
这段机器学习基础视频将帮助您了解什么是机器学习,机器学习有哪些类型-有监督,无监督和强化学习,如何通过简单的示例学习机器学习以及如何在各个行业中使用机器学习。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
 如果人类能够训练机器从过去的数据中学习呢?嗯,这被称为机器学习,但它不仅仅是学习,它还涉及理解和推理,所以今天我们将学习机器学习的基础知识。
如果人类能够训练机器从过去的数据中学习呢?嗯,这被称为机器学习,但它不仅仅是学习,它还涉及理解和推理,所以今天我们将学习机器学习的基础知识。

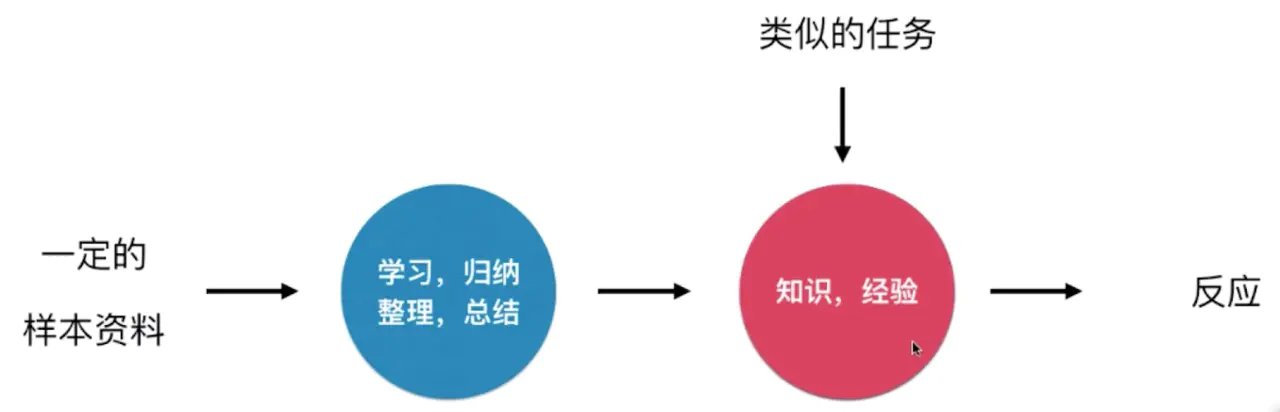
插一段《Python3入门机器学习经典算法与应用》这门课程中的解释: 人类是怎么学习的?通过给大脑输入一定的资料,经过学习总结得到知识和经验,有当类似的任务时可以根据已有的经验做出决定或行动。
机器学习(Machine Learning)的过程与人类学习的过程是很相似的。机器学习算法本质上就是获得一个 f(x) 函数表示的模型,如果输入一个样本 x 给 f(x) 得到的结果是一个类别,解决的就是一个分类问题,如果得到的是一个具体的数值那么解决的就是回归问题。
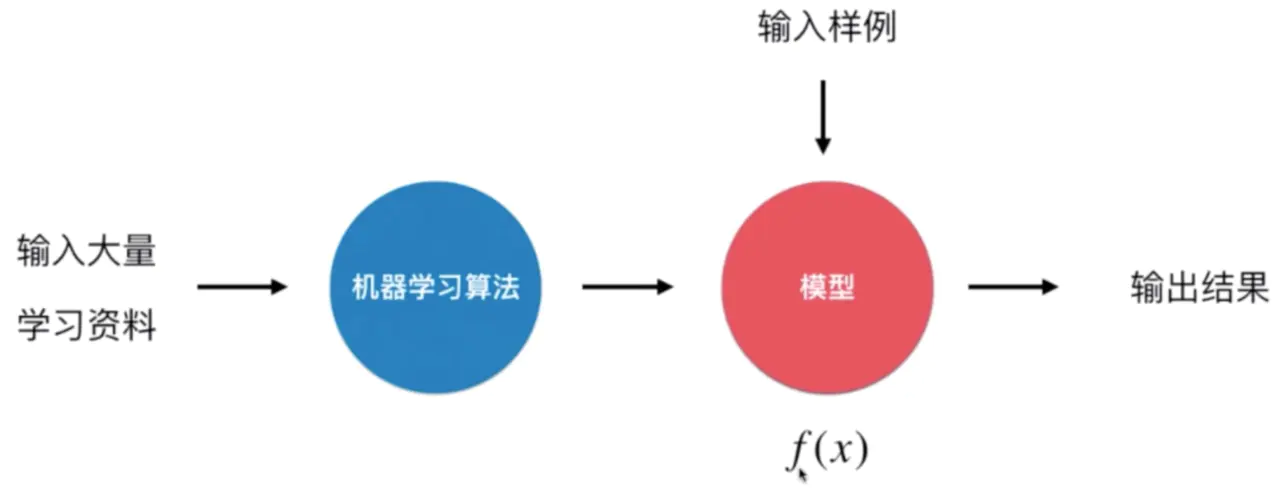
机器学习与人类学习的整体机制是一致的,有一点区别是人类的大脑只需要非常少的一些资料就可以归纳总结出适用性非常强的知识或者经验,例如我们只要见过几只猫或几只狗就能正确的分辨出猫和狗,但对于机器来说我们需要大量的学习资料,但机器能做到的是智能化不需要人类参与。
简单的示例
保罗听新歌,他根据歌曲的节奏、强度和声音的性别来决定喜欢还是不喜欢。

为了简单起见,我们只使用速度和强度。所以在这里,速度是在 x 轴上,从缓慢到快速,而强度是在 y 轴上,从轻到重。我们看到保罗喜欢快节奏和高亢的歌曲,而他不喜欢慢节奏和轻柔的歌曲。
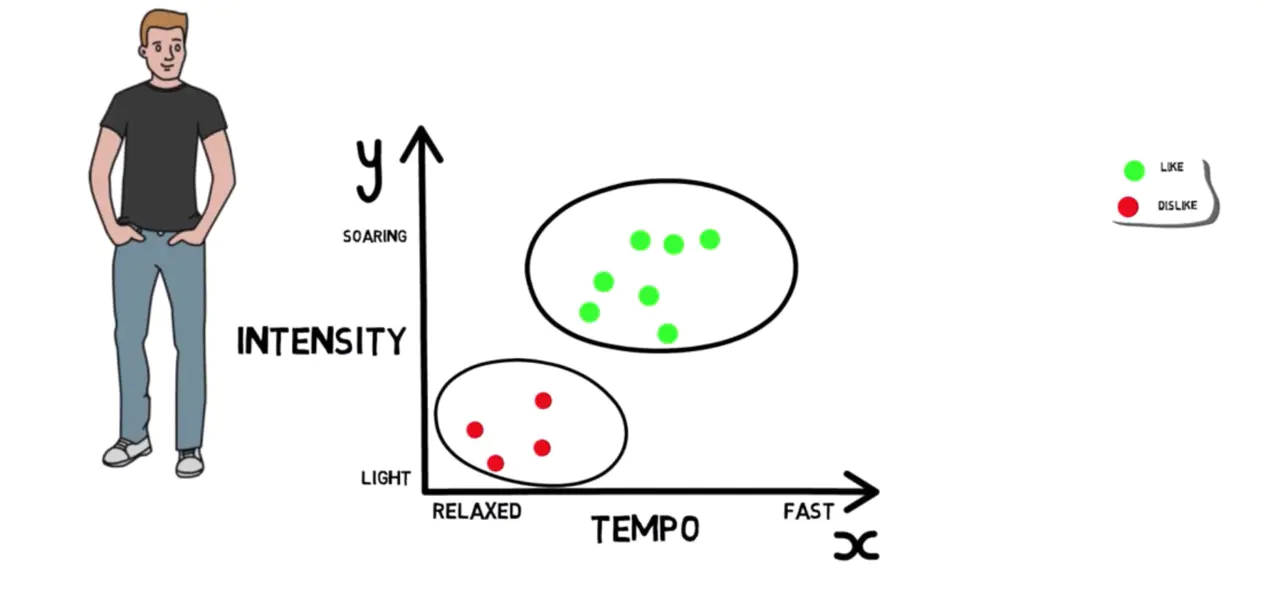
现在我们知道了保罗的选择,让我们看看保罗听一首新歌,让我们给它命名这首歌 A,歌曲 A 速度快,强度飙升,所以它就在这里的某个地方。看看数据,你能猜出球在哪里会喜欢这首歌?
 eveloper-ecology/a61a1dd9937f4aa4bba873397609969b.jpg)
eveloper-ecology/a61a1dd9937f4aa4bba873397609969b.jpg)
对,保罗喜欢这首歌。 通过回顾保罗过去的选择,我们能够很容易地对未知的歌曲进行分类。假设现在保罗听了一首新歌,让我们把它贴上 B 的标签,B 这首歌就在这里的某个地方,节奏中等,强度中等,既不放松也不快速, 既不轻缓也不飞扬。 现在你能猜出保罗喜欢还是不喜欢它吗?不能猜出保罗会喜欢或不喜欢它,其他选择还不清楚。没错,我们可以很容易地对歌曲 A 进行分类,但是当选择变得复杂时,就像歌曲B 一样。机器学习可以帮你解决这个问题。
让我们看看如何。在歌曲 B 的同一个例子中,如果我们在歌曲 B 周围画一个圆圈,我们会看到有四个绿色圆点表示喜欢,而一个红色圆点不喜欢。 如果我们选择占大多数比例的绿色圆点,我们可以说保罗肯定会喜欢这首歌,这就是一个基本的机器学习算法,它被称为 K 近邻算法, 这只是众多机器学习算法之一中的一个小例子。 但是当选择变得复杂时会发生什么?就像歌曲 B 的例子一样,当机器学习进入时,它会学习数据,建立预测模型,当新的数据点进来时,它可以很容易地预测它。数据越多,模型越好,精度越高。
机器学习的方式有很多,它可以是监督学习、无监督学习或强化学习。

监督学习
让我们首先快速了解监督学习。假设你的朋友给你 100 万个三种不同货币的硬币,比如说一个是 1 欧元,一个是 1 欧尔,每个硬币有不同的重量,例如,一枚 1 卢比的硬币重 3 克, 一欧元重 7 克,一欧尔重 4 克,你的模型将预测硬币的货币。在这里,体重成为硬币的特征,而货币成为标签,当你将这些数据输入机器学习模型时,它会学习哪个特征与哪个结果相关联。

例如,它将了解到,如果一枚硬币是三克,它将是一枚卢比硬币。根据新硬币的重量,你的模型将预测货币。因此,监督学习使用标签数据来训练模型。在这里,机器知道对象的特征以及与这些特征相关的标签。

无监督学习
在这一点上,让我们看看与无监督学习的区别。假设你有不同球员的板球数据集。当您将此数据集送给机器时,机器会识别玩家性能的模式,因此它会在 x 轴上使用各自的 Achatz 对这些数据进行处理,同时在 y 轴上运行 在查看数据时,你会清楚地看到有两个集群,一个集群是得分高,分较少的球员,而另一个集群是得分较少但得分较多的球员,所以在这里我们将这两个集群解释为击球手和投球手。 需要注意的重要一点是,这里没有击球手、投球手的标签,因此 使用无标签数据的学习是无监督学习。因此,我们了解了数据被标记的监督学习和数据未标记的无监督学习。

强化学习
然后是强化学习,这是一种基于奖励的学习,或者我们可以说它的工作原理是反馈。
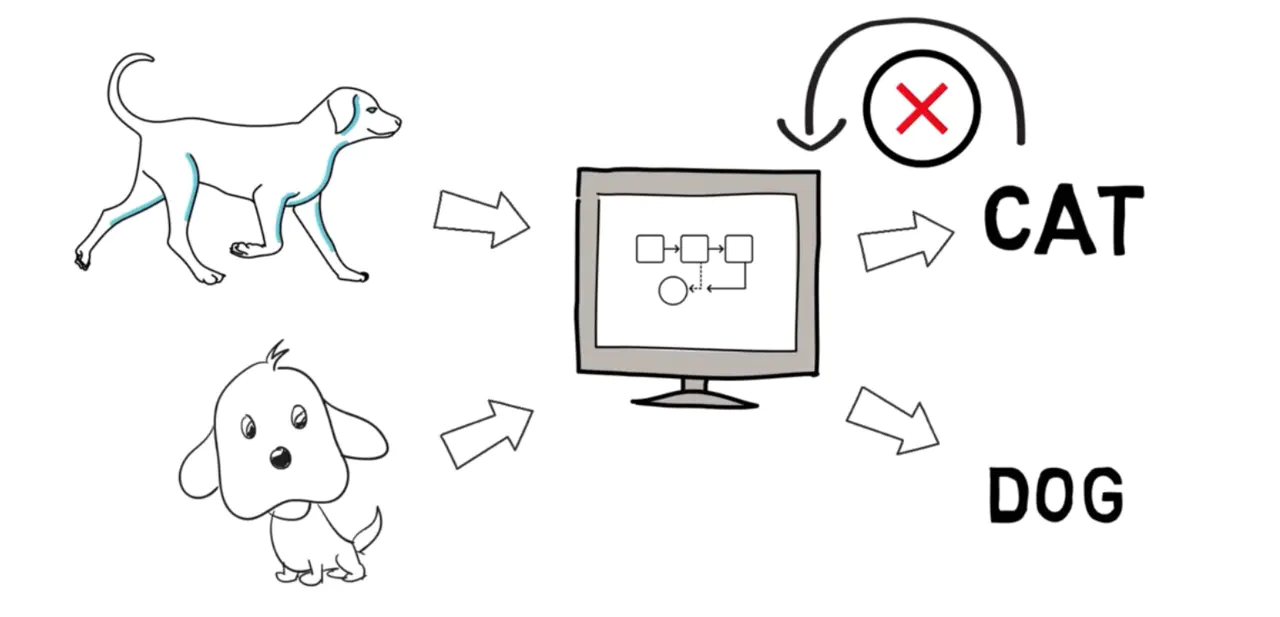
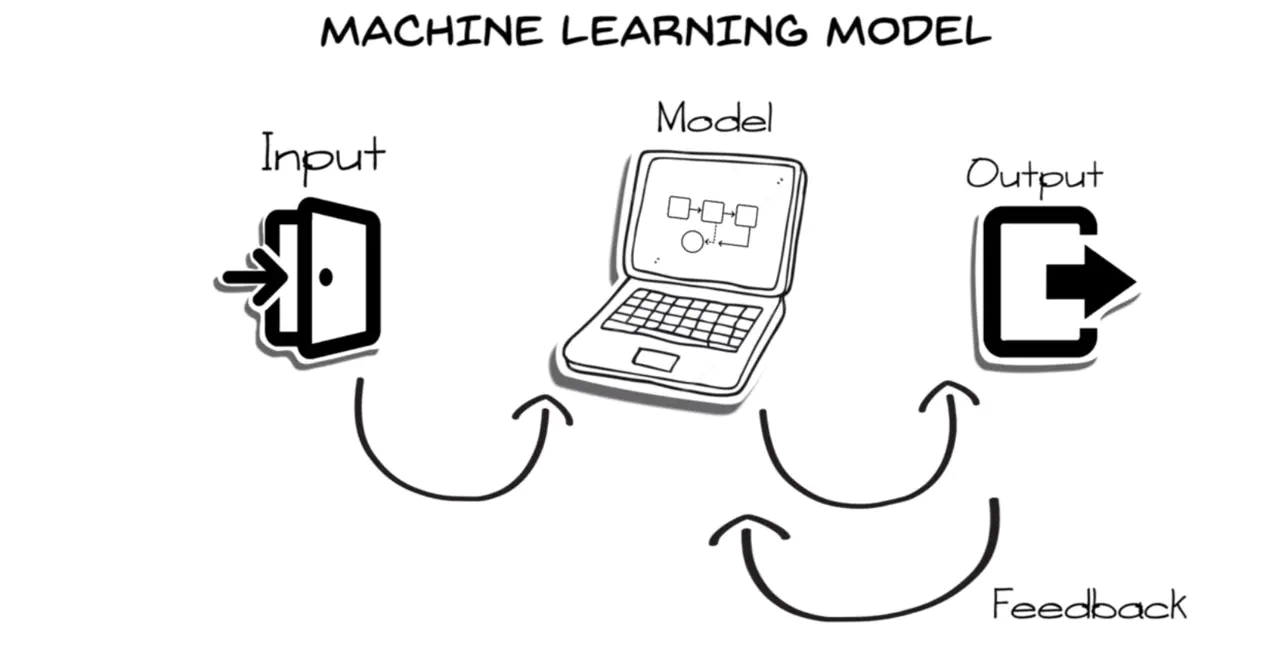
在这里,假设你向系统提供了一只狗的图像,并要求它识别它。系统将它识别为一只猫,所以你给机器一个负面反馈,说它是狗的形象,机器会从反馈中学习。最后,如果它遇到任何其他狗的图像,它将能够正确分类,那就是强化学习。 让我们看一个流程图,输入给机器学习模型,然后根据应用的算法给出输出。如果是正确的,我们将输出作为最终结果,否则我们会向火车模型提供反馈,并要求它预测,直到它学
你有时不知道在当今时代,机器学习是如何成为可能的,那是因为今天我们有大量可用的数据,每个人都在线,要么进行交易,要么上网,每分钟都会产生大量数据,数据是分析的关键。 此外,计算机的内存处理能力也在很大程度上增加,这有助于他们毫不拖延地处理手头如此大量的数据。 是的,计算机现在拥有强大的计算能力,所以有很多机器学习的应用。 仅举几例,机器学习用于医疗保健,在医疗保健中,医生可以预测诊断,情绪分析。
科技巨头在社交媒体上所做的推荐是另一个有趣的应用。金融部门的机器学习欺诈检测,并预测电子商务部门的客户流失。

我希望你已经理解了监督和无监督学习,所以让我们做一个快速测验,确定给定的场景是使用监督还是非监督学习。

场景 1: Facebook 在一张标签照片相册中的照片中识别你的朋友解释: 这是监督学习。在这里,Facebook 正在使用标记的照片来识别这个人。因此,标记的照片成为图片的标签,我们知道当机器从标记的数据中学习时,它是监督学习。
场景 2: 根据某人过去的音乐选择推荐新歌解释: 这是监督学习。该模型是在预先存在的标签 (歌曲流派) 上训练分类器。这是 Netflix,Pandora 和 Spotify 一直在做的事情,他们收集您已经喜欢的歌曲/电影,根据您的喜好评估功能,然后根据类似功能推荐新电影/歌曲。
场景 3: 分析可疑交易的银行数据并标记欺诈交易解释: 这是无监督学习。在这种情况下,可疑交易没有定义,因此没有 “欺诈” 和 “非欺诈” 的标签。该模型试图通过查看异常交易来识别异常值,并将其标记为 “欺诈”。
