的基本原理。
本书在内容上非常系统和完整。作者对各种常见的数据结构和算法进行了详尽的讲解,包括但不限于字符串匹配算法、分治算法、回溯算法、深度优先搜索 (DFS) 和贪心算法等。这使得读者能够全面了解各个算法的特点、适用场景以及实际应用,为算法学习提供了坚实的基础。
本书采用了图解的方式呈现算法的执行过程,这种形式更加直观生动,能够帮助读者更好地理解算法的思想和执行流程。通过色彩明亮、布局合理的图表,读者可以清楚地看到每个步骤的关键操作和数据变化,从而更加深入地理解算法的本质。同时,图解也减少了冗长的文字描述,使得算法的学习过程更加轻松和愉快。
本书的语言简洁明了,没有过多的专业术语和复杂的数学推导,使得读者能够轻松理解算法的核心思想。作者通过通俗易懂的语言,将抽象的算法概念转化为具体的例子和实际问题,让读者在学习中能够迅速建立起对算法原理的认知。这种风格非常适合初学者,也使得高级读者能够通过简单的回顾和巩固来提升自己的水平。
本书给出了大量的实践案例和习题,帮助读者巩固所学内容并提高解决实际问题的能力。每个章节结束时都有一些练习题和思考题,读者可以通过自己动手实践,从而更好地理解和运用算法。书中还附有详细的答案和解析,方便读者检验自己的学习成果。
在阅读这本书的途中,我对树的概念印象比较深刻。主要讲述了以下相关知识点:
二叉搜索树(Binary Search Tree):介绍了二叉搜索树的概念和特性。二叉搜索树是一种有序的二叉树,对于每个节点,其左子树中的所有节点都小于它,右子树中的所有节点都大于它。这使得在二叉搜索树中可以高效地进行插入、删除和查找操作。
AVL树:介绍了平衡二叉搜索树的一种类型,即AVL树。AVL树通过保持树的平衡性来提高查询的效率。在AVL树中,任何节点的左子树和右子树的高度最多相差1,通过旋转操作来维护树的平衡性。
红黑树:讲解了另一种自平衡二叉搜索树结构,即红黑树。红黑树是一种平衡的二叉搜索树,通过定义颜色规则和旋转操作来保持树的平衡。红黑树具有良好的平衡性能,在许多编程语言和库中被广泛应用。
线段树:介绍了线段树这种数据结构,它在处理区间相关问题时非常有用。线段树将原始数据存储在树中的节点上,并使用一些特定的操作(如查询和更新)来实现区间相关的操作,如求和、最大值等。
Fenwick树/二进制索引树:解释了另一种处理区间和范围查询的数据结构,也被称为Binary Indexed Tree(BIT)。Fenwick树是一种高效的数据结构,用于支持快速的区间求和操作,特别适用于频繁更新的情况。

这些知识点涵盖了不同类型的树结构,它们在算法和数据结构中具有广泛的应用。通过阅读《图解算法小抄》中关于这些知识点的内容,将能够了解它们的原理、特性以及如何在实际问题中应用。
总的来说,《图解算法小抄》是一本很有价值的算法学习指南。它系统完整地介绍了数据结构和算法的基本概念和应用,通过图解、简洁明了的语言以及实践案例,帮助读者深入理解和掌握算法。这本书不仅适合算法初学者,也能作为算法进阶者的参考书,可作为工程师和计算机专业学生必备的学习资料。如果你对算法感兴趣,想要提升自己的编程能力,那么《图解算法小抄》将是你的不二选择。
阅读这本书后,我获得到的一些启发和心得:
1.全面而系统的内容:由于该书涵盖了各种数据结构和算法,包括字符串匹配、分治、回溯、DFS和贪心算法等,因此它可能提供了广泛而全面的内容。这对于想要深入理解数据结构和算法的学习者来说是非常有价值的。
2.图解带来的好处:根据书名中提到的“图解”,预计该书将使用图形化表示来解释算法的工作原理和步骤。这种图解方法可以帮助读者更清晰地理解复杂的算法概念,从而更容易应用于实际问题。
3.实用性与练习的重要性:书籍简介中提到该书适合想要深入理解数据结构和算法的学习者。因此,我们可以期待在书中找到一些实际应用的例子和练习,这对于巩固所学知识并将其应用到实际问题中是非常重要的。
4.面向学习者的写作风格:该书自称为“小抄”,意味着它可能以简洁明了的方式呈现内容,旨在为读者提供简单易懂的解释。这样的写作风格对于初学者或对算法感到困惑的人来说可能是有帮助的。
《图解算法小抄》是一本系统而全面地讲解数据结构和算法的书籍。
通过深入浅出的图解风格,本书帮助读者理解复杂的概念和算法,并将其应用于实际问题中。
首先,我对这本书的整体评价非常高。它以简洁明了的方式介绍了各种数据结构和算法,使得初学者也能够轻松理解。图解风格的插图和实例帮助读者直观地理解每个概念和算法的工作原理。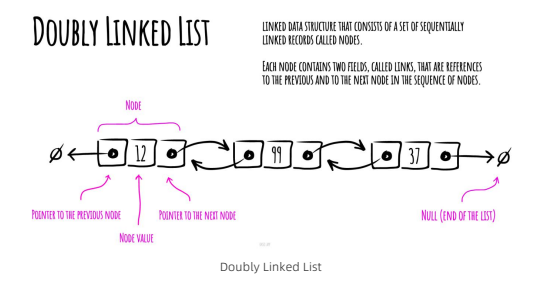
此外,书中还提供了大量的练习题和例子,让我们有机会进行实践和巩固所学内容。
通过阅读这本书,我从中获得了很多知识和技能。例如,在学习字符串匹配算法时,书中详细介绍了KMP算法的原理和实现方式。我通过阅读和实践,掌握了如何在文本中高效地查找特定模式的方法。这对于日常工作中处理大量文本数据的任务非常有帮助。
除了具体的算法,本书还强调了算法设计的重要性。作者通过分治算法、回溯算法和贪心算法等章节,展示了不同类型的算法设计思路。我学到了如何分解复杂问题为较小的子问题,并通过递归或迭代的方式求解。这种算法设计思维可以帮助我更好地解决实际问题。
另一个我喜欢的方面是,书中对于每个算法都提供了实际应用的例子。例如,在深度优先搜索(DFS)的章节中,作者展示了如何使用DFS来解决迷宫问题。这种将算法与实际场景结合的方法,让我更加深入地理解了算法的实际应用和效果。
尽管《图算法小抄》在内容上非常全面,但我认为书中可以进一步拓展一些主题。
例如,关于动态规划算法的部分可能可以更加详细地解释其原理和应用场景。此外,一些高级主题如图论和并行算法也可以作为扩展内容进行介绍。
总的来说,我认为《图解算法小抄》是一本非常有价值的书籍。它以简洁明了的方式讲解了各种数据结构和算法,并通过图解和实例帮助读者更好地理解和应用所学知识。我强烈推荐这本书给那些想要深入学习和理解数据结构和算法的读者。无论是初学者还是有一定基础的人士,这本书都能帮助他们建立坚实的算法基础,并在实际工作发挥应用价值。
《图解算法小抄》是一本深入浅出、寓教于乐的算法学习书籍,作者通过生动的插图和简洁的语言,让我们对算法的核心概念有了更深刻的理解。阅读这本书,我收获颇丰,以下就是我在阅读过程中的一些心得体会:
直观明了:这本书的最大特点是其直观的图示和实例。通过丰富的插图和真实世界的例子,作者把复杂的概念变得简单易懂。这种“图解”的方式让我对算法有了更直观的认识,也让我更容易理解算法的原理和应用。
注重实践:书中的例子和练习题让我有机会亲自实践各种算法。通过实际操作,我不仅深入理解了算法的运作过程,也学会了如何运用算法解决实际问题。这种理论结合实践的学习方法使我收获颇丰。
启发思考:书中的问题并非直接给出答案,而是引导读者自己去探索和发现。这种启发式的学习方式激发了我的好奇心和求知欲,让我更加主动地去思考和解决问题。
强调应用:作者在讲解每个算法时,都会结合实际应用场景进行分析。这使我明白了算法并非抽象的数学概念,而是有实际用途的工具。通过学习算法,我不仅提高了自己的编程技能,也增强了自己的问题解决能力。
学习不止:阅读这本书让我对算法产生了浓厚的兴趣。我开始主动学习更多的算法和数据结构知识,不断提升自己的编程技能。同时,我也意识到算法的学习是一个不断探索和进步的过程,需要持续的努力和耐心。
总的来说,《图解算法小抄》是一本非常适合初学者入门的算法书籍。通过阅读这本书,我不仅掌握了基本的算法原理,也在实际操作中提高了自己的编程能力和问题解决能力。我会推荐这本书给想要学习算法的朋友们,希望你们也能从中获得启示和收获。
作为一名程序员,数据结构和算法的学习与应用一直是必不可少的。《图解算法小抄》是一本非常不错的书,对于数据结构和算法的讲解十分全面和系统。本书通过直接解释各种数据结构和算法的原理和应用,让读者能够更好地理解和掌握它们的思想和实现方法。书中涵盖了各种不同的算法,如字符串匹配算法、分治算法、回溯算法、深度优先搜索 (DFS) 和贪心算法等,这些算法的思想和实现方式在实际工作中都是非常有用的。
此外,我觉得本书最大的亮点就是作者通过图文并茂的方式,将复杂的概念和算法转化为非常直观和易懂的图形和例子,让人可以更好地理解和记忆。同时,本书也提供了非常多的在线参考资料和整理笔记,对于进一步的思考和学习提供了很好的帮助。
总之,《图解算法小抄》是一本非常不错的书,只要花费足够时间和精力,相信每个人都可以学到很多。对于想要深入学习数据结构和算法的人来说,本书是一定要入手的。
这本书是前端大佬所写,不经感叹前端也需要掌握这些算法呀,膜拜。
观后感:
前面一半的章节讲了基本的数据结构和一些变种的常用的数据结构,作者通过图文结合,这些内容还是比较容易理解,如果不理解的话,作者也给了外部网址,方便我们去更详细的了解;后面一半讲的是算法相关,难度从入门简单到困难,作者也是通过图文结合(我觉得配上动画可能会更加好),也方便读者理解算法的过程,作者也举例了一些算法适用的一些场景,这点我觉得非常好,更加能够加深对算法的理解,还对一些数据结构栈,队列等举例应用场景

这就很方便我们后续解题面试了。
我大概读完了,还是有很多收获的,不过这种算法需要多花时间,读透里面的思维方式,这样才能学到东西,对这本书还是很推荐的,虽然是前端所写,但是也适用后端,值得推广,或作为收藏。
这本书系统完整地讲解了各种数据结构和算法,包括了字符串匹配算法、分治算法、回溯算法、深度优先搜索(DFS)和贪心算法等。

这些都是计算机科学中非常重要的概念和技术,对于开发人员来说掌握它们是至关重要的。
在阅读过程中,我希望能够更深入地了解这些数据结构和算法的原理、应用场景以及实现方式。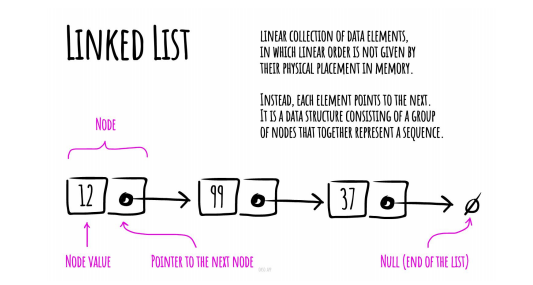
特别是对于字符串匹配算法,我希望能够学习到一些高效的算法,以便在实际开发中能够更好地处理字符串匹配问题。
此外,我也对回溯算法和深度优先搜索很感兴趣,因为这些算法在解决一些组合优化和图遍历问题时非常有用。
通过阅读这本书,我希望能够掌握一些新的数据结构和算法,并且能够将它们应用到实际的项目中。我相信这本书能够帮助我提升解决问题的能力,并且对我的职业发展也会有积极的影响。

