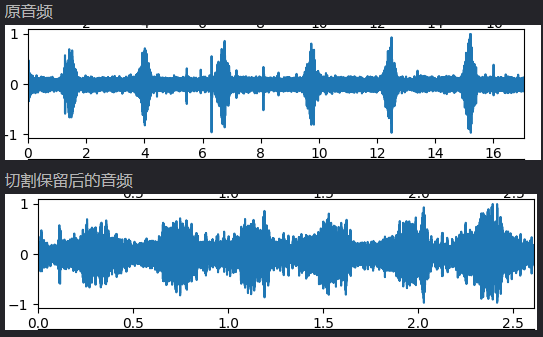
1.准备环境https://github.com/marsbroshok/VAD-python
里面的vad.py文件
2.具体代码
from vad import VoiceActivityDetector****import wave
if __name__ == "__main__": load_file = "test.wav" save_file = "process.wav" # 获取vad分割节点 v = VoiceActivityDetector(load_file) raw_detection = v.detect_speech() speech_labels, point_labels = v.convert_windows_to_readible_labels(raw_detection) if len(point_labels) != 0: # 根据节点音频分割并连接 data = v.data cut_data = [] Fs = v.rate for start, end in point_labels: cut_data.extend(data[int(start):int(end)])
# 保存音频 f = wave.open(save_file, ’w’) nframes = len(cut_data) f.setparams((1, 2, Fs, nframes, ’NONE’, ’NONE’)) # 声道,字节数,采样频率,*,* wavdata = np.array(cut_data) wavdata = wavdata.astype(np.int16) f.writeframes(wavdata) # outData f.close()
3.部分参数
vad.py文件
class VoiceActivityDetector(): """ Use signal energy to detect voice activity in wav file """
def __init__(self, wave_input_filename): self._read_wav(wave_input_filename)._convert_to_mono() #沿音频数据移动 20 毫秒的窗口。 self.sample_window = 0.02 # 20 ms self.sample_overlap = 0.01 # 10ms #应用长度为 0.5s 的中值滤波器来平滑检测到的语音区域。 self.speech_window = 0.5 # half a second #计算语带能量与窗口总能量的比值。如果比率大于阈值(默认为 0.6),则将窗口标记为语音 self.speech_energy_threshold = 0.6 # 60% of energy in voice band #中值滤波器(滤波保留2000-8000hz) self.speech_start_band = 2000 self.speech_end_band = 8000 self.data_speech = []