我们团队构建的OpenAI Five 已经击败了业余的Dota2队伍,虽然我们使用的仅限于一些固定的英雄。但我们的目标是在8月份的国际比赛中击败顶尖战队,我们可能不会成功。因为Dota 2是一个复杂的电子竞技运动,其中存在很高的不确定性,这也是现在电子竞技运动最火的原因。
OpenAI Five通过自我对抗学习来玩游戏,玩一天相当于180年。它使用在256个GPU和128000个CPU内核上使用扩展版近端策略优化进行训练。当我们为每个英雄使用单独的LSTM并且不使用人类数据,它学习了可识别的策略。这表明强化学习可以产生大规模但也可接受的长期规划,这与我们开始项目时的预期背道而驰。

OpenAI Five组织了最好的OpenAI员工团队。
我们需要面临的问题
人工智能在电子游戏的一个里程碑是在星际争霸或Dota 这样复杂的电子游戏中超越人类的能力。相对于以前的AI里程碑,如国际象棋或围棋,复杂的电子游戏开始捕捉现实世界的混乱和连续性。我们希望通过解决复杂电子游戏的系统,使应用程序具有很高的通用性。
Dota 2是一款实时5V5战略游戏,每个玩家控制一个英雄角色。这就要求玩Dota的AI必须掌握以下几点:
1.长时间运行。Dota游戏以每秒30帧的速度运行,平均时间为45分钟。大多数操作行为(例如命令英雄移动到某个位置)单独产生的影响很小,但一些个别行为可能会在战略上影响游戏,例如一个英雄TP回家,那么整个游戏的布局就会发生改变。OpenAI Five每四帧观察一次,产生2万次决策。象棋通常在前40步就结束了,围棋大概是150步,它们的每一步(决策)都有策略性。
2.局部可观察状态。他们只能看到周围区域的单位和建筑物,地图上的其他部分隐藏在雾中隐藏着敌人和他们的战略。水平较高的比赛需要根据不完整的数据进行推断,并且需要建立对手的最佳状态,相比之下象棋和围棋都是全信息游戏。
3.高度连续的动作空间。在Dota中,每个英雄可以采取数十个动作,许多动作都是针对另一个单位或地面上的某个位置。我们将每个英雄的空间分割成17万个可能的行动(并非动作都有效,例如使用冷却时间的法术),不计算连续部分,每tick平均有大约1000次有效操作。而国际象棋中的平均动作数为35,在围棋中为250。
4.高维度,连续的观察空间。Dota是在包含十个英雄、数十个建筑物及几十个NPC单位以及诸如符文,草丛和眼卫等。我们的模型通过Valve的Bot API观察Dota游戏的状态,其中包括2万个(大多是浮点)允许人类访问的所有信息。国际象棋棋盘自然表现为大约70个枚举值(一个8x8的棋子类型和6类棋子), 一个围棋棋盘作为约400个枚举值(一个19x19的棋子类型加上黑白两子)。
Dota规则也非常复杂,它已经被开发了十多年,游戏逻辑在数十万行代码间实现,每个逻辑需要几毫秒的时间才能执行。游戏也每两周更新一次,不断改变环境语义。
我们的解决方法
我们的系统使用的是Proximal Policy Optimization大规模版本进行学习。OpenAI Five和我们早期的1v1机器人都完全从自我对抗学习中学习。他们从随机参数开始,不使用曾经的游戏回放进行搜索或引导。

RL研究人员一般认为,长时间学习需要从算法上取得新的进展,如层级强化学习。我们的结果表明,至少当它们以足够的规模和合理的探索方式运行时。我们并没有完全信任今天的算法。
尽管当前版本的OpenAI Five在发育时候(补兵)表现不佳(观察我们的测试比赛,专业Dota评论员Blitz估计它的水平大约是中等级别Dota玩家),但其优先攻击目标选择已经达到了专业水平。另外,在插眼控图上通常会选择牺牲短期回报,例如补兵获得的经济。这一观察增强了我们的信念,即系统真正在长期的优化。
模型结构
每个OpenAI Five的网络都包含一个单层1024单元的LSTM,它可以查看当前的游戏状态(从Valve的Bot API中提取),并通过几个可能的动作Head发出下一个动作。每个head都具有语义信息,例如延迟此动作的刻度时间,要选择的动作数量,单位周围网格中此动作的X或Y坐标等。
OpenAI Five可以对其丢失的状态片段做出反应。例如,直到最近OpenAI Five的观测还没有包括弹片落下的区域(弹丸落在敌人身上的区域),人类在屏幕上可以看到这些区域。然而,我们观察到OpenAI Five可以学习走出活跃的弹片区域,因为它可以看到它的健康状况在下降。
探索
鉴于能够处理长期视野的学习算法,我们仍然需要探索环境。即使我们已经限制了游戏的复杂度,但这个游戏也有数百种物品,数十种建筑物,法术和单位类型,以及需要了解的大量游戏机制。其中可以产生许多强大的组合,要有效地探索这个广阔的空间组合并不容易。
OpenAI Five通过自我对抗(从随机权重开始)学习,这为探索环境提供了一个自然的循环。为了避免“战略崩溃”,AI英雄对自己进行了80%的比赛训练,其他20%是与过去的AI英雄进行了对战训练。在第一场比赛中,英雄漫无目的地在地图上漫步。经过几个小时的训练后,诸如规划、发育、中期战斗等概念慢慢出现。几天后,他们基本可以采用人类战略:试图从对手手中夺取财富、推塔发育、利用地图优势埋伏敌对等等操作。通过进一步的训练,他们能够熟练掌握了五个英雄“一起推塔”这样的高级协作策略。
2017年3月,我们通过训练的AI击败了机器人,但却输给了人类。为了强制在策略空间中进行探索,在训练期间,我们随机化了这些单位的属性(健康、速度、开始水平等),并且让它开始与人类对战。后来,当一名测试玩家一直在1v1时击败我们的机器人,我们增加了训练的随机性,参与测试玩家开始失败。与此同时,我们的机器人团队将类似的随机技术应用到物理机器人中,以便从模仿学习迁移知识到现实世界中。
OpenAI Five使用了我们为1v1机器人编写的随机数据。它也使用一个新的“lane assignment”。即在每次训练比赛开始时,我们随机地将每个英雄“分配”到线路的子集,并对避开这些车道的AI机器人进行惩罚,直到游戏中随机选择的时间结束。
这样的探索也得到了很好的回报。我们的回报主要包括衡量人类如何在游戏中做出的决策:净价值、杀敌数、死亡数、助攻数等等。我们通过减去其他团队的平均奖励后处理每位AI机器人的奖励,以防止AI机器人找到正项和(positive-sum)的情况。
我们硬编码项目和技能构建(最初为我们的脚本基准编写),并随机选择使用哪个构建。快递管理也从脚本基准中导入。
协作
OpenAI Five没有英雄神经网络之间明确的沟通渠道。团队协作由我们称为“团队精神”的超参数控制,团队精神的取值范围从0到1,它代表了OpenAI Five的每个英雄在多大程度上关注其个人奖励值以及团队奖励的平均奖励值。在训练中,我们将这个值从0调整到了1。
Rapid

我们的系统是用通用RL训练系统Rapid来实现的,它可被应用于任何一个Gym环境中。我们还使用Rapid解决了OpenAI的其他问题,例如竞争性自我对抗训练。

训练系统分为运行游戏副本和收集AI机器人运作的部署工作人员,以及优化器节点,这些节点在整个GPU队列中执行同步梯度下降。部署工作人员通过Redis将他们的体验同步到优化器。每个实验还包含评估经过训练的AI机器人与评估AI机器人的工作人员,以及一些监控软件,如TensorBoard,Sentry和Grafana。

游戏结果
到目前为止,OpenAI Five已经和很多队伍进行了对战:
1. 最好的OpenAI员工团队:匹配分2500;
2. 观看OpenAI员工比赛的5位观众(之前没有组过队):匹配分4000-6000;
3. 业余队:匹配分4200,作为一支队伍进行训练;
4. 半职业队:匹配分5500,作为一支队伍进行训练。
与前面的两支队伍的比赛中,OpenAI取得了胜利,但输给了后面的两只队伍。

我们观察到OpenAI Five对局的特点:
1.经常参用换路的方式来对抗敌方的优势路,这可能是AI机器人在策略上没有“抗压”的思路。“换路”这种策略在过去几年中出现在专业领域,现在被认为是盛行的策略。
2.中期转变更快,超过对手。它是这样做的:(1)找到人类玩家的失误,发起成功的gank;(2)在对手组织起来之前,反制对手。详见下图:
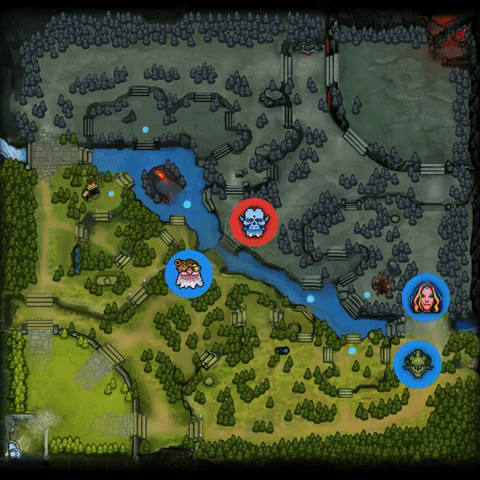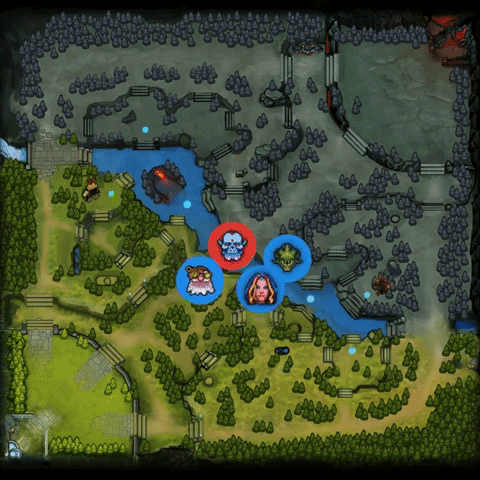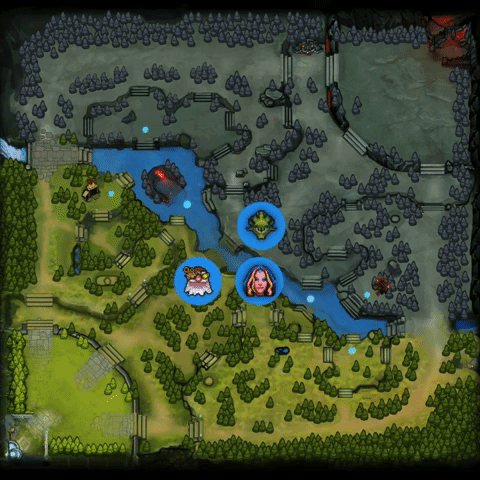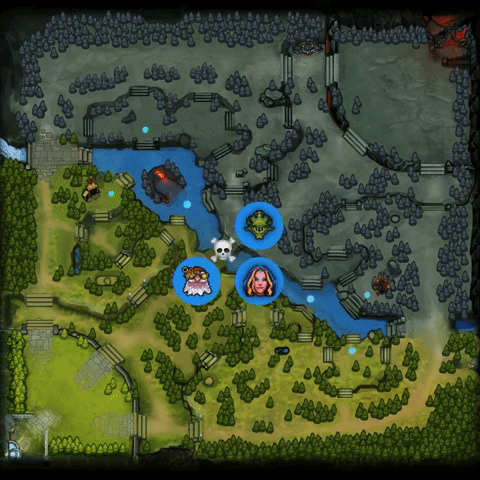
3.AI机器人在打法上有时也会出现一些偏离,比如给予辅助英雄大量的资源发育。OpenAI Five的优先级让它造成的伤害很快的达到最高峰,并更加努力地推进其优势,赢得团队战斗并利用对手的失误来确保快速获胜。
与人类的差异
OpenAI Five可以访问的信息跟人类一样,但前者可以实时看到队友位置、生命值等等信息,而对于人类来说,人类需要自动去检查这些信息。我们的方法从根本上并没有与观察状态相关联,但仅从游戏中渲染像素就需要数千个GPU。这就意味着OpenAI Five平均每分钟执行150-170次动作。这相比于熟练的玩家来说是巨大的优势,而且OpenAI Five的平均反应时间为80ms,比人类玩家更快。
令人惊讶的发现
1.二元奖励可以提供良好的表现。我们的1v1模型具有形状奖励,包括上次命中奖励,击杀奖励等。我们进行了一个实验,我们只奖励AI机器人获胜或失败,并且让它在中间训练了一个数量级较慢并且稍微平稳的阶段,与我们通常看到的平滑学习曲线形成对比。该实验运行在4500个核心和16个k80 GPU上,训练结果达到半专业级。

2.可以从头开始学习卡兵。对于1v1,我们用传统RL和“卡兵奖励”来学习卡兵。
3.我们仍在修复BUG。下图显示了打败业余玩家的训练代码,相比之下,我们只是修复了一些BUG(如训练期间罕见的崩溃)或导致达到25级后巨大负面奖励的错误。事实证明我们有可能在有BUG的前提下击败人类!

下一步
我们的团队专注于我们八月份的目标:在国际邀请赛上战胜职业战队。我们不知道它是否可以实现,但我们相信,通过努力工作(以及一些运气),我们有机会。
我们的做这项研发的基本动机超越了Dota本身。真实世界的人工智能部署需要处理比Dota游戏更多的挑战,如果我们想要征服这些挑战,我们首先要战胜Dota。最终,我们希望可以从这项研发中获得的经验应用于现实。
以上为译文。
本文由由北邮@爱可可-爱生活 老师推荐,阿里云云栖社区组织翻译。
文章原标题《openai-five》,
作者:openai 译者:虎说八道,审校:。
文章为简译,更为详细的内容,请查看原文。
