
文章目录:
6.图
6.1 基本概念
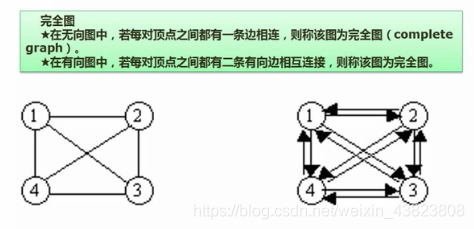
6.2 图的存储
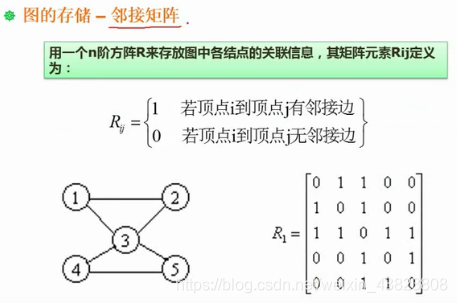
6.2.1 邻接矩阵
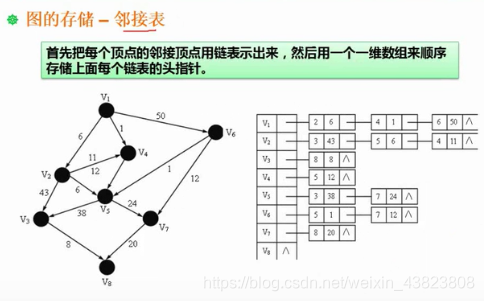
6.2.2 邻接表
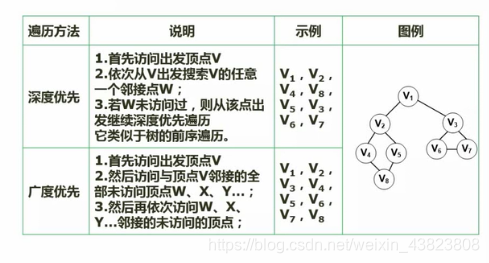
6.3 图的遍历
6.4 拓扑排序
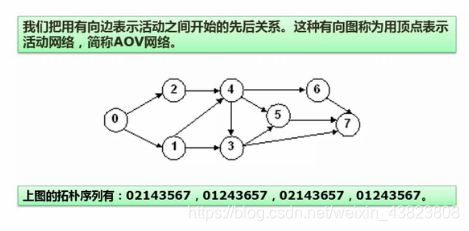
上图的拓扑排序序列除了这四种,还有:01246357、02146357。可见,对于同一张图的拓扑序列是不唯一的!!!
6.5 最小生成树
6.5.1 普里姆算法(以顶点为中心,适合稠密图)

我们首先从顶点A出发,找到与A相连的所有边的最小值,即A→B:100,将这条边加进来,此时最小生成树中有A、B两个结点;之后,我们再将与A、B两个结点相连的所有边中的最小值加进来,可以看到应该是A→E:200,此时最小生成树中有A、B、E三个结点;不断重复上述这样的步骤,直到遍历图中的所有结点,最终得到的就是普里姆算法的最小生成树。
(注意:求解最小生成树的过程中,一定不能产生环路!!!例如上图中,当我们将结点F和D都加进来之后,下来要寻找与这些结点相连的所有边中的最小值,可以看到F→B:300,D→C:300,但是如果我们选择F→B这条路径,那么就产生了环路:A→F→B→A,这是错误的!!!所以只能选择D→C)(图中的1、2、3、4、5表示加入这条边的顺序,冒号后面的是对应边的具体值)
6.5.2 克鲁斯卡尔算法(以边为中心,适合稀疏图)
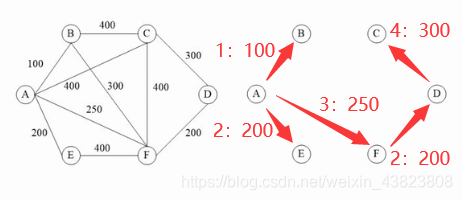
我们纵观图中的所有边,首先选出最小的一条边,也就是A→B:100,此时最小生成树中有A、B两个结点;之后再从图中找出值最小的边,可以看到有两条A→E:200、F→D:200,加进来这两条边之后,并没有产生环路的现象,所以可以加入,此时最小生成树中有A、B、E、F、D这些结点;接下来,继续寻找值最小的边,应该时A→F:250,将其加入;最后因为不能产生环路,所以只能添加值最小的边D→C:300。至此,已遍历全图的顶点。(图中的1、2、3、4表示加入这条边的顺序,冒号后面的是对应边的具体值)
7.排序与查找
7.1 查找
7.1.1 顺序查找与二分查找


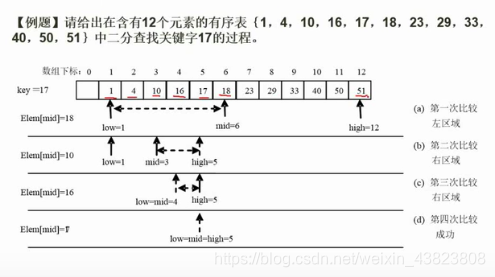
我们看上面这个例题,使用二分查找关键字17,具体过程如下:👇👇👇
①
=6,所以定位到数组下标为6的元素的位置,比较得17<18,可知关键字在前半部分[1,5]。
②
③
④此时二分查找的区间只剩一个元素,即第五个元素17,比较得17=17,所以查找成功。(一共进行了4次比较)
二分查找在查找成功时,关键字得比较次数最多为:
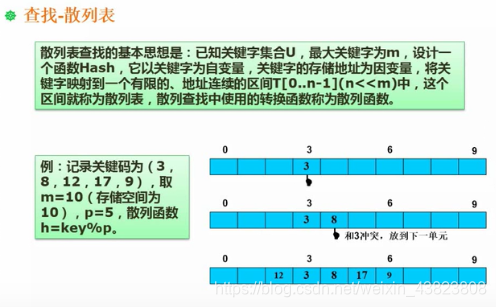
7.1.2 散列表
7.2 排序

7.2.1 直接插入排序

7.2.2 希尔排序

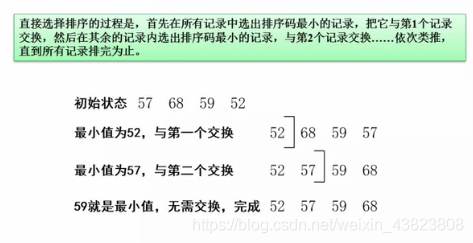
7.2.3 简单选择排序
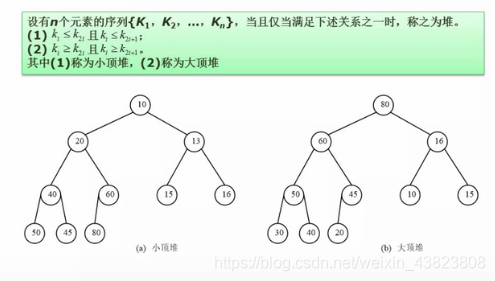
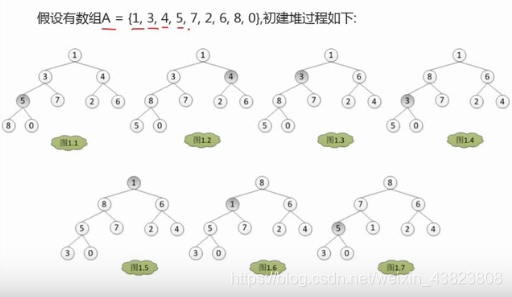
7.2.4 堆排序
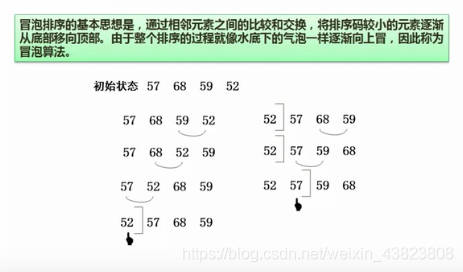
7.2.5 冒泡排序
7.2.6 快速排序

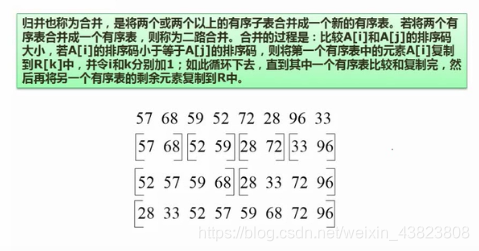
7.2.7 归并排序
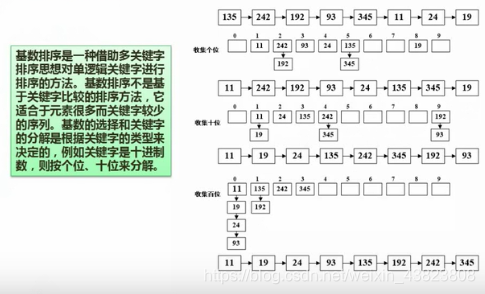
7.2.8 基数排序
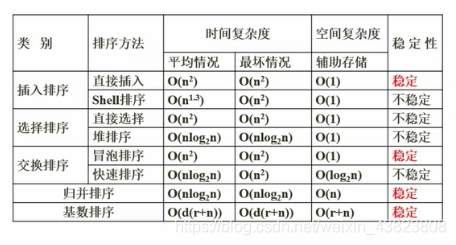
7.2.9 排序算法的时间复杂度、空间复杂度及稳定性
8.算法
8.1 算法的特性

8.2 算法的时间复杂度和空间复杂度


