
在前面的文章中,白日梦曾不止一次的提及到:InnoDB从磁盘中读取数据的最小单位是数据页。
而你想得到的id = xxx的数据,就是这个数据页众多行中的一行。
这篇文章我们就一起来看一下数据行设计的多么巧妙。
一、行 有哪些格式?#
你可以像下面这样看一下你的MySQL行格式设置。
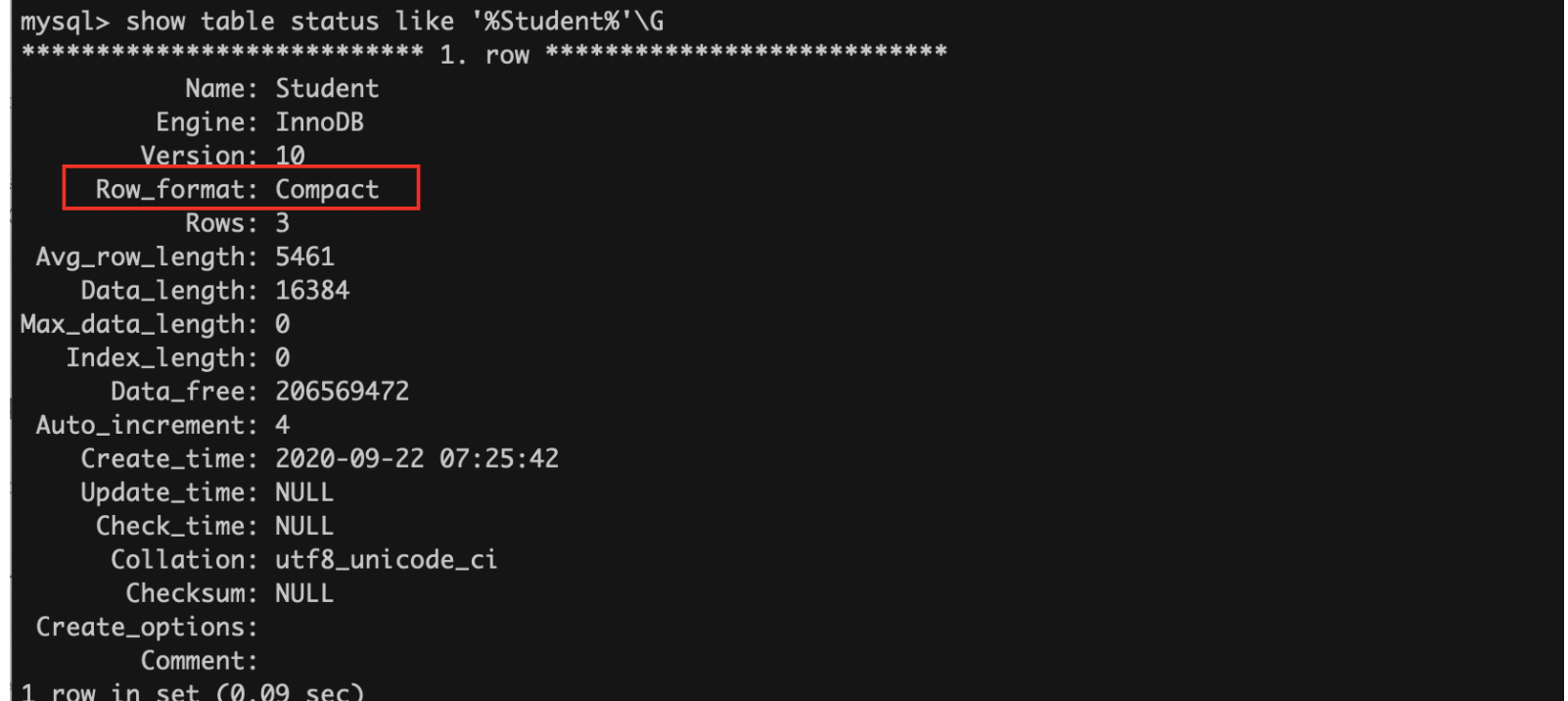
其实MySQL的数据行有两种格式,一种就是图中的 Compact格式,还有一种是Redundant格式。
Compact是一种紧凑的行格式,设计的初衷就是为了让一个数据页中可以存放更多的数据行。
你品一品,让一个数据页中可以存放更多的数据行是一个多么激动人心的事,MySQL以数据页为单位从磁盘中读数据,如果能做到让一个数据页中有更多的行,那岂不是使用的空间变少了,且整体的效率直线飙升?
官网介绍:Compact能比Redundant格式节约20%的存储。
Compact从MySQL5.0引入,MySQL5.1之后,行格式默认设置成 Compact 。所以本文描述的也是Compact格式。
二、紧凑的行格式长啥样?#
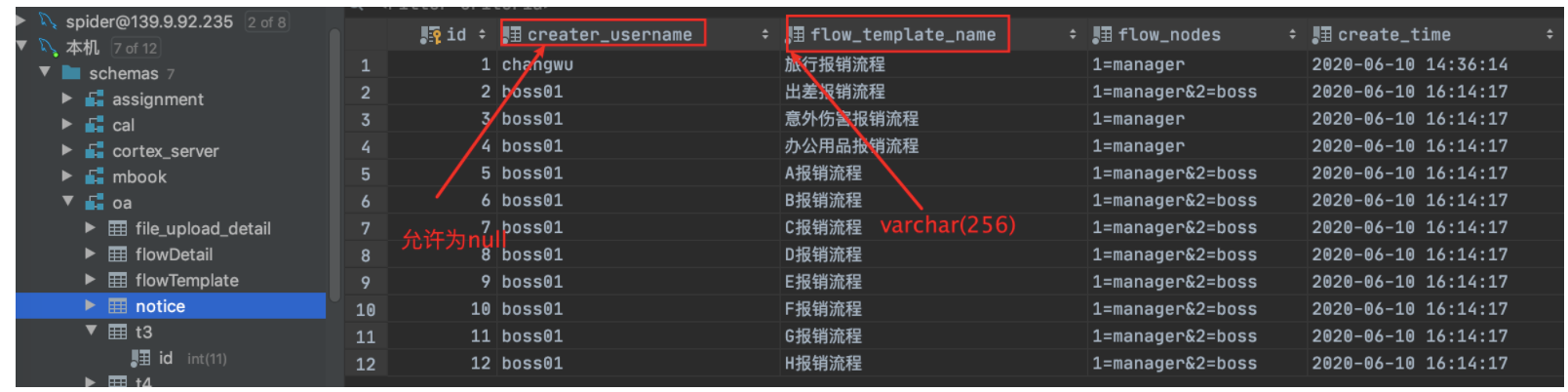
你肯定晓得表中有的列允许为null,有的列是变长的varchar类型。
那Compact行格式是如何组织描述这些信息的呢?如下图:
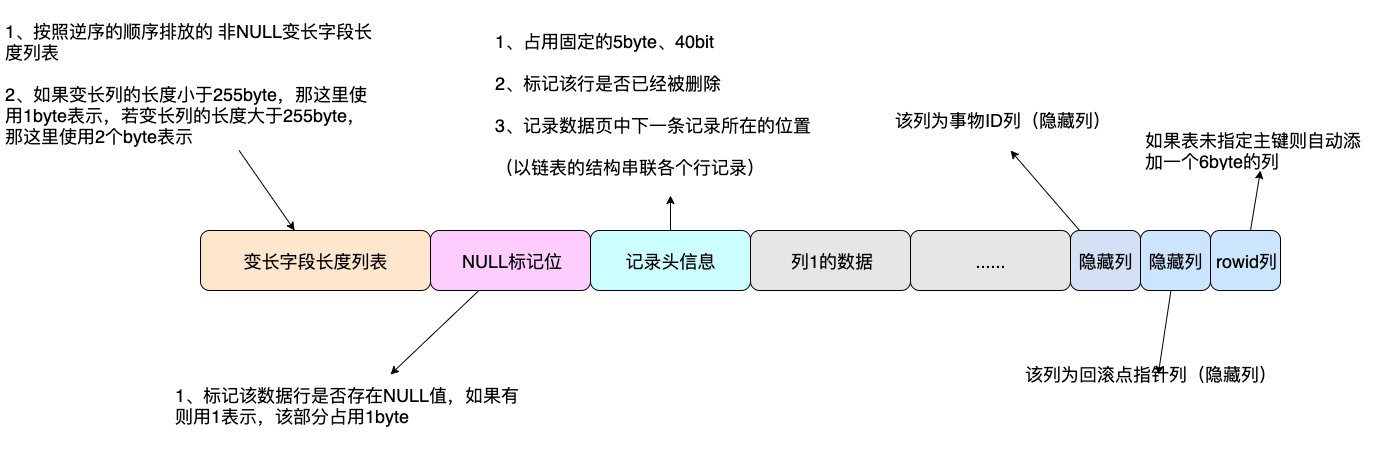
每部分包含的数据可能要比我上面标注的1、2、3还要多。
为了给大家更直观的感受和理解我只是挑了一部分展示给大家看。
三、MySQL单行能存多大体量的数据?#
在MySQL的设定中,单行数据最大能存储65535byte的数据(注意是byte,而不是字符)
但是当你像下面这样创建一张数据表时却发生了错误:

MySQL不允许创建一个长度为65535byte的列,因为数据页中每一行中都有我们上图提到的隐藏列。
所以将varchar的长度降低到65532byte即可成功创建该表

注意这里的65535指的是字节,而不是字符。
所以如果你将charset换成utf8这种编码格式,那varchar(N)中的N其实指的N个字符,而不是N个byte。所以如果你像下面这样创建表就会报错。

假如encode=utf8时三个byte表示一个字符。那么65535 / 3 = 21845个字符。
四、Compact格式是如何做到紧凑的?#
MySQL每次进行随机的IO读
默认情况下,数据页的大小为16KB。数据页中存储着数行。
那就意味着一个数据页中能存储越多的数据行,MySQL整体的进行的IO次数就越少?性能就越快?
Compact格式的实现思路是:当列的类型为VARCHAR、 VARBINARY、 BLOB、TEXT时,该列超过768byte的数据放到其他数据页中去。
如下图:
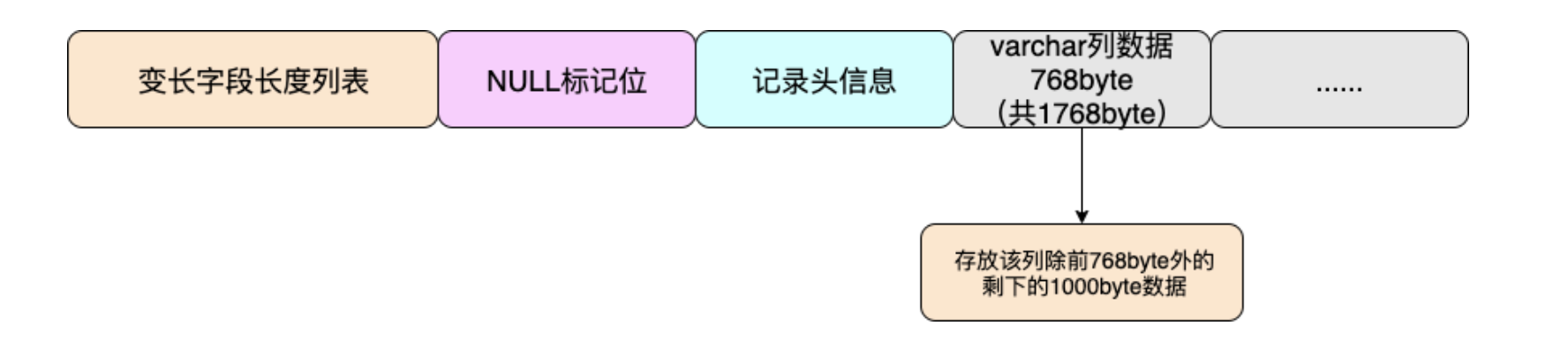
看到这里来龙去脉是不是很清晰了呢?
MySQL这样做,有效的防止了单个varchar列或者Text列太大导致单个数据页中存放的行记录过少而让IO飙升的窘境且占内存的。
五、什么是行溢出?#
那什么是行溢出呢?
如果数据页默认大小为16KB,换算成byte: 16*1024 = 16384 byte
那你有没有发现,单页能存储的16384byte和单行最大能存储的 65535byte 差了好几倍呢?
也就是说,假如你要存储的数据行很大超过了65532byte那么你是写入不进去的。假如你要存储的单行数据小于65535byte但是大于16384byte,这时你可以成功insert,但是一个数据页又存储不了你插入的数据。这时肯定会行溢出!
其实在MySQL的设定中,发生行溢出并不是达到16384byte边缘才会发生。
对于varchar、text等类型的行。当这种列存储的长度达到几百byte时就会发生行溢。
六、行 如何溢出?#
还是看这张图:
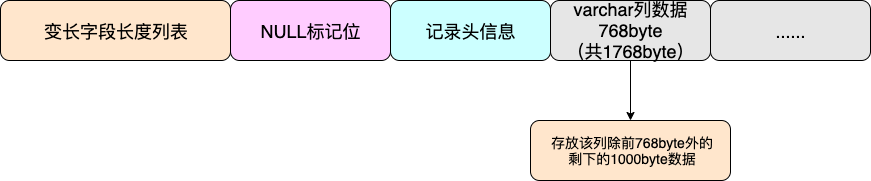
在MySQL设定中,当varchar列长度达到768byte后,会将该列的前768byte当作当作prefix存放在行中,多出来的数据溢出存放到溢出页中,然后通过一个偏移量指针将两者关联起来,这就是行溢出机制。
七、思考一个问题#
不知道你有没有想过这样一个问题:
首先你肯定知道,MySQL使用的是B+Tree的聚簇索引,在这棵B+Tree中非叶子节点是只存索引不存数据,叶子节点中存储着真实的数据。同时叶子结点指向数据页。
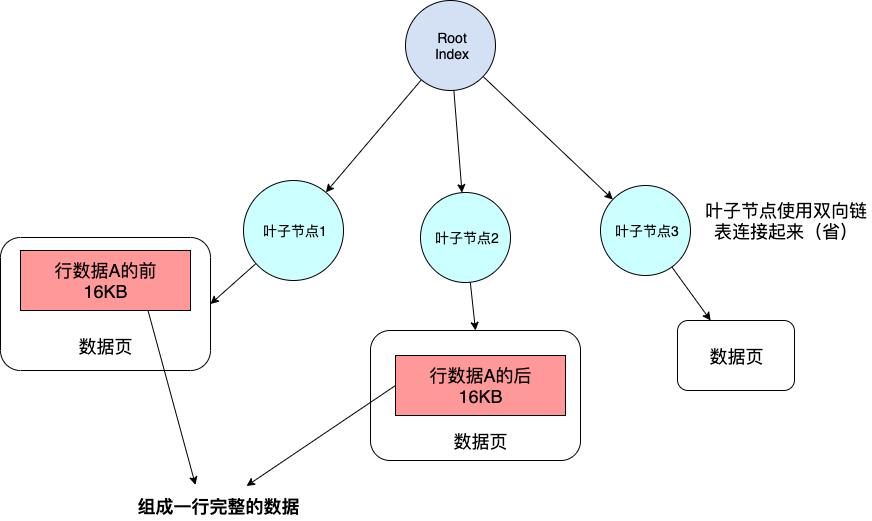
那当单行存不下的时候,为啥不存储在两个数据页中呢?就像下图这样~。
单个节点存储下,我用多个节点存总行吧!说不定这样我的B+Tee还能变大长高(这其实是错误的想法)
这个错误的描述对应的脑图如下:
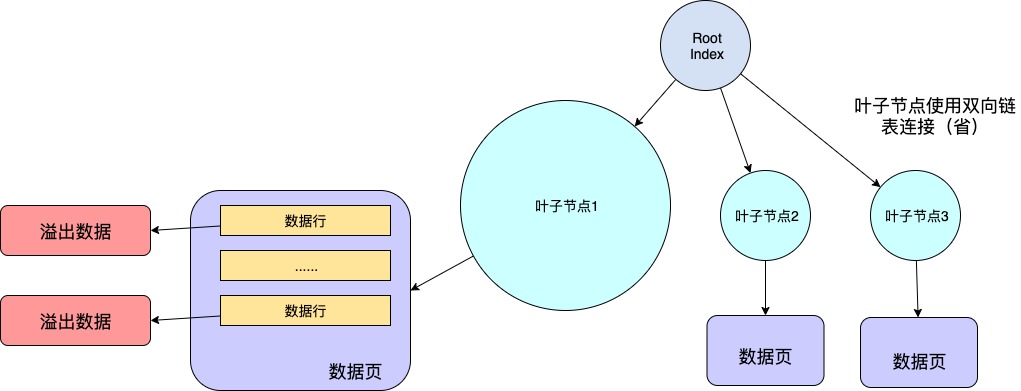
那MySQL不这样做的原因如下:
MySQL想让一个数据页中能存放更多的数据行,至少也得要存放两行数据。否则就失去了B+Tree的意义。B+Tree也退化成一个低效的链表。
你可以品一下这句蓝色的话,他说的每个数据页至少要存放两行数据的意思不是说 数据页不能只存一行。你确确实实可以只往里面写一行数据,然后去吃个饭,干点别的。一直让这个数据页中只有一行数据。
这句话的意思是,当你往这个数据页中写入一行数据时,即使它很大将达到了数据页的极限,但是通过行溢出机制。依然能保证你的下一条数据还能写入到这个数据页中。
正确的脑图如下:
参考:
https://dev.mysql.com/doc/refman/5.7/en/innodb-row-format.html
https://dev.mysql.com/doc/refman/5.7/en/column-count-limit.html
推荐阅读#
- 大家常说的基数是什么?(已发布)
- 讲讲什么是慢查!如何监控?如何排查?(已发布)
- 对NotNull字段插入Null值有啥现象?(已发布)
- 能谈谈 date、datetime、time、timestamp、year的区别吗?(已发布)
- 了解数据库的查询缓存和BufferPool吗?谈谈看!(已发布)
- 你知道数据库缓冲池中的LRU-List吗?(已发布)
- 谈谈数据库缓冲池中的Free-List?(已发布)
- 谈谈数据库缓冲池中的Flush-List?(已发布)
- 了解脏页刷回磁盘的时机吗?(已发布)
- 用十一张图讲清楚,当你CRUD时BufferPool中发生了什么!以及BufferPool的优化!(已发布)
- 听说过表空间没?什么是表空间?什么是数据表?(已发布)
- 谈谈MySQL的:数据区、数据段、数据页、数据页究竟长什么样?了解数据页分裂吗?谈谈看!(已发布)
- 谈谈MySQL的行记录是什么?长啥样?(已发布)
- 了解MySQL的行溢出机制吗?(已发布)
- 说说fsync这个系统调用吧! (已发布)
- 简述undo log、truncate、以及undo log如何帮你回滚事物! (已发布)
- 我劝!这位年轻人不讲MVCC,耗子尾汁! (已发布)
- MySQL的崩溃恢复到底是怎么回事? (已发布)
- MySQL的binlog有啥用?谁写的?在哪里?怎么配置 (已发布)
- MySQL的bin log的写入机制 (已发布)


