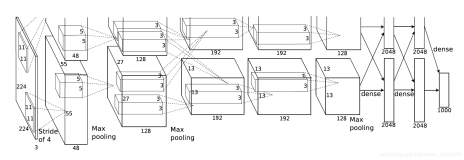
COCO数据集的简介
MS COCO的全称是Microsoft Common Objects in Context,起源于微软于2014年出资标注的Microsoft COCO数据集,与ImageNet竞赛一样,被视为是计算机视觉领域最受关注和最权威的比赛之一。
COCO数据集是一个大型的、丰富的物体检测,分割和字幕数据集。这个数据集以scene understanding为目标,主要从复杂的日常场景中截取,图像中的目标通过精确的segmentation进行位置的标定。图像包括91类目标,328,000影像和2,500,000个label。目前为止有语义分割的最大数据集,提供的类别有80 类,有超过33 万张图片,其中20 万张有标注,整个数据集中个体的数目超过150 万个。
0、COCO数据集的80个类别—YoloV3算法采用的数据集
person(人)
bicycle(自行车) car(汽车) motorbike(摩托车) aeroplane(飞机) bus(公共汽车) train(火车) truck(卡车) boat(船)
traffic light(信号灯) fire hydrant(消防栓) stop sign(停车标志) parking meter(停车计费器) bench(长凳)
bird(鸟) cat(猫) dog(狗) horse(马) sheep(羊) cow(牛) elephant(大象) bear(熊) zebra(斑马) giraffe(长颈鹿)
backpack(背包) umbrella(雨伞) handbag(手提包) tie(领带) suitcase(手提箱)
frisbee(飞盘) skis(滑雪板双脚) snowboard(滑雪板) sports ball(运动球) kite(风筝) baseball bat(棒球棒) baseball glove(棒球手套) skateboard(滑板) surfboard(冲浪板) tennis racket(网球拍)
bottle(瓶子) wine glass(高脚杯) cup(茶杯) fork(叉子) knife(刀)
spoon(勺子) bowl(碗)
banana(香蕉) apple(苹果) sandwich(三明治) orange(橘子) broccoli(西兰花) carrot(胡萝卜) hot dog(热狗) pizza(披萨) donut(甜甜圈) cake(蛋糕)
chair(椅子) sofa(沙发) pottedplant(盆栽植物) bed(床) diningtable(餐桌) toilet(厕所) tvmonitor(电视机)
laptop(笔记本) mouse(鼠标) remote(遥控器) keyboard(键盘) cell phone(电话)
microwave(微波炉) oven(烤箱) toaster(烤面包器) sink(水槽) refrigerator(冰箱)
book(书) clock(闹钟) vase(花瓶) scissors(剪刀) teddy bear(泰迪熊) hair drier(吹风机) toothbrush(牙刷)
1、COCO数据集的意义
MS COCO的全称是Microsoft Common Objects in Context,起源于是微软于2014年出资标注的Microsoft COCO数据集,与ImageNet 竞赛一样,被视为是计算机视觉领域最受关注和最权威的比赛之一。
当在ImageNet竞赛停办后,COCO竞赛就成为是当前目标识别、检测等领域的一个最权威、最重要的标杆,也是目前该领域在国际上唯一能汇集Google、微软、Facebook以及国内外众多顶尖院校和优秀创新企业共同参与的大赛。
该数据集主要解决3个问题:目标检测,目标之间的上下文关系,目标的2维上的精确定位。COCO数据集有91类,虽然比ImageNet和SUN类别少,但是每一类的图像多,这有利于获得更多的每类中位于某种特定场景的能力,对比PASCAL VOC,其有更多类和图像。
1、COCO目标检测挑战
COCO数据集包含20万个图像;
80个类别中有超过50万个目标标注,它是最广泛公开的目标检测数据库;
平均每个图像的目标数为7.2,这些是目标检测挑战的著名数据集。
2、COCO数据集的特点
COCO is a large-scale object detection, segmentation, and captioning dataset. COCO has several features:
Object segmentation
Recognition in context
Superpixel stuff segmentation
330K images (>200K labeled)
1.5 million object instances
80 object categories
91 stuff categories
5 captions per image
250,000 people with keypoints
对象分割;
在上下文中可识别;
超像素分割;
330K图像(> 200K标记);
150万个对象实例;
80个对象类别;
91个类别;
每张图片5个字幕;
有关键点的250,000人;
3、数据集的大小和版本
大小:25 GB(压缩)
记录数量: 330K图像、80个对象类别、每幅图像有5个标签、25万个关键点。
COCO数据集分两部分发布,前部分于2014年发布,后部分于2015年,2014年版本:82,783 training, 40,504 validation, and 40,775 testing images,有270k的segmented people和886k的segmented object;2015年版本:165,482 train, 81,208 val, and 81,434 test images。
(1)、2014年版本的数据,一共有20G左右的图片和500M左右的标签文件。标签文件标记了每个segmentation的像素精确位置+bounding box的精确坐标,其精度均为小数点后两位。
COCO数据集的下载
官网地址:http://cocodataset.org/#download
1、2014年数据集的下载
train2014:http://images.cocodataset.org/zips/train2014.zip
val2014:http://images.cocodataset.org/zips/val2014.zip
http://msvocds.blob.core.windows.net/coco2014/train2014.zip
2、2017的数据集的下载
http://images.cocodataset.org/zips/train2017.zip
http://images.cocodataset.org/annotations/annotations_trainval2017.zip
http://images.cocodataset.org/zips/val2017.zip
http://images.cocodataset.org/annotations/stuff_annotations_trainval2017.zip
http://images.cocodataset.org/zips/test2017.zip
http://images.cocodataset.org/annotations/image_info_test2017.zip
train2017
train2017:http://images.cocodataset.org/zips/train2017.zip
train2017 annotations:http://images.cocodataset.org/annotations/annotations_trainval2017.zip
val2017
val2017:http://images.cocodataset.org/zips/val2017.zip
val2017 annotations:http://images.cocodataset.org/annotations/stuff_annotations_trainval2017.zip
test2017
test2017:http://images.cocodataset.org/zips/test2017.zip
test2017 info:http://images.cocodataset.org/annotations/image_info_test2017.zip
COCO数据集的使用方法
1、基础用法
(1)、Download Images and Annotations from [MSCOCO] 后期更新……
(2)、Get the coco code 后期更新……
(3)、Build the coco code 后期更新……
(4)、Split the annotation to many files per image and get the image size info 后期更新……
(5)、 Create the LMDB file 后期更新……