
背景
微服务架构带来很多好处的同时也让系统的复杂度提升了,传统的单体应用按照不同的维度拆分成一个一个分布式微服务,不同的微服务甚至可能采用不同的语言编写;此外,服务的部署往往都是分布式的,可能有几千台服务器,横跨多个不同的城市数据中心。下图是一个典型的微服务架构,图中的节点数还比较少,在支付宝,一个线下支付整体交易付款链路,涉及上百个节点。

微服务化引入了以下几个典型问题:
- 故障定位难,一次请求往往需要涉及到多个服务,排查问题甚至需要拉上多个团队
- 完整调用链路梳理难,节点调用关系分析
- 性能分析难,性能短板节点
以上这几个问题其实都是应用的可观测性问题:
- log
- Trace
- metrics
本文将会专注于 Trace 方面,完整地说是分布式链路跟踪 (Distributed tracing)。2010 年谷歌发表了 Dapper 的论文,分享了他们的解决方案,算是业界比较早的分布式链路追踪系统。之后各大互联网公司纷纷参照 Dapper 的思想推出各自的链路跟踪系统,包括 Twitter 的 Zipkin、阿里的鹰眼,还有 PinPoint,Apache 的 HTrace 和 Uber 的 Jaeger;当然,也有我们的本文的主角:SOFATracer。分布式链路的实现有多种多样,因此也催生了分布式链路追踪的规范:OpenTracing,2019 年 OpenTracing 和 OpenCensus 合并成为了 OpenTelemetry。
OpenTracing
在深入 SOFATracer 之前先简单解释一下 OpenTracing,因为 SOFATTracer 是基于 OpenTracing 规范(基于 0.22.0 的 OpenTracing,新版的规范 API 有所不同)构建的。一个 Trace 由服务调用生成的 Span 及其之间的引用构成,一个 Span 是一个时间跨度,一次服务调用创建一个新 Span,分为调用 Span 和被调 Span,每个 Span 包含:
- TraceId and SpanId
- 操作名称
- 耗时
- 服务调用结果
一个 Trace 链路中一般会有多个服务调用,那么也就会有多个 Span,Span 之间的关系由引用声明,引用从调用者指向服务提供者,OpenTracing 中指定了两个引用类型:
- ChildOf,同步服务调用,客户端需要服务端的结果返回才能进行后续处理;
- FollowsFrom,异步服务调用,客户端不等待服务端结果。
一个 Trace 是一个有向无环图,一次调用的拓扑可以如下展示:

图中的 SpanContext 是一次请求中会共享的数据,因此叫做 Span 上下文,一个服务节点在上下文中放入的数据对于后续的所有节点都可见,因此可以用来做信息传递。
SOFATracer
TraceId 生成
TraceId 收集一次请求中的所有服务节点。其生成规则需要避免不同 TraceId 之间的冲突,并且开销不能很高,毕竟 Trace 链路的生成是业务逻辑之外的额外开销。SOFATracer 中的 TraceId 生成规则是:服务器 IP + 产生 ID 时候的时间 + 自增序列 + 当前进程号,比如:
0ad1348f1403169275002100356696前 8 位 0ad1348f 即产生 TraceId 的机器的 IP,这是一个十六进制的数字,每两位代表 IP 中的一段,我们把这个数字,按每两位转成 10 进制即可得到常见的 IP 地址表示方式 10.209.52.143,大家也可以根据这个规律来查找到请求经过的第一个服务器。 后面的 13 位 1403169275002 是产生 TraceId 的时间。 之后的 4 位 1003 是一个自增的序列,从 1000 涨到 9000,到达 9000 后回到 1000 再开始往上涨。 最后的 5 位 56696 是当前的进程 ID,为了防止单机多进程出现 TraceId 冲突的情况,所以在 TraceId 末尾添加了当前的进程 ID。

伪代码如下:
TraceIdStr.append(ip).append(System.currentTimeMillis())
append(getNextId()).append(getPID());SpanId 生成
SpanId 记录服务调用拓扑,在 SOFATracer 中:
- 点代表调用深度
- 数字代表调用顺序
- SpanId 由客户端创建
SOFATracer 中 TraceId 和 SpanId 的生成规则参考了阿里的鹰眼组件
合并调用 Span 和被调 Span,结合 TraceId 和 SpanId 就能构建完整的服务调用拓扑:

Trace 埋点
但是,我们如何生成并获取到 Trace 数据呢?这就得 Trace 采集器(Instrumentation Framework)登场了,其负责:
- Trace 数据的生成、传递和上报
- Trace 上下文的解析和注入
并且 Trace 采集器还要做到自动、低侵入和低开销等。典型的 Trace 采集器结构如下,其在业务逻辑之前埋点:

- Server Received (SR), 创建一个新的父 Span 或者从上下文中提取
- 调用业务代码
- 业务代码再次发起远程服务调用
- Client Send (CS) 创建一个子 Span,传递 TraceId、SpanId 和透传数据
- Client Received (CR), 结束当前子 Span,记录/上报 Span
- Server Send (SS) 结束父 Span,记录/上报 Span
步骤 3-5 可能没有,也可能重复多次。
埋点逻辑的实现多种多样,目前主流的有如下几种方式:
- Filter,请求过滤器 (dubbo, SOFARPC, Spring MVC)
- AOP 切面 (DataSource, Redis, MongoDB)
a.Proxy
b.ByteCode generating
- Hook 机制 (Spring Message, RocketMQ)
Java 语言中,SkyWalking 和 PinPoint 都使用 javaagent 方式做到自动、无侵入埋点。典型的,SOFATracer 实现 Spring MVC 的 Trace 埋点如下:

SOFATracer 的 Span 100% 创建,只是 log/report 支持采样,相对来说,log/report 的 overhead 更高,更容易在大流量/负载下成为性能瓶颈。而其他 Trace 系统,Span 是采样生成的,但为了在调用出错的情况下能 100% 有 Trace,他们采用了逆向采样的策略。
SOFATracer 默认把 Trace 信息打印到日志文件中
- client-digest:调用 Span
- server-digest:被调用 Span
- client-stat:一分钟内调用 Span 的数据聚合
- server-stat:一分钟内被调用 Span 的数据聚合
默认日志格式是 JSON,但是可以定制。
APM
一个典型的 Trace 系统,除了 Trace 的采集上报之外,还会有收集器(Collector)、存储(Storage)和展示(API & UI):Application Performance Management,简称 APM,如下图所示:

图片来源:https://pinpoint-apm.github.io/pinpoint/overview.html
Trace 数据上报一般要求包括实时性、一致性等,SOFATracer 默认支持 Zipkin 上报;在存储之前涉及到流式计算,调用 Span 和被调用 Span 的合并,一般采用 Alibaba JStorm 或者 Apache Flink;在处理完成之后会放到 Apache HBase 中,由于 Trace 数据只是短时间有用,因此一般会采取过期数据自动淘汰机制,过期时间一般是 7~10 天左右。最后的展示部分,从 HBase 中查询、分析需要支持:
- 有向无环图的图形化展示
- 按照 TraceId 查询
- 按照调用者查询
- 按照被调用者查询
- 按照 IP 查询

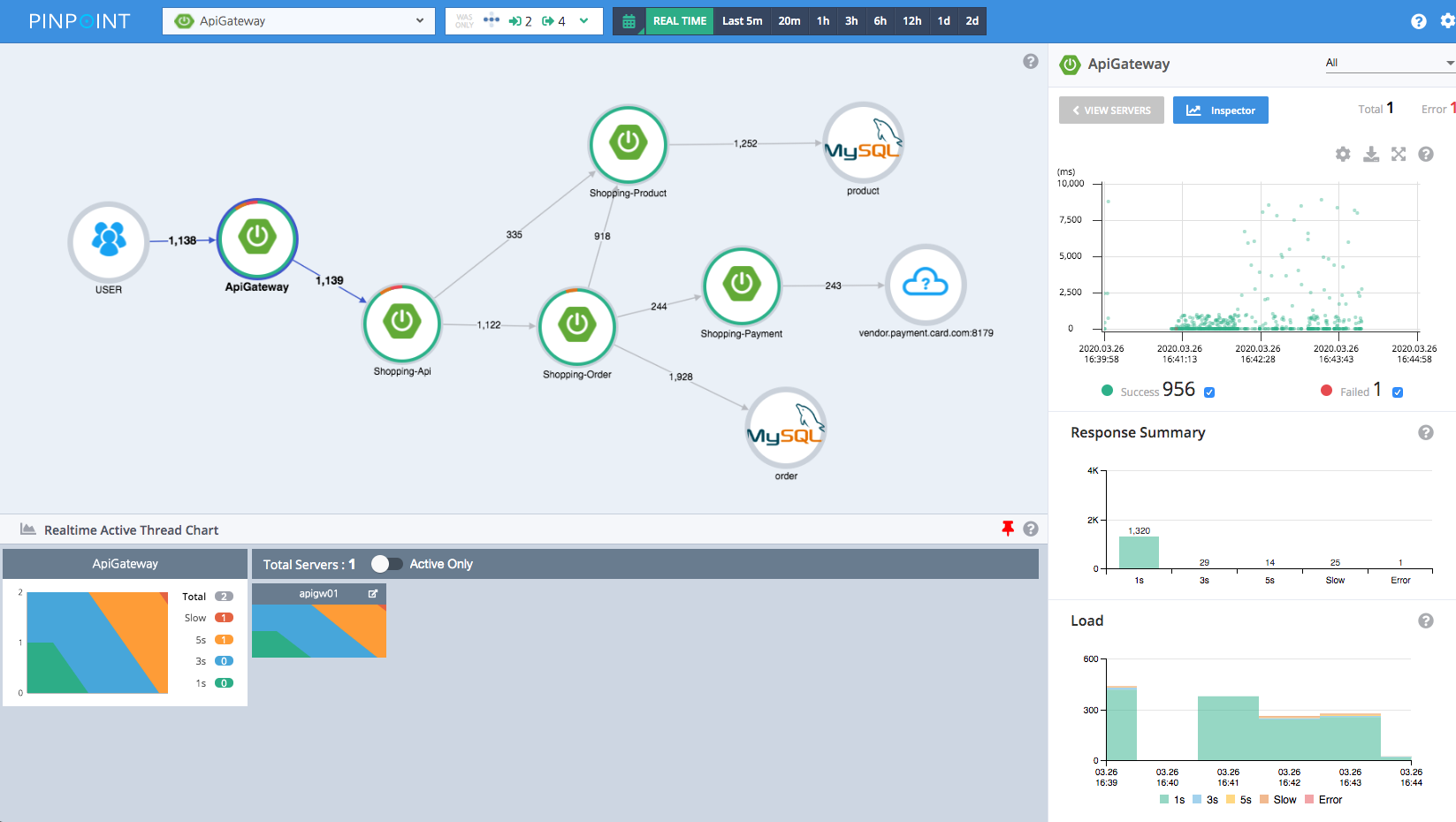
图片来源:https://pinpoint-apm.github.io/pinpoint/images/ss_server-map.png
在蚂蚁集团内部,我们没有采用 Span 上报,而是 Span 打印到日志之后按需采集,其架构如下:

(其中 Relic 和 Antique 不是真实的系统名。)
宿主机上有 DaemonSet Agent 用于采集 Trace 日志,digest 日志用于问题排查 & stat 日志用于业务监控,也就是要采集的日志内容。日志数据采集之后,会经过 Relic 系统处理:单机日志数据清理、聚合;再之后经过 Antique 系统的进一步的整合,通过 Spark 将 Trace 的服务数据做应用和服务纬度的聚合。最后,我们将处理过后的 Trace 数据存到时序数据库 CeresDB 中,提供给 Web Console 查询和分析。这个系统还可以配置监控和报警,以便提前预警应用系统的异常。目前以上监控和报警可以做到准实时,有 1 分钟左右的延迟。
全链路追踪的发展一直在不断完善,功能不断丰富,现阶段涉及到的 Application Performance Management 不仅包含了全链路追踪的的完整能力,还包括:
- 存储 & 分析,丰富的终端特性
- 全链路压测
- 性能剖析
- 监控 & 报警:CPU、内存和 JVM 信息等
在蚂蚁集团内部,我们有专门的压测平台,平台发起压测流量的时候,会自带人为构造的 TraceId、SpanId 和透传数据(压测标志),实现日志分开打印。欢迎选用 SOFATracer 作为全链路追踪工具,SOFATracer 的快速开始指南 Link:

展望
SOFATracer 的未来发展规划如下,欢迎大家参与贡献!项目 Github 链接。

相关链接
SOFATracer Github 项目:https://github.com/sofastack/sofa-Tracer
OpenTracing:https://opentracing.io/
OpenTelemetry:https://opentelemetry.io/
本周推荐阅读
更多文章请扫码关注“金融级分布式架构”公众号





{kind=link}