Created by Wang, Jerry, last modified on Aug 16, 2015
./spark-class org.apache.spark.deploy.worker.Worker spark://NKGV50849583FV1:7077
NKGV50849583FV1:~/devExpert/spark-1.4.1/bin # ./spark-class org.apache.spark.deploy.worker.Worker spark://NKGV50849583FV1:7077
added by Jerry: loading load-spark-env.sh !!!1
added by Jerry:…
/root/devExpert/spark-1.4.1/conf
added by Jerry, number of Jars: 1
added by Jerry, launch_classpath: /root/devExpert/spark-1.4.1/assembly/target/scala-2.10/spark-assembly-1.4.1-hadoop2.4.0.jar
added by Jerry,RUNNER:/usr/jdk1.7.0_79/bin/java
added by Jerry, printf argument list: org.apache.spark.deploy.worker.Worker spark://NKGV50849583FV1:7077
added by Jerry, I am in if-else branch: /usr/jdk1.7.0_79/bin/java -cp /root/devExpert/spark-1.4.1/conf/:/root/devExpert/spark-1.4.1/assembly/target/scala-2.10/spark-assembly-1.4.1-hadoop2.4.0.jar:/root/devExpert/spark-1.4.1/lib_managed/jars/datanucleus-rdbms-3.2.9.jar:/root/devExpert/spark-1.4.1/lib_managed/jars/datanucleus-core-3.2.10.jar:/root/devExpert/spark-1.4.1/lib_managed/jars/datanucleus-api-jdo-3.2.6.jar -Xms512m -Xmx512m -XX:MaxPermSize=256m org.apache.spark.deploy.worker.Worker spark://NKGV50849583FV1:7077
Using Spark’s default log4j profile: org/apache/spark/log4j-defaults.properties
15/08/16 12:55:28 INFO Worker: Registered signal handlers for [TERM, HUP, INT]
15/08/16 12:55:28 WARN Utils: Your hostname, NKGV50849583FV1 resolves to a loopback address: 127.0.0.1; using 10.128.184.131 instead (on interface eth0)
15/08/16 12:55:28 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
15/08/16 12:55:29 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
15/08/16 12:55:29 INFO SecurityManager: Changing view acls to: root
15/08/16 12:55:29 INFO SecurityManager: Changing modify acls to: root
15/08/16 12:55:29 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); users with modify permissions: Set(root)
15/08/16 12:55:30 INFO Slf4jLogger: Slf4jLogger started
15/08/16 12:55:30 INFO Remoting: Starting remoting
15/08/16 12:55:30 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkWorker@10.128.184.131:42568]
15/08/16 12:55:30 INFO Utils: Successfully started service ‘sparkWorker’ on port 42568.
15/08/16 12:55:30 INFO Worker: Starting Spark worker 10.128.184.131:42568 with 8 cores, 30.4 GB RAM
15/08/16 12:55:30 INFO Worker: Running Spark version 1.4.1
15/08/16 12:55:30 INFO Worker: Spark home: /root/devExpert/spark-1.4.1
15/08/16 12:55:30 INFO Utils: Successfully started service ‘WorkerUI’ on port 8081.
15/08/16 12:55:30 INFO WorkerWebUI: Started WorkerWebUI at http://10.128.184.131:8081
15/08/16 12:55:30 INFO Worker: Connecting to master akka.tcp://sparkMaster@NKGV50849583FV1:7077/user/Master…
15/08/16 12:55:30 INFO Worker: Successfully registered with master spark://NKGV50849583FV1:7077
If I quit the worker session,

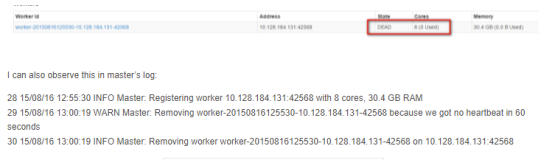
I can also observe this in master’s log:
28 15/08/16 12:55:30 INFO Master: Registering worker 10.128.184.131:42568 with 8 cores, 30.4 GB RAM
29 15/08/16 13:00:19 WARN Master: Removing worker-20150816125530-10.128.184.131-42568 because we got no heartbeat in 60 seconds
30 15/08/16 13:00:19 INFO Master: Removing worker worker-20150816125530-10.128.184.131-42568 on 10.128.184.131:42568