
MaxCompute Spark 如何在本地进行调试?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
如何搭建MaxCompute Spark开发环境。
前提条件
搭建开发环境之前,请确保您已经完成如下软件的安装:
JDK 1.8
Python2.7
Maven
Git
下载MaxCompute Spark客户端
MaxCompute Spark发布包集成了MaxCompute认证功能。作为客户端工具,它通过Spark-Submit方式提交作业到MaxCompute项目中运行。目前提供了面向Spark1.x和Spark2.x的2个发布包:
Spark-1.6.3:适用于Spark1.x应用的开发。
Spark-2.3.0:适用于Spark2.x应用的开发。
# 推荐使用JDK 1.8
export JAVA_HOME=/path/to/jdk
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
export SPARK_HOME=/path/to/spark_extracted_package
export PATH=$SPARK_HOME/bin:$PATH
export PATH=/path/to/python/bin/:$PATH
$SPARK_HOME/conf路径下存在spark-defaults.conf.template文件,您可以将其作为spark-defaults.conf的模版进行相关配置。
# spark-defaults.conf
# 填写MaxCompute的项目空间名称以及账号信息。
spark.hadoop.odps.project.name = XXX
spark.hadoop.odps.access.id = XXX
spark.hadoop.odps.access.key = XXX
# 以下配置保持不变。
spark.hadoop.odps.end.point = http://service.cn.maxcompute.aliyun.com/api # Spark客户端连接访问MaxCompute项目的Endpoint,您可以根据自己情况进行修改。详情请参见配置Endpoint。
spark.hadoop.odps.runtime.end.point = http://service.cn.maxcompute.aliyun-inc.com/api # Spark运行环境Endpoint,所在Region的MaxCompute VPC网络的Endpoint。您可以根据自己情况进行修改。
spark.sql.catalogImplementation=odps
spark.hadoop.odps.task.major.version = cupid_v2
spark.hadoop.odps.cupid.container.image.enable = true
spark.hadoop.odps.cupid.container.vm.engine.type = hyper
spark.hadoop.odps.cupid.webproxy.endpoint = http://service.cn.maxcompute.aliyun-inc.com/api
spark.hadoop.odps.moye.trackurl.host = http://jobview.odps.aliyun.com
特殊场景和功能,需要开启一些其它的配置参数,详情请参见Spark配置详解。
MaxCompute Spark提供了项目工程模版,建议您下载模版复制后直接在模版里开发。
git clone https://github.com/aliyun/MaxCompute-Spark.git
cd spark-1.x
mvn clean package
git clone https://github.com/aliyun/MaxCompute-Spark.git
cd spark-2.x
mvn clean package
配置访问MaxCompute表所需的依赖。
Spark作业访问MaxCompute表,需要依赖odps-spark-datasource模块。Maven配置举例如下。
<!-- Spark-2.x请依赖此模块 -->
<dependency>
<groupId>com.aliyun.odps</groupId>
<artifactId>odps-spark-datasource_2.11</artifactId>
<version>3.3.8-public</version>
</dependency>
<!-- Spark-1.x请依赖此模块 -->
<dependency>
<groupId>com.aliyun.odps</groupId>
<artifactId>odps-spark-datasource_2.10</artifactId>
<version>3.3.8-public</version>
</dependency>
<dependency>
<groupId>com.aliyun.odps</groupId>
<artifactId>hadoop-fs-oss</artifactId>
<version>3.3.8-public</version>
</dependency>
完成以上的工作之后,执行冒烟测试,验证MaxCompute Spark是否可以端到端连通。以Spark-2.x为例,您可以提交一个SparkPi验证功能是否正常,提交命令如下。
# /path/to/MaxCompute-Spark请指向正确的编译出来后的应用程序的Jar包。
cd $SPARK_HOME
bin/spark-submit --master yarn-cluster --class com.aliyun.odps.spark.examples.SparkPi \
/path/to/MaxCompute-Spark/spark-2.x/target/spark-examples_2.11-1.0.0-SNAPSHOT-shaded.jar
# 当看到以下日志表明冒烟作业成功。
19/06/11 11:57:30 INFO Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: 11.222.166.90
ApplicationMaster RPC port: 38965
queue: queue
start time: 1560225401092
final status: SUCCEEDED
通常,本地调试成功后会在集群上执行代码。但是Spark可以支持在IDEA里以Local模式直接运行代码,运行时请注意以下几点:
代码需要手动设置spark.master。
val spark = SparkSession
.builder()
.appName("SparkPi")
.config("spark.master", "local[4]") // 需要设置spark.master为local[N]才能直接运行,N为并发数。
.getOrCreate()
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
pom.xml中设置要求scope为provided,所以运行时会出现NoClassDefFoundError报错。
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/spark/sql/SparkSession$
at com.aliyun.odps.spark.examples.SparkPi$.main(SparkPi.scala:27)
at com.aliyun.odps.spark.examples.Spa。r。kPi.main(SparkPi.scala)
Caused by: java.lang.ClassNotFoundException: org.apache.spark.sql.SparkSession$
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:335)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 2 more
您可以按照以下方式手动将MaxCompute Spark下的Jars目录加入IDEA模板工程项目中,既可以保持scope=provided,又能在IDEA里直接运行不报错:
在IDEA中单击顶部菜单栏上的File,选中Project Structure…。
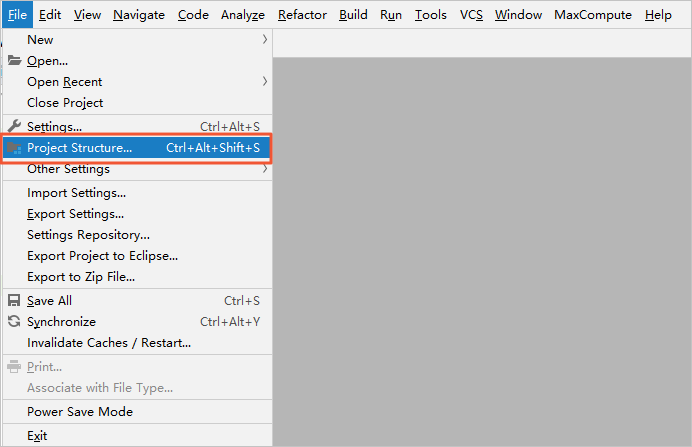
在Project Structure页面,单击左侧导航栏上的Modules。选择资源包,并单击资源包的Dependencies页签。
在资源包的Dependencies页签下,单击左下角的+,选择JARs or directories…添加MaxCompute Spark下的Jars目录。
val spark = SparkSession
.builder()
.appName("SparkPi")
.config("spark.master", "local[4]") // 需设置spark.master为local[N]才能直接运行,N为并发数。
.config("spark.hadoop.odps.project.name", "****")
.config("spark.hadoop.odps.access.id", "****")
.config("spark.hadoop.odps.access.key", "****")
.config("spark.hadoop.odps.end.point", "http://service.cn.maxcompute.aliyun.com/api")
.config("spark.sql.catalogImplementation", "odps")
.getOrCreate()
欢迎扫码加入 MaxCompute开发者社区钉钉群,或点击申请加入。
