

本文为你介绍,如何从 Waze 交通事件开放数据中,利用序列模型找到规律,进行分类预测。以便相关部门可以未雨绸缪,提前有效干预可能发生的严重拥堵。
寻找
之前在《文科生如何理解循环神经网络(RNN)?》一文中,我为你讲解过循环神经网络的含义。《如何用 Python 和循环神经网络做中文文本分类?》一文,我又为你介绍了如何用循环神经网络对文本做分类。
我不希望给你一种错误的简单关联,即“循环神经网络只能用来处理文本数据”。
事实上,只要是序列数据,你都可以考虑一下循环神经网络。
我一直打算找个其他序列数据的样例,给你展示循环神经网络的更多应用场景。
但是这个数据不太好选择。
目前一个热门的应用场景,就是金融产品的价格预测。
每时每秒,金融产品的价格都在变动。把它汇集起来,是个典型的序列数据。
但是我一直不看好这种应用。因为金融产品的定价,应该是面向未来的。基于历史价格信息寻找波动规律,并对未来价格进行预测,实际上如同看着后视镜开车一般危险。
但是,还有很多人依然乐此不疲地尝试。很多时候,他们也能尝到成功的甜头。
这是为什么?
原因在于,金融市场的参与者,并非理性的机器,而是由人组成的群体。从行为金融学的角度来看,进化给人类思考与行为带来了一些“快捷方式”,你可以利用它们从中渔利。
陆蓉教授的《行为金融学》栏目,对此有详细介绍。
例如,人们追涨杀跌,认为历史会重演;
例如,吸引大众关注到事件,总会带来买入;
例如,人们会倾向于投资于自己熟悉的标的;
例如,人们会购买下跌的已持仓标的,来摊薄成本。
……
如果没有大风浪,这种对市场参与者行为规律的洞察,确实可以帮你赚钱。你可以从价格的历史波动中,挖掘出这些规律的影响。但是这对没有模型可用的人来说,不公平。教你建模,就如同教你考试作弊。
如果遇到黑天鹅事件,其影响大概率会超过市场参与者行为偏误带来的历史价格波动规律。那么你,可能会因为应用模型,而遭遇亏损。你大约不会认为这是自己的错误,而直接把我当做骗子,朝我扔鸡蛋。
理性权衡后,我决定不用金融产品价格趋势分析,作为循环神经网络的应用样例。
其他开放的序列数据,当然也有很多。例如共享单车租用数据、气温变化数据等。
不过这些应用,一来别人都写过了,不新鲜。二来,气温变化,你看天气预报就好了。共享单车租用数量……你真的关心这里的规律吗?
正在我犹豫的时候,一次偶然的机会,我接触到了一个新的序列数据样例——交通事件数据。我觉得,把它作为应用案例分享给你,可能更合适一些。
比赛
拿到这个数据,是因为我参与了一次编程马拉松(hackathon)比赛。
比赛在 Frisco 的 UNT Inspire Park 举办。从早上8点开始,一直到晚上9点多才结束。中间可以自由吃免费提供的点心和水果,也可以到院子里晒晒太阳放放风。大家还可以自由交流和组队。

主办方为参赛者提供了若干种开放数据,也提了一些问题供大家参考解答。当然,实际参赛的时候,你也可以自己拟定新的题目。
这其中,就包括了 Waze 数据。
我在中国开车,平时用的都是高德导航,对于 Waze 这款 App 不大熟悉。
简而言之,这个 Waze 应用除了提供一般的导航功能之外,还有一个类似于众包的功能——让司机们自由提交路况信息。

这样一来,Waze 就利用群体智慧形成了一个眼观六路耳听八方的巨大网络,随时依据用户提供的情况,汇总成实时交通参考。并且汇报给用户,以便于大家调整自己的行车路线。
我觉得最有用的特点是,在堵车的时候,你可以了解到前面究竟发生了什么。其他导航也有实时交通状况提示,但是你对前面的情况一无所知。道路半幅施工?交通事故?
信息的对称,可以在很大程度上,让司机避免焦虑。
Waze 从几年前开始,就和政府部门合作,进行数据开放共享。这样一来,政府可以通过 Waze 的数据了解交通实时状况,对于问题进行快速的响应处理;与此同时, Waze 用户也因为可以获取整合其他相关类型的政府开放数据(例如道路规划等),更加有效合理安排出行。
这次比赛,主办方提供的数据,是 DFW (达拉斯-沃斯堡都会区)区域,11月1日到29日的 Waze 交通事件(Incidents)开放数据,这是政府开放数据的一部分。这些数据基本都是来自于 Waze 用户的提交。
原始的数据,接近 300 MB。每一条事件信息,都包含了提交的经纬度,以及时间。因此在探索性数据分析阶段,我做了几个可视化图形。
这是我当天跟新认识的编程高手 Jesse 学的 QGIS 分析结果。
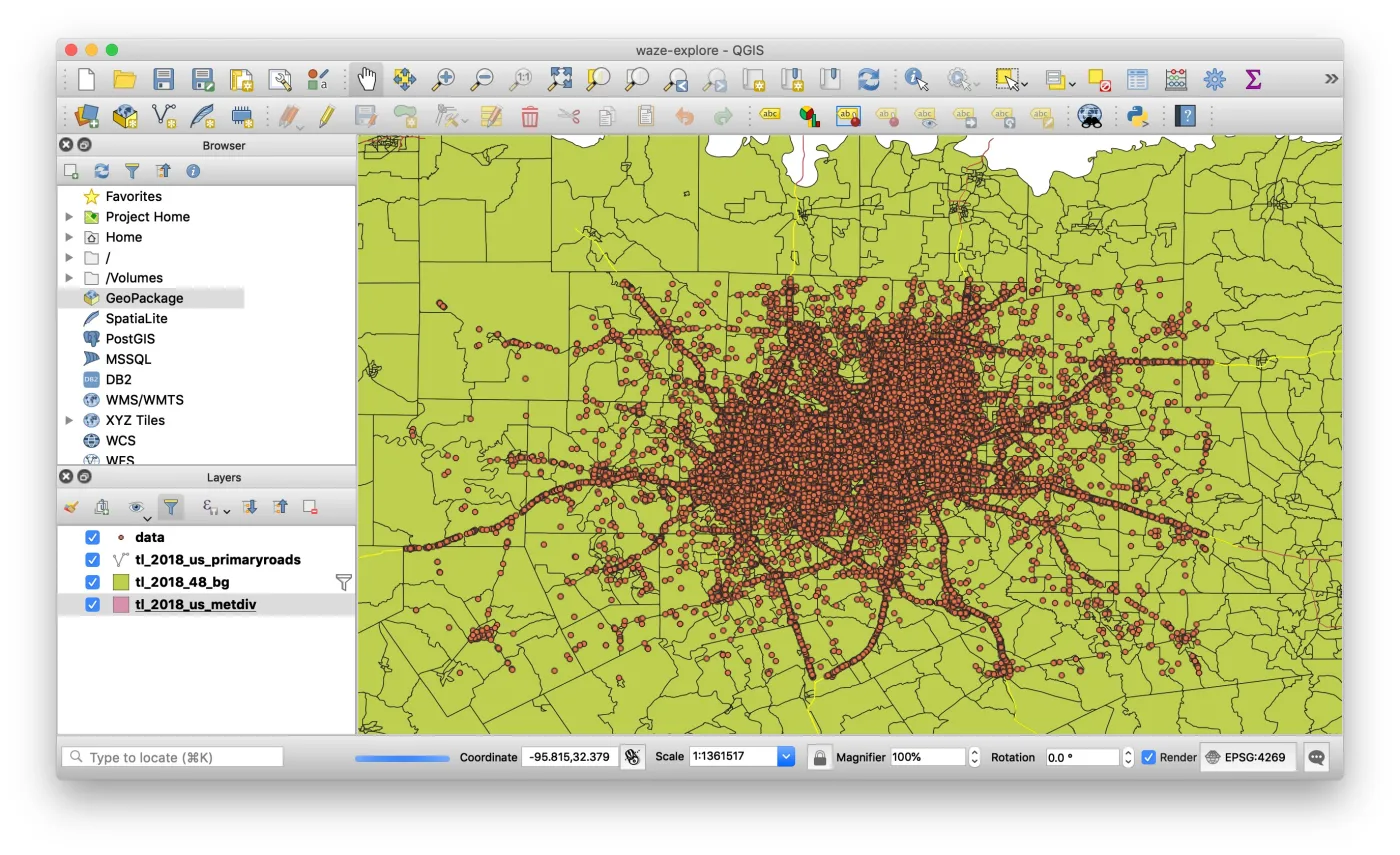
看看图上的点,每一个都对应一次事件汇报。这叫一个密密麻麻啊。
因为 QGIS 初学,用得不熟,我还是用 Python 进行了分类绘图。
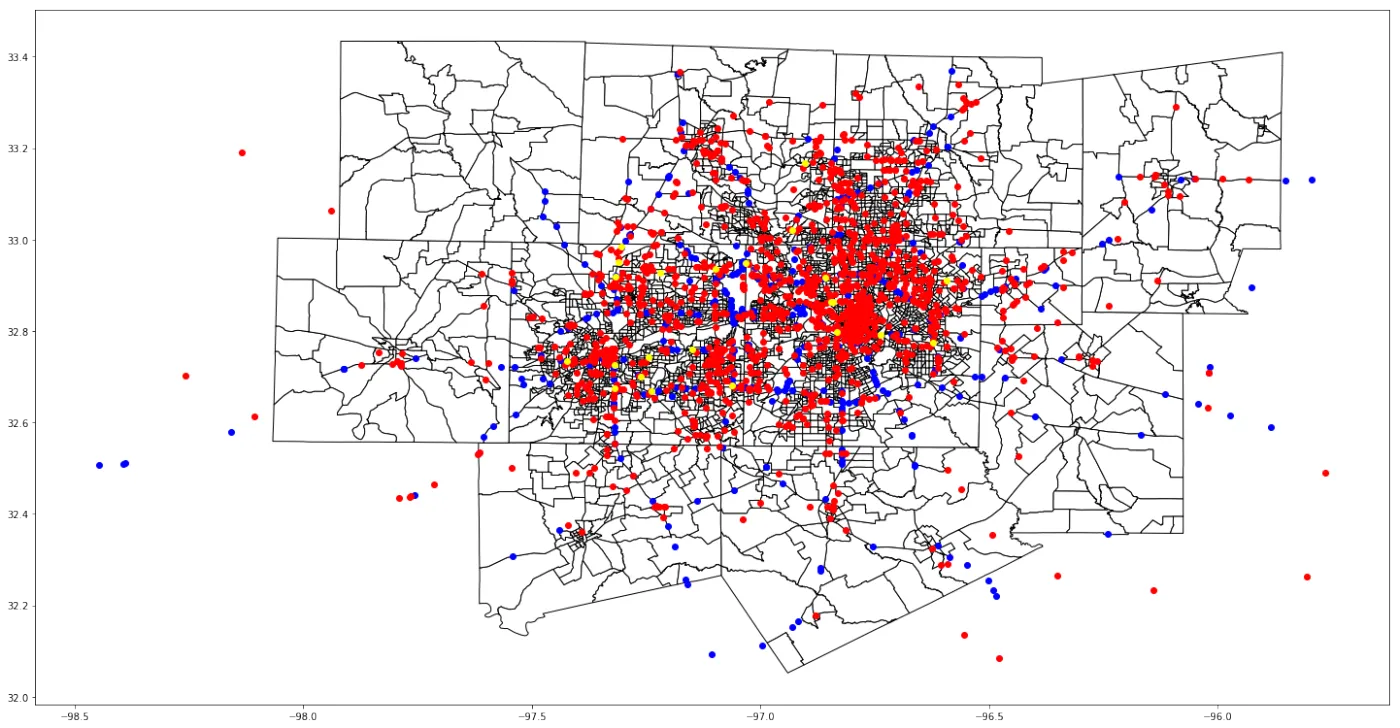
这只是前 3000 条数据中部分类型的可视化。其中红色代表交通拥堵,黄色代表事故发生,蓝色代表有车停在了路肩上。
可以看到,红色的数据量最大。这说明交通拥堵是个大问题。
我把全部的数据都拿了出来,提炼出包含的事件类型,包括以下这些类:

我看到,其中单是交通阻塞,也是分为若干级别的。其中最严重的,分别是“大型交通拥堵”(large traffic jam)和“超大型交通拥堵”(huge traffic jam)。
于是,我把所有这两种严重交通拥堵事件,合并成一个集合;其他剩余事件,作为另一个集合。
对于每一个严重拥堵事件,我追溯30分钟,把之前同一条道路上,发生的事件,按照顺序存成一个列表。这样的列表,有987个;但是,其中有一些,是骤然发生的,30分钟的区间里面,没有任何其他事件作为先兆。这样的空列表,我进行了清除。剩下了861个有效序列。
同样,从剩余事件集合中,我们随机找到了861个非空有效序列。这些序列,后续紧随事件,都不是严重拥堵。
我们对严重拥堵之前30分钟的事件序列,标记为1;对于非严重拥堵之前30分钟的事件序列,标记为0。
于是,我们就把问题转换成了,能否利用事件序列,进行分类,预测后续是否会发生严重拥堵。
靠着这个模型,我们团队(UNT IIA lab代表队,昵称 watch-dumpling )在这次比赛中,获得第一名。

这是 HackNTX 官网的报道(http://t.cn/EUbS9m5) 。
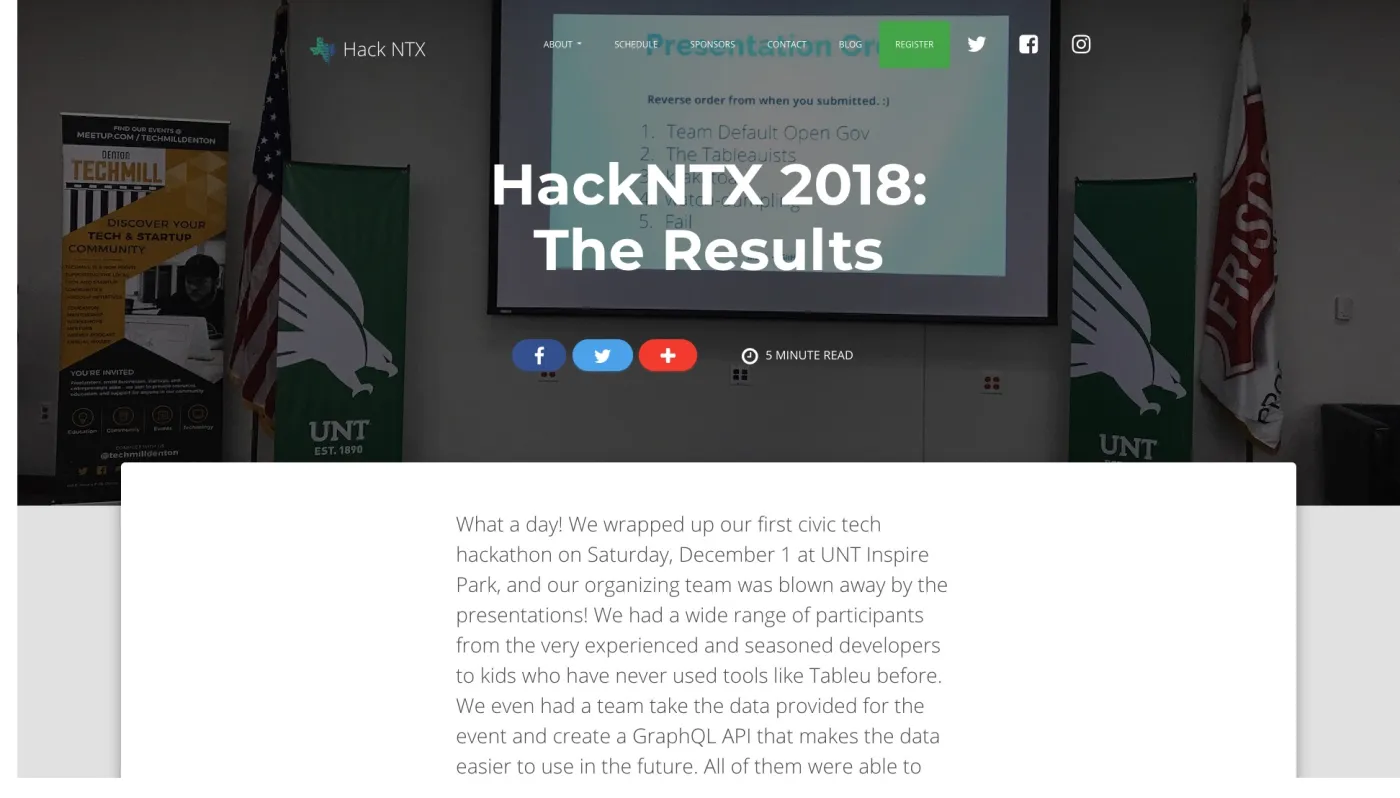
UNT 网站也正式发布了这则新闻(http://t.cn/EUbS127),于是我周围尽人皆知。我才刚拿到手的奖金,立即就因为请客被扫荡一空了。

夺冠纯属是个意外,幸运占得比重很大。但是我觉得我们做的这个模型,还是有些应用价值的。
下面,我就以这组 Waze 交通事件数据,详细给你讲解一下,如何用 Python, Keras 和循环神经网络,来实现这个序列数据分类模型。
环境
要运行深度学习,你需要有 GPU 或者 TPU 的支持,否则会累坏你的笔记本电脑的。Google Colab 是个不错的实验平台,可以让你免费使用 TPU 来进行深度学习训练。你可以阅读《如何免费云端运行Python深度学习框架?》一文,查询更为详细的介绍。
这里,请你使用 Chrome 浏览器,点击这个链接,安装一个插件 Colaboratory 。
把它添加到 Google Chrome 之后,你会在浏览器的扩展工具栏里面,看见下图中间的图标:

然后,请到本范例的github repo 主页面。
打开其中的 demo.ipynb 文件。
点击 Colaboratory 扩展图标。Google Chrome 会自动帮你开启 Google Colab,并且装载这个 ipynb 文件。
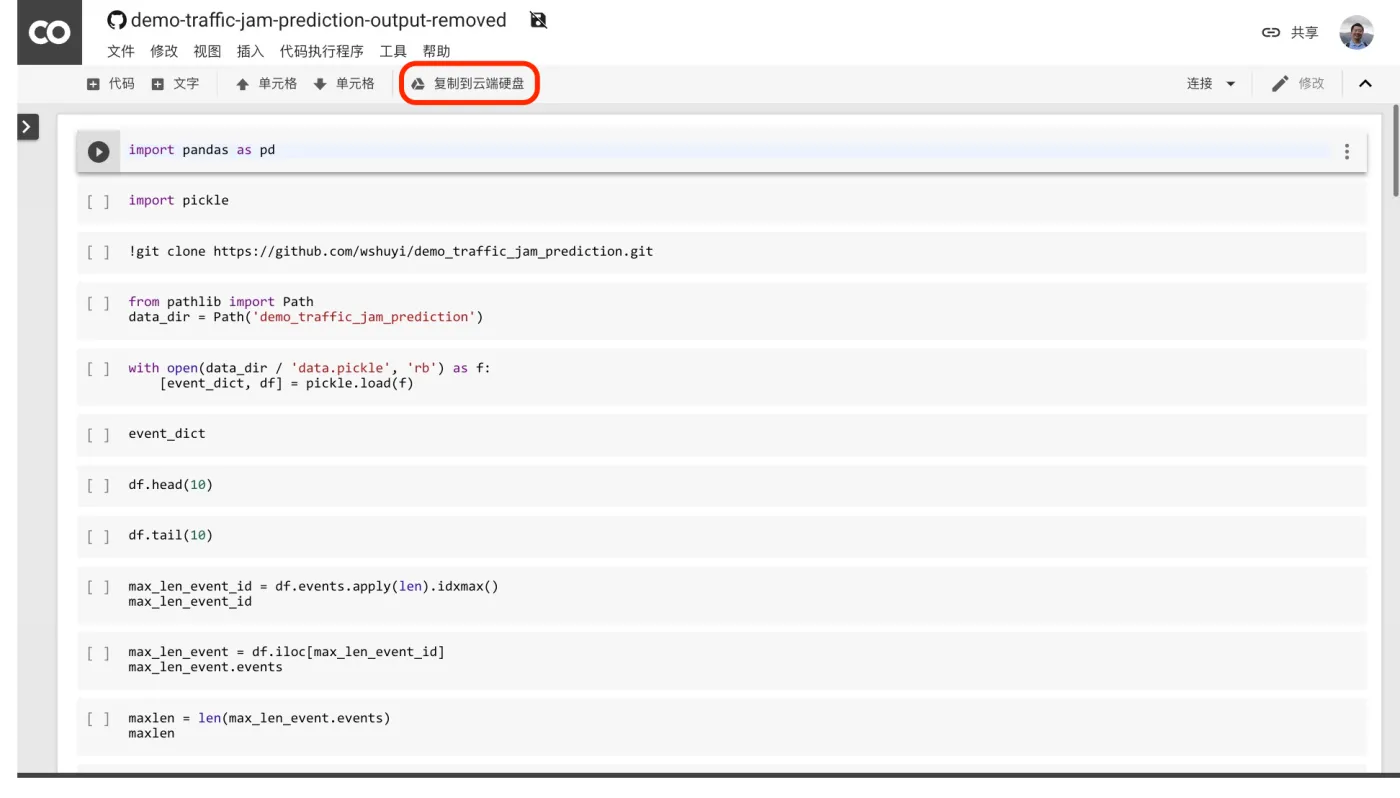
点击上图中红色标出的“复制到云端硬盘”按钮。Google 会为你新建一个属于你自己的副本。
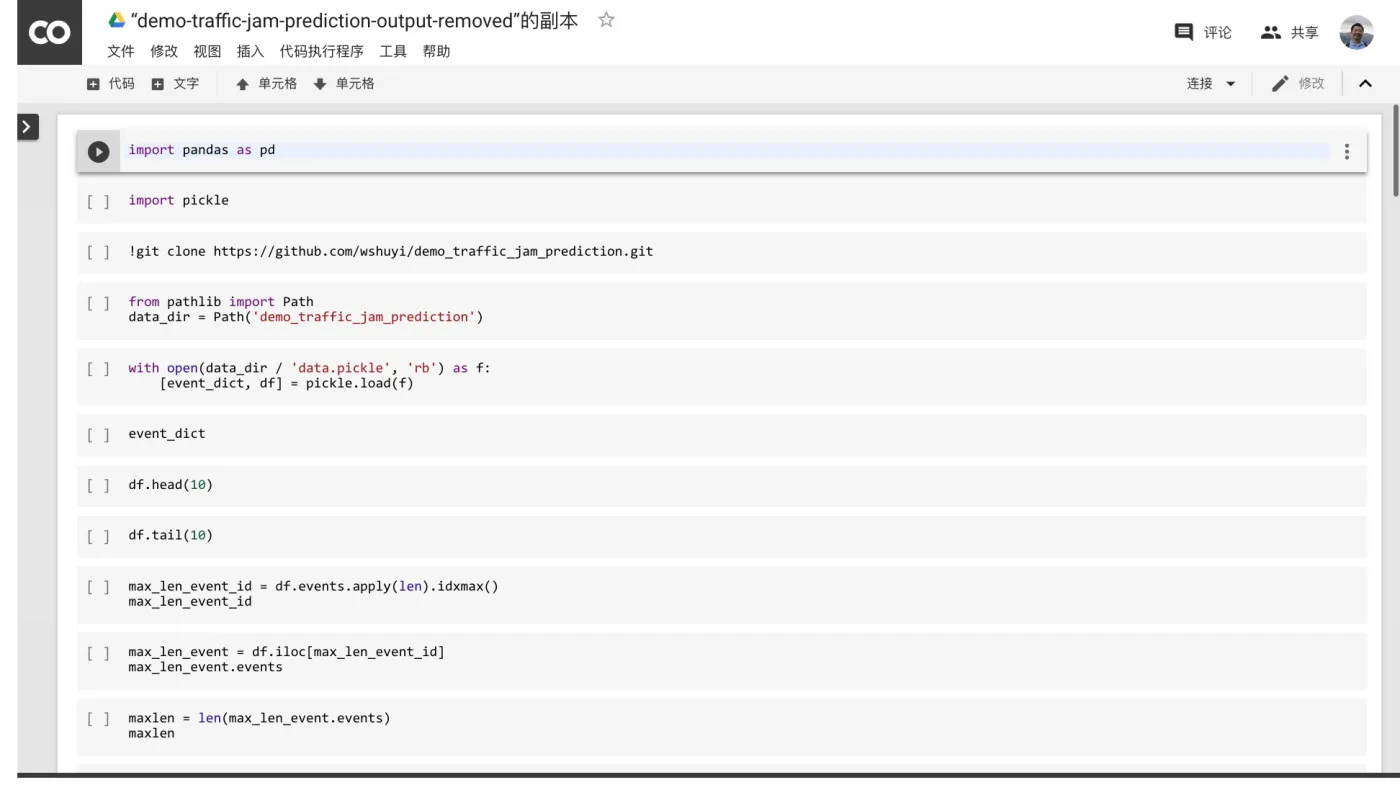
点击菜单栏里面的“代码执行程序”,选择“更改运行时类型”。

在出现的对话框中,确认选项如下图所示。
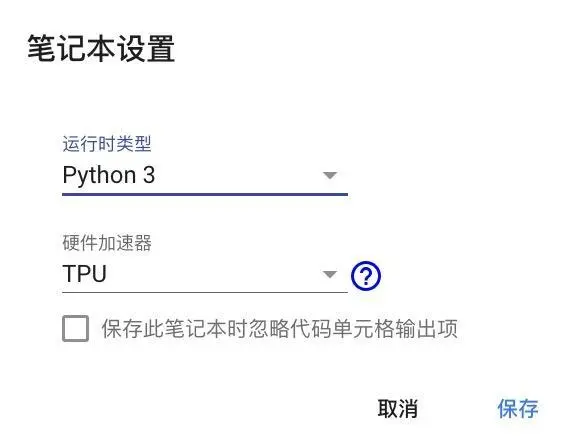
点击“保存”即可。
下面,你就可以依次执行每一个代码段落了。
注意第一次执行的时候,可能会有警告提示。

出现上面这个警告的时候,点击“仍然运行”就可以继续了。
如果再次出现警告提示,反勾选“在运行前充值所有代码执行程序”选项,再次点击“仍然运行”即可。
环境准备好了,下面我们来一步步运行代码。
代码
首先,我们读入 Pandas 软件包,以便进行结构化数据的处理。
import pandas as pd
这次还要读入的一个软件包,是 Python 中间进行数据存取的利器,叫做 pickle 。
import pickle
它可以把 Python 数据,甚至是许多组数据,一起存储到指定文件。然后读出的时候,可以完全恢复原先数据的格式。这一点上,它比用 csv 进行数据存储和交换的效果更好,效率也更高。
下面我们从本文配套的 github 项目中,把数据传递过来。
!git clone https://github.com/wshuyi/demo_traffic_jam_prediction.git
数据的下载,很快就可以完成。
Cloning into 'demo_traffic_jam_prediction'...
remote: Enumerating objects: 6, done.[K
remote: Counting objects: 100% (6/6), done.[K
remote: Compressing objects: 100% (4/4), done.[K
remote: Total 6 (delta 0), reused 3 (delta 0), pack-reused 0[K
Unpacking objects: 100% (6/6), done.
我们告诉 Jupyter Notebook ,数据文件夹的位置。
from pathlib import Path
data_dir = Path('demo_traffic_jam_prediction')
打开数据文件,利用 pickle 把两组数据分别取出。
with open(data_dir / 'data.pickle', 'rb') as f:
[event_dict, df] = pickle.load(f)
先看其中的事件词典 event_dict :
event_dict
以下就是全部的事件类型。
{1: 'road closed due to construction',
2: 'traffic jam',
3: 'stopped car on the shoulder',
4: 'road closed',
5: 'other',
6: 'object on roadway',
7: 'major event',
8: 'pothole',
9: 'traffic heavier than normal',
10: 'road construction',
11: 'fog',
12: 'accident',
13: 'slowdown',
14: 'stopped car',
15: 'small traffic jam',
16: 'stopped traffic',
17: 'heavy traffic',
18: 'minor accident',
19: 'medium traffic jam',
20: 'malfunctioning traffic light',
21: 'missing sign on the shoulder',
22: 'animal on the shoulder',
23: 'animal struck',
24: 'large traffic jam',
25: 'hazard on the shoulder',
26: 'hazard on road',
27: 'ice on roadway',
28: 'weather hazard',
29: 'flooding',
30: 'road closed due to hazard',
31: 'hail',
32: 'huge traffic jam'}
同样,我们来看看存储事件序列的数据框。
先看前10个:
df.head(10)

注意,每一行,都包含了标记。
再看结尾部分:
df.tail(10)
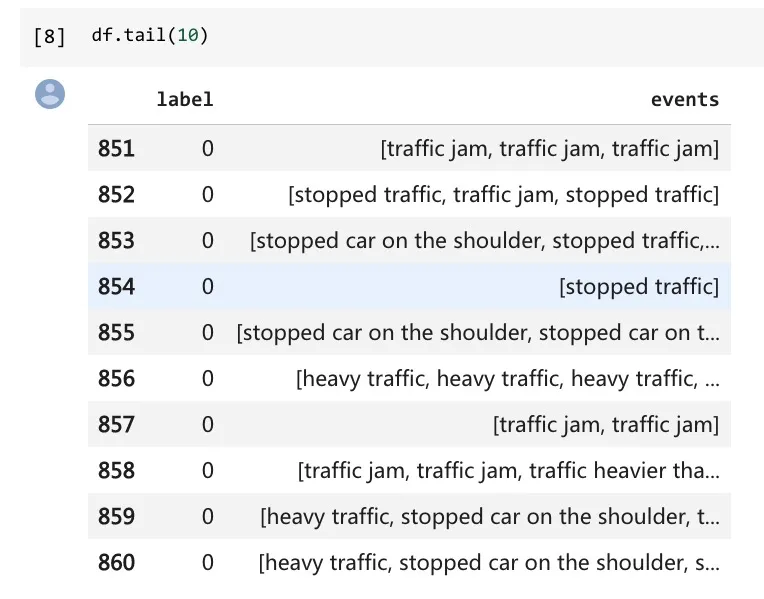
读取无误。
下面我们来看看,最长的一个序列,编号是多少。
这里,我们利用的是 Pandas 的一个函数,叫做 idxmax() ,它可以帮助我们,把最大值对应的索引编号,传递回来。
max_len_event_id = df.events.apply(len).idxmax()
max_len_event_id
结果为:
105
我们来看看,这个编号对应的事件序列,是什么样子的:
max_len_event = df.iloc[max_len_event_id]
max_len_event.events
下面是长长的反馈结果:
['stopped car on the shoulder',
'heavy traffic',
'heavy traffic',
'heavy traffic',
'slowdown',
'stopped traffic',
'heavy traffic',
'heavy traffic',
'heavy traffic',
'heavy traffic',
'traffic heavier than normal',
'stopped car on the shoulder',
'traffic jam',
'heavy traffic',
'stopped traffic',
'stopped traffic',
'stopped traffic',
'heavy traffic',
'traffic jam',
'stopped car on the shoulder',
'stopped traffic',
'stopped traffic',
'stopped traffic',
'heavy traffic',
'traffic heavier than normal',
'traffic heavier than normal',
'traffic heavier than normal',
'traffic heavier than normal',
'heavy traffic',
'stopped traffic',
'traffic heavier than normal',
'pothole',
'stopped car on the shoulder',
'traffic jam',
'slowdown',
'stopped traffic',
'heavy traffic',
'traffic heavier than normal',
'traffic jam',
'traffic jam',
'stopped car on the shoulder',
'major event',
'traffic jam',
'traffic jam',
'stopped traffic',
'heavy traffic',
'traffic heavier than normal',
'stopped car on the shoulder',
'slowdown',
'heavy traffic',
'heavy traffic',
'stopped car on the shoulder',
'traffic jam',
'slowdown',
'slowdown',
'heavy traffic',
'stopped car on the shoulder',
'heavy traffic',
'minor accident',
'stopped car on the shoulder',
'heavy traffic',
'stopped car on the shoulder',
'heavy traffic',
'stopped traffic',
'heavy traffic',
'traffic heavier than normal',
'heavy traffic',
'stopped car on the shoulder',
'traffic heavier than normal',
'stopped traffic',
'heavy traffic',
'heavy traffic',
'heavy traffic',
'stopped car on the shoulder',
'slowdown',
'stopped traffic',
'heavy traffic',
'stopped car on the shoulder',
'traffic heavier than normal',
'heavy traffic',
'minor accident',
'major event',
'stopped car on the shoulder',
'stopped car on the shoulder']
读一遍,你就会发现,在超级拥堵发生之前,确实还是有一些先兆的。当然,这是由人来阅读后,获得的观感。我们下面需要做的,是让机器自动把握这些列表的特征,并且做出区别分类。
我们看看,这个最长列表的长度。
maxlen = len(max_len_event.events)
maxlen
结果为:
84
这里的前导事件,还真是不少啊。
下面我们要做的,是把事件转换成数字编号,这样后面更容易处理。
我们使用以下的一个小技巧,把原先的事件词典倒置,即变“序号:事件名称”,为“事件名称:序号”。这样,以事件名称查询起来,效率会高很多。
reversed_dict = {}
for k, v in event_dict.items():
reversed_dict[v] = k
我们看看倒置的结果词典:
reversed_dict
这是反馈结果:
{'accident': 12,
'animal on the shoulder': 22,
'animal struck': 23,
'flooding': 29,
'fog': 11,
'hail': 31,
'hazard on road': 26,
'hazard on the shoulder': 25,
'heavy traffic': 17,
'huge traffic jam': 32,
'ice on roadway': 27,
'large traffic jam': 24,
'major event': 7,
'malfunctioning traffic light': 20,
'medium traffic jam': 19,
'minor accident': 18,
'missing sign on the shoulder': 21,
'object on roadway': 6,
'other': 5,
'pothole': 8,
'road closed': 4,
'road closed due to construction': 1,
'road closed due to hazard': 30,
'road construction': 10,
'slowdown': 13,
'small traffic jam': 15,
'stopped car': 14,
'stopped car on the shoulder': 3,
'stopped traffic': 16,
'traffic heavier than normal': 9,
'traffic jam': 2,
'weather hazard': 28}
成功了。
下面我们编写一个函数,输入一个事件列表,返回对应的事件编号列表。
def map_event_list_to_idxs(event_list):
list_idxs = []
for event in (event_list):
idx = reversed_dict[event]
list_idxs.append(idx)
return list_idxs
然后,我们在刚才是找到的最长列表上,实验一下:
map_event_list_to_idxs(max_len_event.events)
结果是这样的:
[3,
17,
17,
17,
13,
16,
17,
17,
17,
17,
9,
3,
2,
17,
16,
16,
16,
17,
2,
3,
16,
16,
16,
17,
9,
9,
9,
9,
17,
16,
9,
8,
3,
2,
13,
16,
17,
9,
2,
2,
3,
7,
2,
2,
16,
17,
9,
3,
13,
17,
17,
3,
2,
13,
13,
17,
3,
17,
18,
3,
17,
3,
17,
16,
17,
9,
17,
3,
9,
16,
17,
17,
17,
3,
13,
16,
17,
3,
9,
17,
18,
7,
3,
3]
看来功能实现上,没问题。
读入 numpy 和 Keras 的一些工具。
import numpy as np
from keras.utils import to_categorical
from keras.preprocessing.sequence import pad_sequences
系统自动提示我们,Keras 使用了 Tensorflow 作为后端框架。
Using TensorFlow backend.
我们需要弄清楚,一共有多少种事件类型。
len(event_dict)
结果是:
32
因此,我们需要对32种不同的事件类型,进行转换和处理。
我们把整个数据集里面的事件类型,都变成事件编号。
df.events.apply(map_event_list_to_idxs)
结果如下:
0 [9, 17, 18, 14, 13, 17, 3, 13, 16, 3, 17, 17, ...
1 [2, 10, 3]
2 [2]
3 [2]
4 [2, 2, 2, 2, 2, 2, 2, 9]
5 [3, 2, 17]
6 [3, 2, 17]
7 [2, 15, 2, 17, 2, 2, 13, 17, 2]
8 [17, 2, 2, 16, 17, 2]
9 [17, 2, 2, 16, 17, 2]
10 [17, 16, 17, 2, 17, 3, 17, 17, 16, 17, 16, 18,...
11 [17]
12 [17]
13 [24, 24]
14 [24, 2, 24, 24, 2]
15 [24, 2, 24, 24, 2]
16 [2, 10, 2, 2, 2, 18, 16, 16, 7, 2, 16, 2, 2, 9...
17 [2, 10, 2, 2, 2, 18, 16, 16, 7, 2, 16, 2, 2, 9...
18 [24, 24, 24, 16, 2, 16]
19 [24, 24, 24, 16, 2, 16]
20 [2, 2]
21 [2, 16, 2]
22 [2, 16, 2]
23 [2, 2]
24 [2, 2]
25 [24, 24]
26 [2, 2]
27 [2, 2, 2, 17]
28 [2, 19, 2]
29 [24]
...
831 [9, 9, 9, 2, 9, 9, 17, 2, 9, 17]
832 [3, 3, 3]
833 [2, 9, 2, 17, 17, 2]
834 [3, 3, 17, 3, 13, 3, 3, 23, 9, 3, 3, 25, 3, 3]
835 [3, 17, 9, 14, 9, 17, 14, 9, 2, 9, 3, 2, 2, 17]
836 [2]
837 [17, 2, 16, 3, 9, 17, 17, 17, 13, 17, 9, 17]
838 [13, 17, 17, 3, 3, 16, 17, 16, 17, 16, 3, 9, 1...
839 [2]
840 [3]
841 [2]
842 [17, 17, 17, 3, 17, 23, 16, 17, 17, 3, 2, 13, ...
843 [3, 3]
844 [2]
845 [2, 17, 2, 2, 2, 2, 2, 17, 2, 2]
846 [7, 17, 3, 18, 17]
847 [3, 3, 3]
848 [2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, ...
849 [2, 2]
850 [2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 13, 3, 2]
851 [2, 2, 2]
852 [16, 2, 16]
853 [3, 16, 5, 3, 17, 3, 16, 9, 3, 2, 17]
854 [16]
855 [3, 3, 3, 3, 3, 3, 3, 3, 2, 13, 3, 6, 3, 6, 3,...
856 [17, 17, 17, 2, 3, 2, 2, 2, 2, 2]
857 [2, 2]
858 [2, 2, 9, 17, 2, 2]
859 [17, 3, 2, 2, 2, 2, 2, 2]
860 [17, 3, 3, 17, 3, 17, 2, 3, 18, 14, 3, 3, 16, ...
Name: events, Length: 1722, dtype: object
现在,作为人类,我们确实是看不清楚,列表里面的事件都是什么了。好在计算机对于数字,更加喜闻乐见。
我们把该列表,起名为 sequences ,并且显示前5项内容。
sequences = df.events.apply(map_event_list_to_idxs).tolist()
sequences[:5]
下面是结果:
[[9,
17,
18,
14,
13,
17,
3,
13,
16,
3,
17,
17,
16,
3,
16,
17,
9,
17,
2,
17,
2,
7,
16,
17,
17,
17,
17,
13,
5,
17,
9,
9,
16,
16,
3],
[2, 10, 3],
[2],
[2],
[2, 2, 2, 2, 2, 2, 2, 9]]
注意,第一行,明显比后几行都要长。
对于输入序列,我们希望它的长度都是一样的。因此,下面我们就用最长的序列长度作为标准,用 0 来填充其他短序列。
data = pad_sequences(sequences, maxlen=maxlen)
data
这是结果:
array([[ 0, 0, 0, ..., 16, 16, 3],
[ 0, 0, 0, ..., 2, 10, 3],
[ 0, 0, 0, ..., 0, 0, 2],
...,
[ 0, 0, 0, ..., 17, 2, 2],
[ 0, 0, 0, ..., 2, 2, 2],
[ 0, 0, 0, ..., 3, 3, 2]], dtype=int32)
注意,所有的0,都补充到了序列的最前端。序列都一样长了。
下面,我们把全部的分类标记,存储到 labels 变量里面。
labels = np.array(df.label)
后面,我们有好几个函数,需要用到随机变量。
为了咱们运行结果的一致性。我这里指定随机种子数值。你第一次尝试运行的时候,不要动它。但是后面自己动手操作的时候,可以任意修改它。
np.random.seed(12)
好了,下面我们“洗牌”。打乱数据的顺序,但是注意序列和对应标记之间,要保持一致性。
indices = np.arange(data.shape[0])
np.random.shuffle(indices)
data = data[indices]
labels = labels[indices]
然后,我们取 80% 的数据,作为训练;另外 20% 的数据,作为验证。
training_samples = int(len(indices) * .8)
validation_samples = len(indices) - training_samples
我们正式划分训练集和验证集。
X_train = data[:training_samples]
y_train = labels[:training_samples]
X_valid = data[training_samples: training_samples + validation_samples]
y_valid = labels[training_samples: training_samples + validation_samples]
看看训练集的内容。
X_train
结果为:
array([[ 0, 0, 0, ..., 15, 15, 3],
[ 0, 0, 0, ..., 0, 2, 2],
[ 0, 0, 0, ..., 0, 0, 16],
...,
[ 0, 0, 0, ..., 2, 15, 16],
[ 0, 0, 0, ..., 2, 2, 2],
[ 0, 0, 0, ..., 0, 0, 2]], dtype=int32)
注意由于我们补充了“0”,作为填充,因此原先的32种事件类型的基础上,又加了一种。
这就是我们新的事件类型数量:
num_events = len(event_dict) + 1
我们使用嵌入层,把事件标号,转换成一系列数字组成的向量。这样,可以避免模型把事件序号,当成数值型数据来处理。
这里,我们指定每一个标号,转换成 20 个数字组成的向量。
embedding_dim = 20
利用事件类型数量,和事件向量长度,我们随机构造初始的嵌入矩阵。
embedding_matrix = np.random.rand(num_events, embedding_dim)
下面我们搭建一个循环神经网络模型。其中的 LSTM 层,包含了32位输出数字。
from keras.models import Sequential
from keras.layers import Embedding, Flatten, Dense, LSTM
units = 32
model = Sequential()
model.add(Embedding(num_events, embedding_dim))
model.add(LSTM(units))
model.add(Dense(1, activation='sigmoid'))
这里,我假设你已经看过了《如何用 Python 和循环神经网络做中文文本分类?》一文,所以就不对细节进行讲述了。如果你没有看过,或者已经遗忘,可以点击这个链接复习一下。
如果你对 Keras 的使用方法还不熟悉,我再次向你推荐 François Chollet 的《Deep Learning with Python》。

下面,是处理其中的嵌入层参数。我们直接把刚才随机生成的嵌入矩阵挪进来。而且,不让模型在训练中对嵌入层参数进行修改。
model.layers[0].set_weights([embedding_matrix])
model.layers[0].trainable = False
下面,我们开始训练。并且把模型运行结果保存起来。
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(X_train, y_train,
epochs=50,
batch_size=32,
validation_data=(X_valid, y_valid))
model.save("mymodel_embedding_untrainable.h5")
可以看到,因为有 TPU 的强力支持,程序在欢快地运行中。
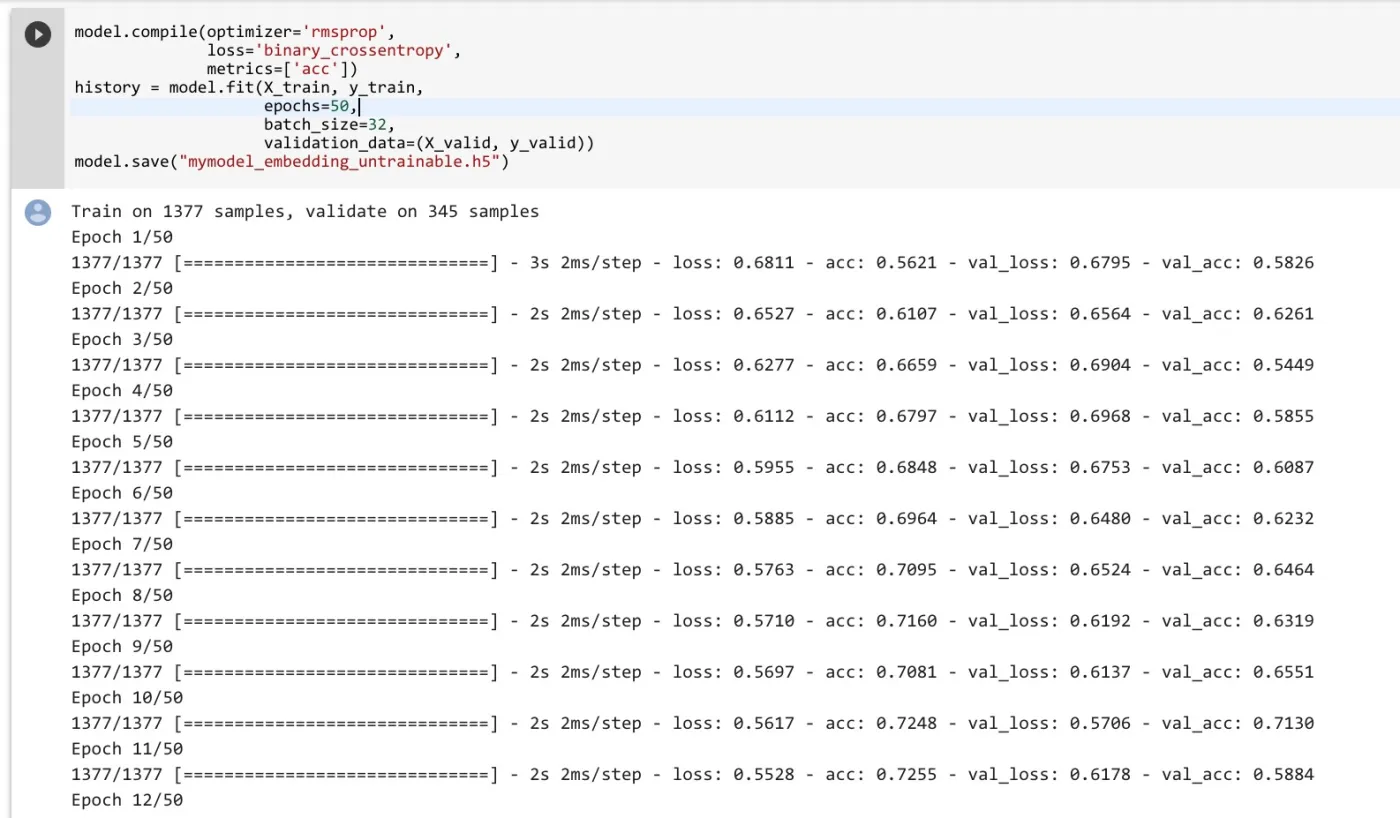
训练过程结束之后,我们利用 matplotlib 绘图功能,看一下训练中,准确率和损失值的变化。
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
这是准确率变化曲线。
可以看到,效果还是不错的。因为我们数据中,不同标记各占一半。因此如果构建一个 dummy model 作为标准线的话,对所有的输入都猜测0或者1,准确率应该只有50%。
这里的准确率,已经达到了65%-75%之间,证明我们的模型是有意义的。只不过,抖动比较厉害,稳定性差。
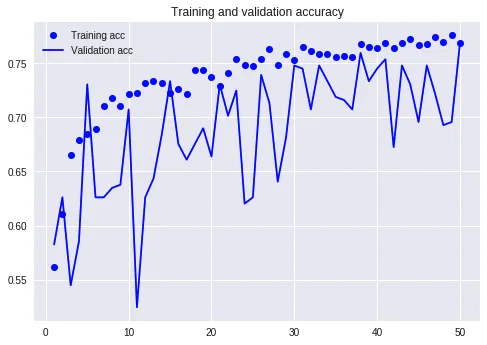
这是损失值变化曲线。
这个图看起来,就不是很美妙了。因为虽然训练集上面的损失值一路下降,但是验证集上,这个效果并不是很明显,一直剧烈波动。
看到结果,不是最重要的。关键是我们得分析出目前遇到问题,原因是什么。
注意我们前面使用了嵌入矩阵。它随机生成,却又没有真正进行训练调整,这可能是个问题。
因此,我们这里再次构建和跑一下模型。唯一改动的地方,在于让嵌入矩阵的参数也可以随着训练进行自动调整。
from keras.models import Sequential
from keras.layers import Embedding, Flatten, Dense, LSTM
units = 32
model = Sequential()
model.add(Embedding(num_events, embedding_dim))
model.add(LSTM(units))
model.add(Dense(1, activation='sigmoid'))
注意这里的差别,就是 trainable 设置为真值。
model.layers[0].set_weights([embedding_matrix])
model.layers[0].trainable = True
构建模型,再次运行。
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(X_train, y_train,
epochs=50,
batch_size=32,
validation_data=(X_valid, y_valid))
model.save("mymodel_embedding_trainable.h5")
绘图看看。
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
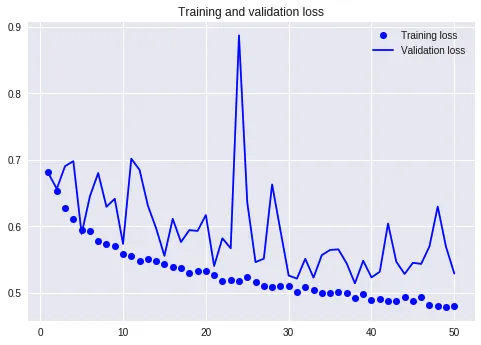
这次的准确率曲线,看起来好多了。验证集波动没有这么剧烈,模型稳定性好了许多。而且,准确率的取值,也获得了提升。后半程稳定在了75%以上。这样的模型,就有应用价值了。
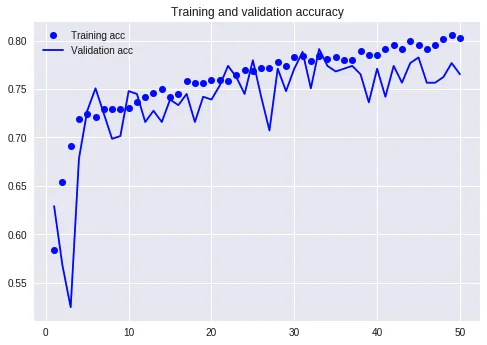
但是我们看看损失值曲线,可能就不这么乐观了。
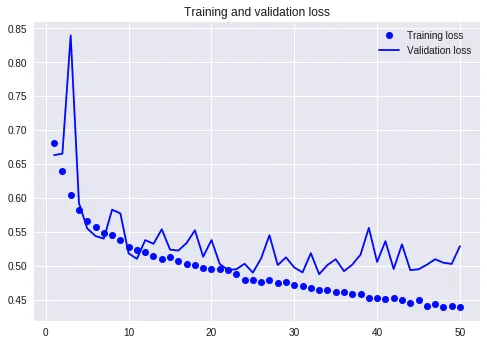
注意从半程之后,训练集和验证集的损失值变化,就发生了分叉。
这是典型的过拟合(over-fitting)。
发生过拟合,主要原因就是相对于复杂的模型,训练数据不够用。
这时候,要么增加训练数据,要么降低模型复杂度。
立即增加数据,不太现实。因为我们手中,目前只有那29天里积攒的数据。
但是降低模型复杂度,是可以利用 Dropout 来尝试完成的。
Dropout 的实现机理,是在训练的时候,每次随机把一定比例的模型中神经元对应权重参数,设置为0,让它不起作用。这样,模型的复杂度,就会降低。
下面,我们轻微修改一下,在 LSTM 层上,加入 dropout=0.2, recurrent_dropout=0.2 这两个参数。
from keras.models import Sequential
from keras.layers import Embedding, Flatten, Dense, LSTM
units = 32
model = Sequential()
model.add(Embedding(num_events, embedding_dim))
model.add(LSTM(units, dropout=0.2, recurrent_dropout=0.2))
model.add(Dense(1, activation='sigmoid'))
依然保持嵌入层可以被训练。
model.layers[0].set_weights([embedding_matrix])
model.layers[0].trainable = True
再次运行。
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(X_train, y_train,
epochs=50,
batch_size=32,
validation_data=(X_valid, y_valid))
model.save("mymodel_embedding_trainable_with_dropout.h5")
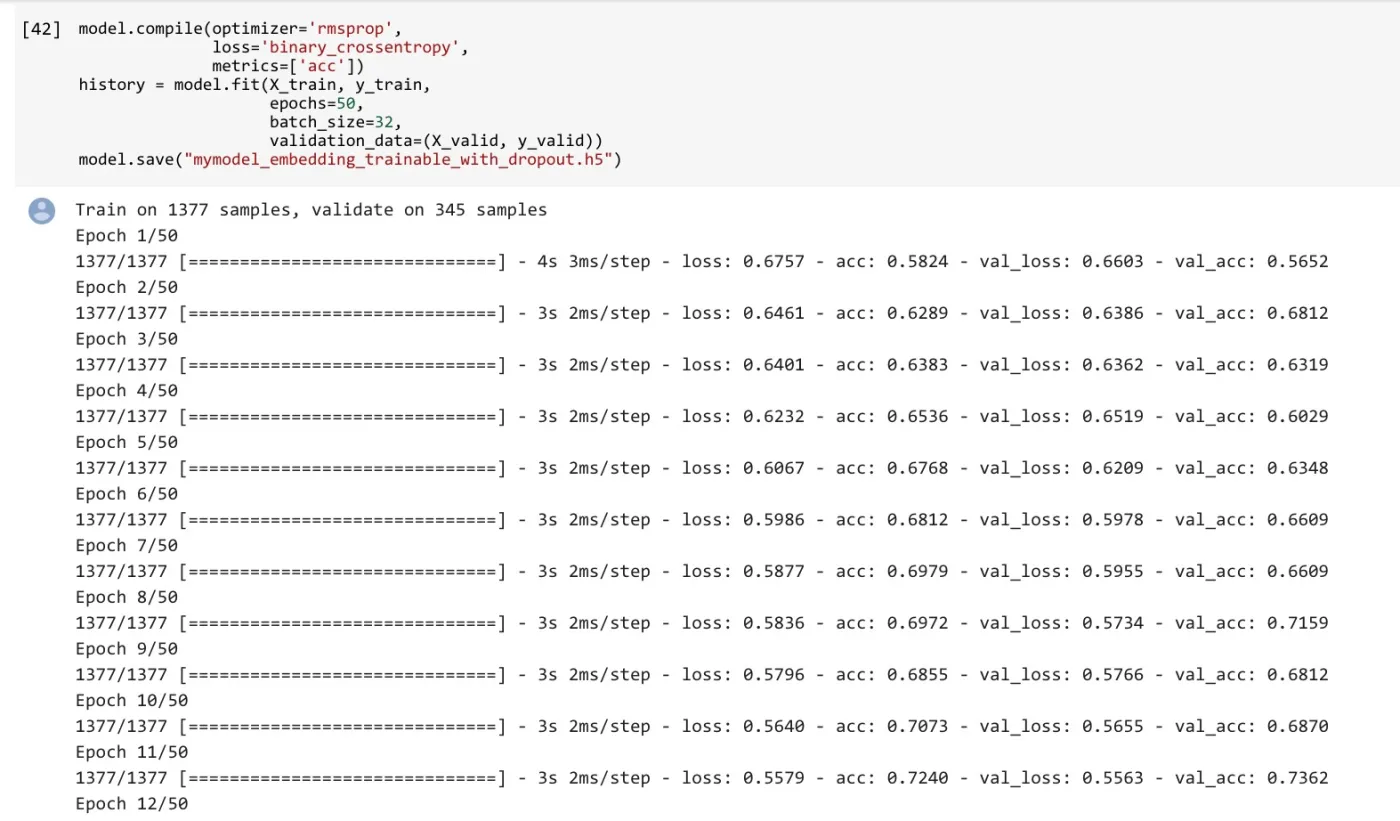
绘制图形的函数跟之前两次完全一致。
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
这次的准确率曲线,看起来达到的数值,跟没有加入 Dropout 的差不多。
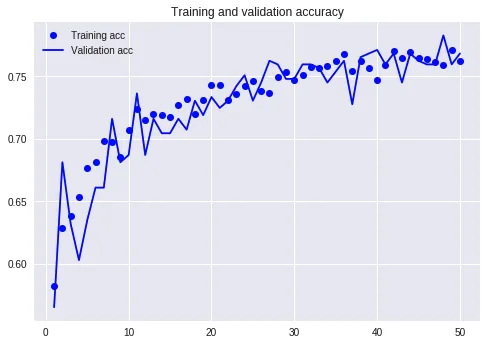
然而,我们可以感受到训练集和验证集达到的准确率更加贴近。曲线更加平滑。
下面我们看看损失值曲线的变化。
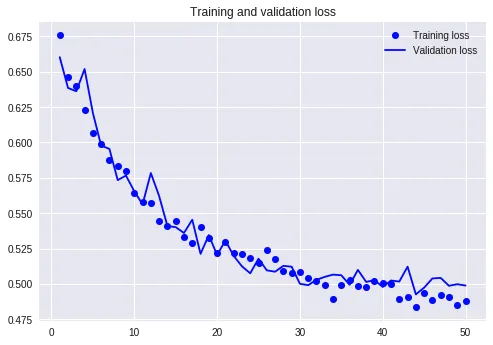
这个曲线上,过拟合的去除效果就更为明显了。可以看到训练集和验证集两条曲线的波动基本保持了一致。这样我们更可以确信,模型预测能力是稳定的,对外界新的输入信息,适应性更好。
如果把咱们的模型放在交通管理部门那里,可以期望它根据 Waze 获得的新序列数据,能以大约 75% 的准确率,预测严重交通拥堵的发生。这样,交管部门就可以未雨绸缪,提前做出干预了。
用序列模型,欺负金融市场的散户,属于零和博弈。然而这种在交通管理上的应用,大概更能造福社会,体现科技的价值吧。
小结
通过本文的学习和实际上手操作,希望你已了解了以下知识点:
- 不只是文本,其他序列数据,也可以利用循环神经网络来进行分类预测。
- 对定类数据(categorical data)进行嵌入表示,如果用随机数初始,那么在建模过程中把嵌入层一起训练,效果会更好。
- 数据量不够的情况下,深度学习很可能会发生过拟合。使用 Dropout ,可以降低过拟合的影响,让模型具有更好的稳定性和可扩展性。
希望这篇文章,可以帮助你了解循环神经网络的更多应用场景。在实际的工作和学习中,灵活运用它来处理序列数据的分类等任务。
祝(深度)学习愉快!
喜欢请点赞和打赏。还可以微信关注和置顶我的公众号“玉树芝兰”(nkwangshuyi)。
如果你对 Python 与数据科学感兴趣,不妨阅读我的系列教程索引贴《如何高效入门数据科学?》,里面还有更多的有趣问题及解法。


