作者:陈绪(汇量科技资深算法架构师,EnginePlus 2.0 产品负责人)

内容框架:
- 互联网业务视角看湖仓一体
- StarLake 架构实践
- StarLake 业务应用案例
- 未来方向
一、互联网业务视角看湖仓一体
1、数据仓库
- 结构化数据
- 范式建模
- 预设 Schema
- 流批架构复杂
- 计算存储弹性一般
2、数据湖
- 非结构化
- 读取型 Schema
- 流批一体化
- 云原生,天然弹性
- 元数据和对象存储能力持续演进
3、湖仓一体
- 以湖为底座
- 增强元数据扩展性
- 提升云对象存储性能
- 优化宽表实时数据摄入吞吐
- 分析、科学一体化
二、StarLake 架构实践

在我们自己去实践湖仓一体的应用的时候也找了一些业务场景,比如说我们的推荐系统,我们的设备管理、DMP。一些开源的数据湖组件我们也遇到了部分问题,也是这些问题驱动我们重新去设计了一套新的 StarLake 数据湖。
具体来讲解决了这样几类问题,第一个就是 Upsert 的性能,Upsert 要去做实时匡表的插入,每一列每一行有不同的实施流,可能是并发在写。跟一般的 ETL 流程会有比较大的区别,传统的框架可能它这块的性能优化程度是一般的,StarLake 有做专门的设计。
第二块就是元数据的扩展性,他们往往会在一定的量级比如说小文件到亿级别十亿级别,一般会有一些性能的扩展性的问题,针对这块 StarLake 也专门用分布式 DB 的方式做元数据扩展。
第三,对象存储的吞吐性,一般来讲数据湖框架,包括 Hive 这些框架基本不太涉及这块,没有专门为云上对象存储这种场景去考虑。但是我们在设计 StarLake 的时候就知道是要专门为对象存储这种存储介质进行优化,所以我们做了专门的设计去提升对象存储吞吐。
第四,高并发写入,实时匡表多流并发去更新一个表,这就需要支持高频发写入,需要支持 Copy on Write、Merge on Read 这些不同的模式,每种模式下还会有进一步不同的数据分步优化去提升实时摄入的性能。
最后就是我们的一些分区模式,会和查询引擎去进行算子的优化联动。

我们要实现上面提到的我们想去做的优化目标,实际上和现有的数据湖框架架构是有一定的区别的。
以前的数据湖在元数据管理这就是要多版本控制,并发控制。再往下其实还是交给每个计算引擎,他们自身的实现,去读数据写数据。比如说我们要去读一个 Parquet 这样的开发文件格式,一个劣势存储,往下就是走到 Hadoop File Format 这一层抽象。再往下读写 OSS ,这是他们的设计。我们在做 StarLake 设计的时候就发现仅仅元数据这一层是不够的。我们的元数据、查询引擎、查询计划,文件的解析和对象存储这几层需要联动,我们从元数据可以下推一些信息到查询计划,查询计划进一步下推一些东西到文件的读写,最后文件的 IO 这一层直接考虑和对象存储进行预取。这四层,在 StarLake 里面全部做在一起。

首先是基本的数据存储的模型,这一块其实我们做的一个比较有特色的地方就是它支持两种分区模式,这个有点像 Hbase,我们可以同时支持 Hash 分区和 Range 分区。这两个分区可以在一个表里同时存在。不同的分区模式下数据的分布是不一样的。比如说 Hash 分区的时候每一个分片内它都是已经按分片分好了,且在文件内是有序的。这样其实它可以获得非常多的性能提升点。第二个就是我们在增量写的时候,它也是和其他数据湖比较类似,首先第一个版本就是成为基准文件 Base File,接下来增量的我们就是 Delta File ,然后去写入,通过元数据管理形成文件组的形式把它们组织在一起。这样的好处就是我在去增量写入的时候可以有一个比较高的吞吐和并发。
但是数据湖有两种模式,Copy on Write 和 Merge on Read,Copy on Write 它主要是低频更新,Merge on Read 相当于写快但是可能把一些数据合并的开销就推迟到读的时候做。
我们在这一块解决的方式是这样,我们重写了 Merge Scan 的读数据的物理计划层,它会自动去做 Base 文件和 Delta 文件这两个文件的合并,这个可能和其他的数据湖框架不太一样,他们是让计算引擎自己去做。我们其实是在文件的读取层直接做这个事情。比如分区信息,在 Hash 分片内做文件合并的时候,我们做了一个设计叫做 Merge Operator,一般来讲 Upsert 场景有可能是它需要对这个数据进行更新不仅仅是覆盖。比如一个累加池可能一直加,并不仅仅是把老数据直接覆盖掉。这样的一个场景下有个 Merge Operator 允许用户自定义,默认覆盖,也可自定义。自定义的时候就可以实现数值求和或者是字符串拼接等自定义的逻辑,能够节省非常大量的计算资源。所以 Merge Operator 它参考了数据库的实现方式。我们其实是借鉴了传统数据库分析引擎他们做的一些事情。但我们把它做在一个数据湖的框架里面。

有了多级分区之后,Hash 分区在这种场景下我们去做 Upsert 性能会非常快,因为我们去写入的时候,其实开销非常低,只要把 Hash 分片分好,再局部排个序直接写入就可以。它跟历史的数据是没有任何交互的,是纯增量,没有任何历史数据取出写入这样的开销,所以它会非常快。
我们自己测试跟 Iceberg 比,像这种行级别的更新有十倍的提升。因为非常大的性能提升,所以我们非常容易做到支持多流的并发更新。
第二部分是文件格式这一层去和对象存储 OSS 的访问去做联合的优化。OSS 和自建 HDFS 比较大的区别是访问延迟会相对高一点,所以它在原来的像 Hadoop FileSystem 这样的形式下去访问,通常会有比较明显的延迟。所以读数据的时候CPU利用率很低。我们想做的事情就是把读数据和计算重叠起来,不过预取做在文件系统层是不太行的,因为 Parquet 这种格式是劣势的存储,最后在分析的场景可能只读中间某几列,某一个业务查询可能就读一两列。在文件系统这一层不知道如何去 prefetch 这个信息。所以我们是做在 Parquet DataSource 里面。Parquet DataSource 里我们其实已经拿到了所有的下推条件,拿到这些信息之后去做一个并行化的 prefetch 处理。这样提升了性能而且它不会对带宽对 OSS 的访问带来额外的开销,所以在做了这样的优化之后其实在匡表读的场景是有一定提升的,这其实是E2E的测试,单独看中间读的部分是有两到三倍的提升。

接下来展开讲解我们怎么去扩展元数据。以前像 Delta Lake、Iceberg 可能就是更多的是往文件系统里面写一个文件,相当于去记录一个多版本的 Mata,遇到了冲突就去回退和重试,效率相对比较低。大家用数据湖的时候往往有一个问题,小文件多的时候性能可能会急剧下降,因为它要在 OSS 里面要把一堆的小文件用 Mata 扫出来合并,效率特别低。所以为了提升扩展性我们就干脆用一个分布式的数据库做这个事情,我们选择了 Cassandra ,它本身是分布式扩展能力非常强的数据库,数据库里面本身有一个 LWT 轻量级事务的功能,就可以用来实现高并发所需要的 ACID 事务,保证数据的一致性。Cassandra 它的维护管理还是比较容易的,因为它是去中心化数据库的设计。在云上的这种扩容其实会比较方便。
元数据扩展这块其实我们还要进一步去做查询计划联合优化,我们拿到分区信息,比如说有些 Range 的分区、Hash 的分区,这一类的分区其实已经对数据分布进行了提前的组织,组织的信息会下推给查询引擎这一层。比如说在 Spark 执行一个 SQL 查询的时候,会告诉它这个是同一个 Hash 分片的查询,它们天然就可以消除掉 Sort 和 Shuffle 阶段,对 Join、Intersect 这样一类场景会有非常明显的性能提升。
三、StarLake 业务应用案例

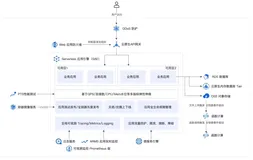
接下来阐述 StarLake 真实的一些应用场景。首先我们自己搭建了一个叫做云原生数据分析智能一体化的平台,我们给它起的名字叫做 EnginePlus 。它构建在完全云原生的架构,计算的部分完全采用容器化的方式去部署,包括所有的计算节点、计算引擎。在存储这一块是完全计算存储分离,完全通过 OSS,在上面用 StarLake 去搭建数据湖加上湖仓一体的能力。我们还集成了一些AI的组件, MindAlpha 这样的云原生的部署,整体的湖仓一体分析和AI一体的平台EnginePlus 2.0,它可以非常快速的去做部署,也能够实现非常好的弹性。

四、未来方向
- Flink Sink
- 更多联合查询优化
- Auto Compaction
- 物化视图、Cache
⭐StarLake 已开源:
https://github.com/engine-plus/StarLake
对数据湖感兴趣的同学欢迎扫码加入数据湖钉钉交流群,不错过每次直播信息、探讨更多数据湖相关技术问题!也欢迎关注数据湖公众号,获取最新相关文章内容~~!