
Flask的文件传输:
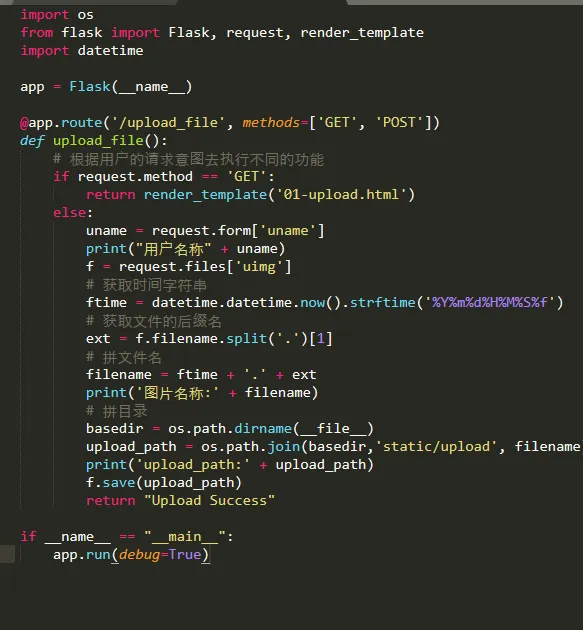
如果大批量上传数据的时候(如:大文件) 就不能使用网页上传了
主要是由于http协议不支持 需要使用单独的上传工具(c/s版的)
URL不存在参数上限的问题,HTTP协议规范也没有对URL长度进行限制。
这个限制是特定的浏览器及服务器对它的限制。
IE对URL长度的限制是2083字节(2K+35字节)对于其他浏览器,
如FireFox,Netscape等,则没有长度限制,
这个时候其限制取决于服务器的操作系统。即如果url太长,
服务器可能会因为安全方面的设置从而拒绝请求或者发生不完整的数据请求。
post 理论上讲是没有大小限制的,HTTP协议规范也没有进行大小限制,
但实际上post所能传递的数据量大小取决于服务器的设置和内存大小。
因为我们一般post的数据量很少超过MB的,所以我们很少能感觉的到post的数据量限制,
但实际中如果你上传文件的过程中可能会发现这样一个问题,
即上传个头比较大的文件到服务器时候,可能上传不上去,以php语言来说,
查原因的时候你也许会看到有说PHP上传文件涉及到的参数PHP默认的上传有限定,
一般这个值是2MB,更改这个值需要更改php.conf的post_max_size这个值。
这就很明白的说明了这个问题了
模型 Models:
什么是模型?
模型 是根据数据库中表的结构来创建出来的class
每一张表到编程语言中就是一个class
表中的每一个列 到编程语言中就是一个class属性
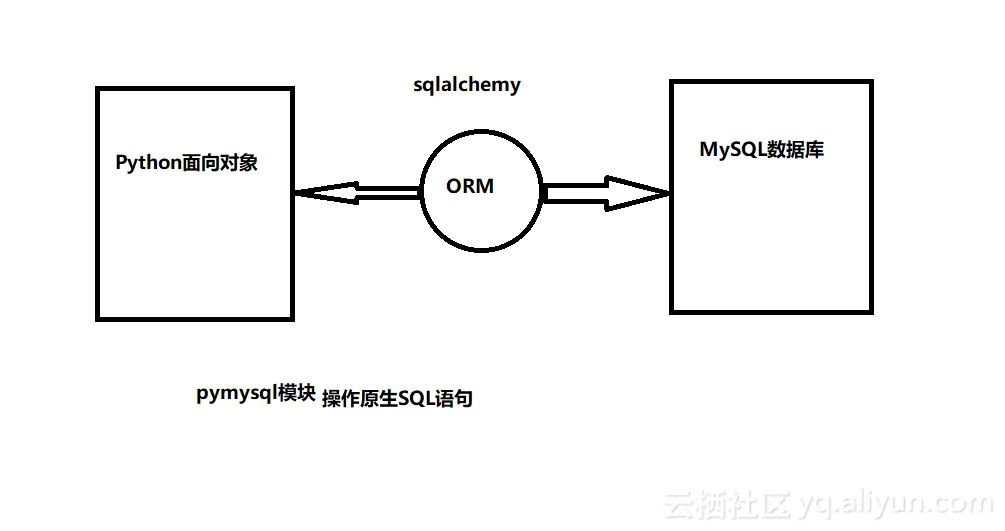
创建和使用模型 ORM框架:
什么是ORM?
(Object Relational Mapping)
对象关系映射
ORM的三大特征:
1.数据表(Table)到编程类的映射(Class)的映射
数据库中的每一张表对应编程语言中 都有一个类
在ORM中允许将数据表自动生成一个类
也允许将类自动生成一张表
2.数据类型的映射
将数据表中的字段以及数据类型 对应到编程语言中类的属性
在ORM中允许将表中的字段和数据类型自动映射到编程语言中
也允许将类中的属性和类型也映射到数据库表中
3.关系映射
允许将数据库中表之间的关系对应到编程语言中类之间的关系
数据库表之间的关系 一对一 一对多 多对多
一对一:
主外键关联 外键需要加唯一约束
一对多:
主外键关联
多对多:
第三方关系表
ORM的优点:
提高了开发的效率
能够省略庞大的数据访问层 即便不使用SQL编码 也能完成对数据的CRUD操作
定义模型:
框架的配置
安装sqlalchemy
sudo pip3 install sqlalchemy
sudo pip3 install flask-sqlalchemy
创建数据库
create database flask default charset utf8
collate utf8_general_ci;
配置数据库:
app.config["SQLALCHEMY_DATABASE_URI"] = "mysql://username:password@host:port/database"
app.config["SQLALCHEMY_DATABASE_URL"] = "mysql://root:123456@:127.0.0.1:3306/mysql"
db是SQLALchmey的实例对象 表示程序正在使用的数据库
同时也获得了SQLALchemy中的所有功能
定义模型:
模型:
数据库中的表在编程语言中的体现 本质就是一个Python的类 模型类 实体类
类中的属性要与数据库中的列相对应
语法:
class ModelName(db.Model):
__tablename__ = "TABLENAME"
COLUME_NAME = db.olumn(db.TYPE, OPTIONS)
ModelName:
定义模型名称 根据表名设定
TABLENAME:
映射搭配数据库中表的名字
COLUMN_NAME:
属性名,映射到表中列的名字
db.TYPE;
映射到列的数据库类型
OPTIONS:
列选项
db.TYPE 列类型:
类型名 Python类型 说明
Integer
int 普通整数 32位
SamllInteger
小范围整数 小范围整数 16位
BigInteger int或long 不限精度的整数
Float float 浮点数
Numeric decimal.Decimal 定点数
String str 变长字符串
Text str 变长字符串 优化后的
Unicode Unicode 变长Unicode字符串
UnicodeText Unicode 优化后的变长Unicode字符串
Boolean bool 布尔类型
Date datetime.date 日期
Time dataeime.time 时间
DateTime datetime.datetime 日期和时间
OPTIONS列选项:
选项名 说明
primary key 设置为True则表示该列为主键
unique 设置为True则表示该列的值唯一
index 设置为True则表示该列要创建索引
nullable 设置为True则表示该列允许为空
default 为该列定义默认值
from flask import Flask, request, render_template
from flask_sqlalchemy import SQLAlchemy
import pymysql
pymysql.install_as_MySQLdb()
app = Flask(__name__)
#指定连接字符串
app.config['SQLALCHEMY_DATABASE_URI']='mysql://root:123456@localhost:3306/flask'
#指定让SQLAlchemy自动追踪程序的修改
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True
#指定执行完操作之后自动提交
app.config['SQLALCHEMY_COMMIT_ON_TEARDOWN'] = True
#为当前的项目创建一个SQLAlchemy的实例
db = SQLAlchemy(app)
# 创建模型类 - Models
# 创建 Users 类,
class Users(db.Model):
# 映射到表中叫 users 表
__tablename__ = 'users'
# 创建字段 : id , 主键,自增
id = db.Column(db.Integer,primary_key=True)
# 创建字段 : username , 长度为80的字符串,不允许为空,必须唯一
username = db.Column(db.String(80),nullable=False,unique=True)
# 创建字段 : age , 整数,允许为空
age = db.Column(db.Integer)
# 创建字段 : email,长度为120的字符串,必须唯一
email = db.Column(db.String(120),unique=True)
def __init__(self,username,age,email):
self.username = username
self.age = age
self.email = email
def __repr__(self):
return '<Users:%r>' % self.username
# 将创建好的实体类映射回数据库
# db.drop_all()
db.create_all()
if __name__ == "__main__":
app.run(debug=True)
数据库操作:
插入
db.session.add(Models)
db.session.commit()
@app.route('/insert')
def insert_views():
# 创建 Users 对象
users = Users('Paris',38,'wei8023521@gmail.com')
# 将对象通过db.session.add()插入到数据库
db.session.add(users)
# 提交插入操作
db.session.commit()
return "Insert Success"
@app.route('/register',methods=['GET','POST'])
def register():
if request.method == 'GET':
return render_template('02-register.html')
else:
# 接收前端传递过来的数据
username = request.form.get('username')
age = int(request.form.get('age'))
email = request.form.get('email')
# 将数据构建成 Users 对象
users = Users(username,age,email)
# 通过 db.session.add 将对象保存进数据库
db.session.add(users)
# 提交
# db.session.commit()
return "Register OK"
if __name__ == "__main__":
app.run(debug=True)

