在8月13日的云栖TechDay创投专场上,玻森数据CTO闵可锐为我们带来了一场别开生面的讲座,他主要介绍了人工智能在实际产品中的运用以及其背后隐藏的技术——自然语言的处理。
以下是现场分享观点整理。
本次分享分为两部分,第一部分简单介绍风报在企业的情报分析上能够达到的效果;第二部分和各位分享下开发风报时技术层面的挑战和一些算法上的具体实现,包括新闻语音相关性的计算,关系抽取计算等。
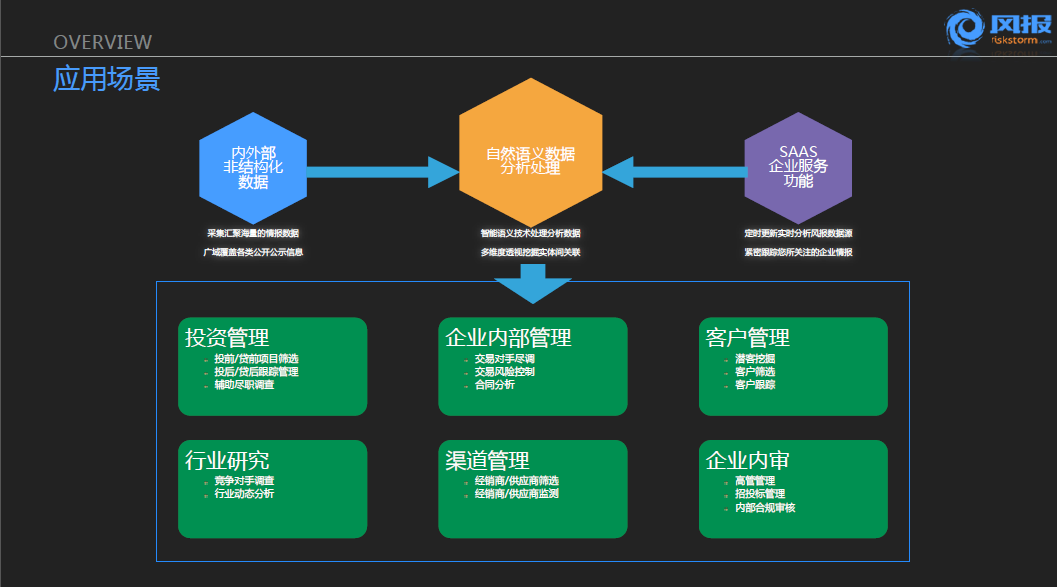
风报在企业分析中的定位是一个SAAS平台的企业服务,在该平台上我们沉淀了大约3000万家国内注册的企业,围绕这3000万家企业的每一个企业形成一个“画像”,该“画像”能够刻画出这家企业的相关风险和情报信息。该“画像”能够让你尽可能短的时间以内对这个企业有一个非常完整的理解。投影上的这块就是我们在做风报中大体的一个结构呈现,涉及到大量的外部公开以及合作的相关数据源,具体可以分为两个部分:一个是政府的公开信息,例如工商局公示信息、全国高院的网站上披露的信息,以及很多相关的裁判文书网的的信息等。我们单单统计中国政府类公开的信息网站在去年就达到了6500家,也就意味着如果我们想要对某一家企业进行了解,我们便会在百度上搜索这家公司的名字,我们阅读了百度的前100页的1000条信息,我们自己来总结这家企业涉及到了什么样的报道:哪些报道是正面的、哪些是投融资的报道、哪些是关于高官变动的报道等?我们希望的便是这一整个流程有一套自动化的解决方案。
风报的实际运用和特色
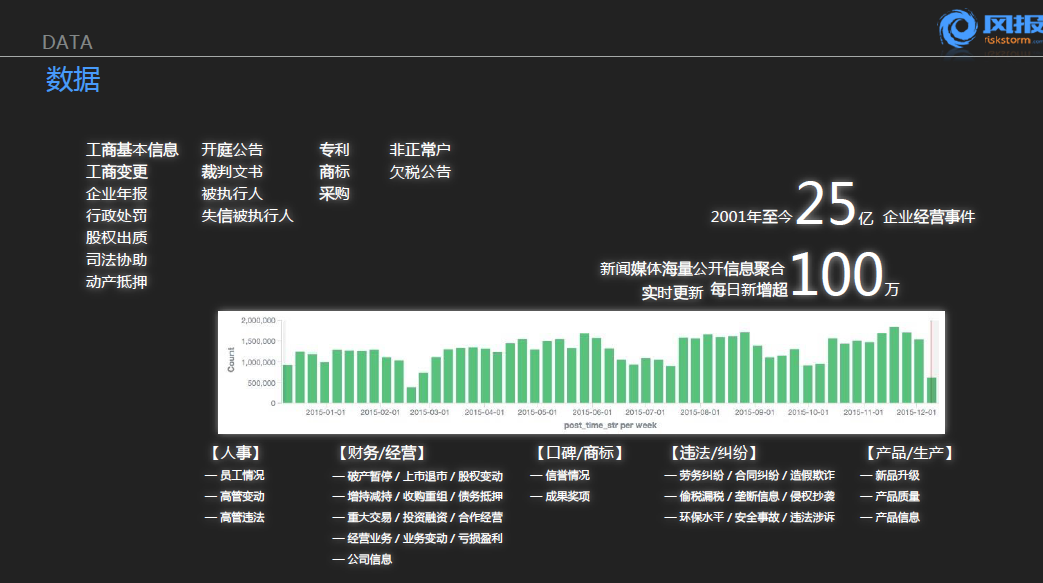
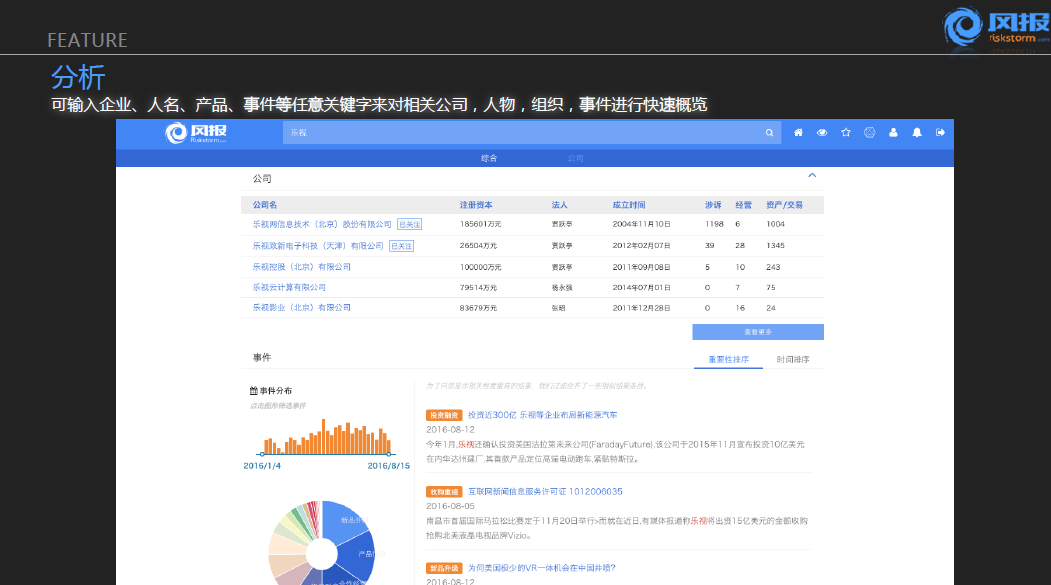
上图显示的是我们产品当中涉及到的相关术语以及部分的数据,系统上面可以覆盖政府披露的一些数据包括工商的信息、企业的年报信息、开庭事项、相关的专利、注册商标,正在进行中的政府采购项目、是否有欠税行为而被政府列入欠税公告等。
所有这些信息对于理解一个企业的风险会有非常大的帮助。下面这个部分主要就是我们从公开的信息源,例如新闻类的网站对企业的大量报道会涉及到很多细节内容,例如员工的情况,高官的情况,新获得的奖项,是否牵涉到纠纷等等。这些信息全部都是以非结果化的状态呈现在各个报道里面,在我们的系统里面有相应的处理和提取,共收集了从2001年到今年差不多15年的,25亿条的企业信息。并且这个系统是一个动态系统,每天会更新100—200万的数据。刚才我们也提到了在海量的数据中仅仅通过关键词的搜索来进行信息的查找,是一个非常低效率的做法。
以乐视公司为例,我们每天能够抓取与之有关的上万条信息,所以简单地通过抓取上述结果的话,显然是不能够对这个企业进行完整的评价,这时候我们就要借助一些额外的工具对企业的信息进行结构上的梳理。因此在我们这个系统里面有6个基础的语音分析的引擎和9个的应用类的引擎,去实现各种功能。
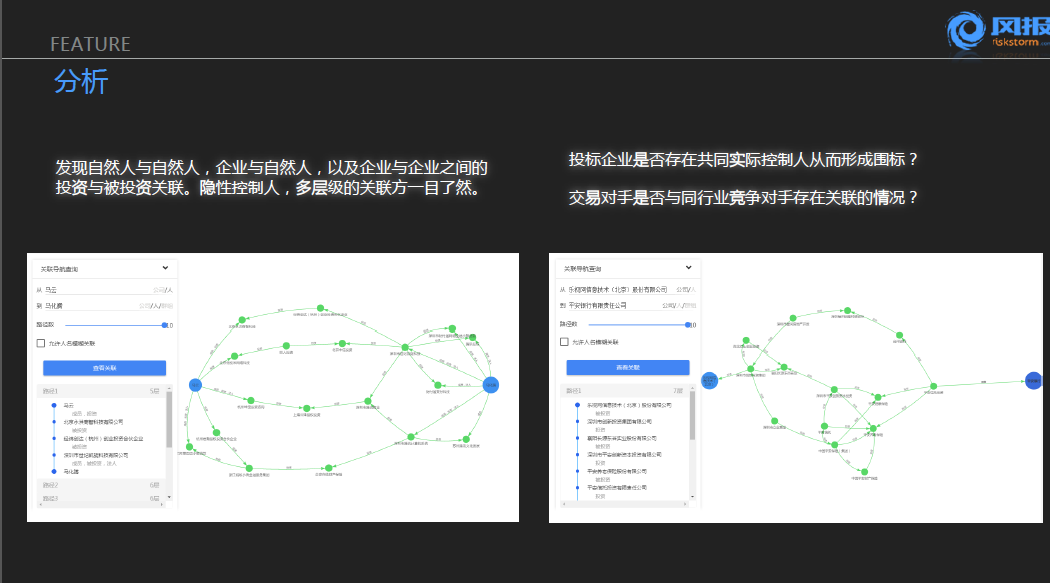
上图是我们目前系统功能的简单展示,比如有一块功能叫做关联图的发现,就是我们在这个系统里面任意输入企业的自然人名字和公司的名称,便可以提取出相关的动态信息、实体之间究竟有什么样的关系等。就像A投资了一家B企业,B企业又投资了C企业,C企业其实与A是存在间接关系的,在资本运作中,老道的投资者会使投融资结构复杂化,使得一个企业和两个企业的之间的关系无法简单地通过直接察看工商数据而被发现。
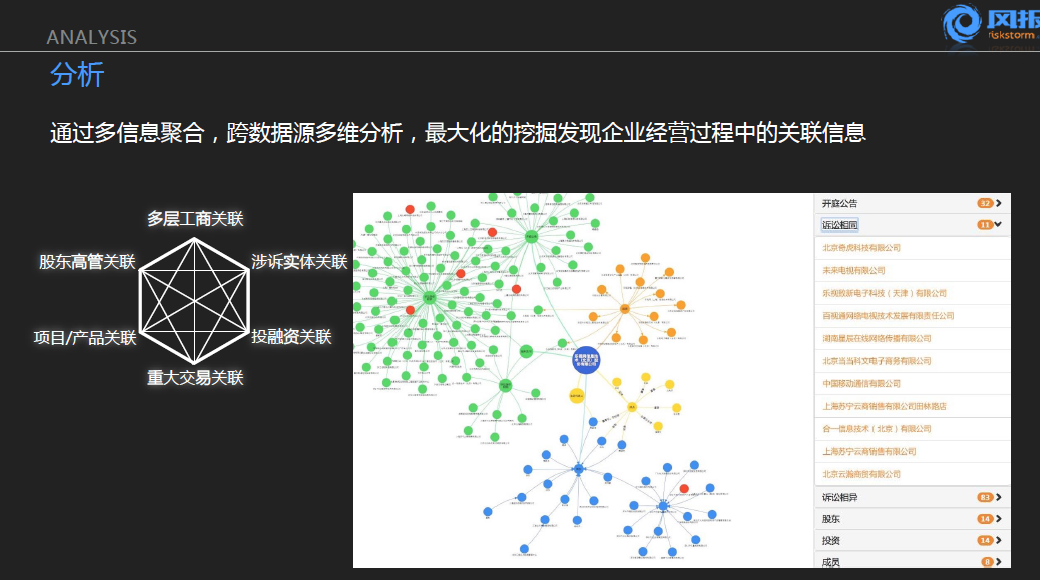
上图显示的这块也是我们在这个系统里面做的比较有特色的,也就是刚才提到的公开的媒体数据分析。我们不仅仅是把这样的媒体数据进行简单的更新,而是会对与之相关的不同类型的新闻进行相应的提取。有些是关于财务方面的信息,有些是关于口碑的信息。有些关于纠纷的信息等等。我们在这个系统里面透过这样一个筛选器就能找到与之对应的内容。所以我们在系统里面也会对不同个体间的关联进行重点的挖掘,包括我所关注的企业间的利益纠纷,投资关系灯各类信息。这块也是我们在企业的信息里面比较典型的自然语言的挖掘的应用,不光是把这样信息逐条地分类提取出来,而是对它们进行总结和归纳。
我们自己也开发了一套精确度较高的命名实体引擎。大家可以看到,当我们在输入乐事网的时候,便可以从系统中得出一个全面且精确的信息汇总。屏幕上的是我们现在已经对外开放综合搜索界面,大家如果有兴趣的话直接可以在手机或电脑上使用www.riskstorm.com输入任何关健词,就可以看到这样一个界面,系统便会根据用户输入的关键词,与之相关的公司等各类信息做一个综合的分析和总结。
背后的奥秘——自然语言
之前的部分更多的是和大家分享了一下这个产品从去年到现在实现的一些功能。后半部分会和大家分享一些自然语言的处理,包括企业情报分析里面比较典型的一些自然语言相关分析的运用。
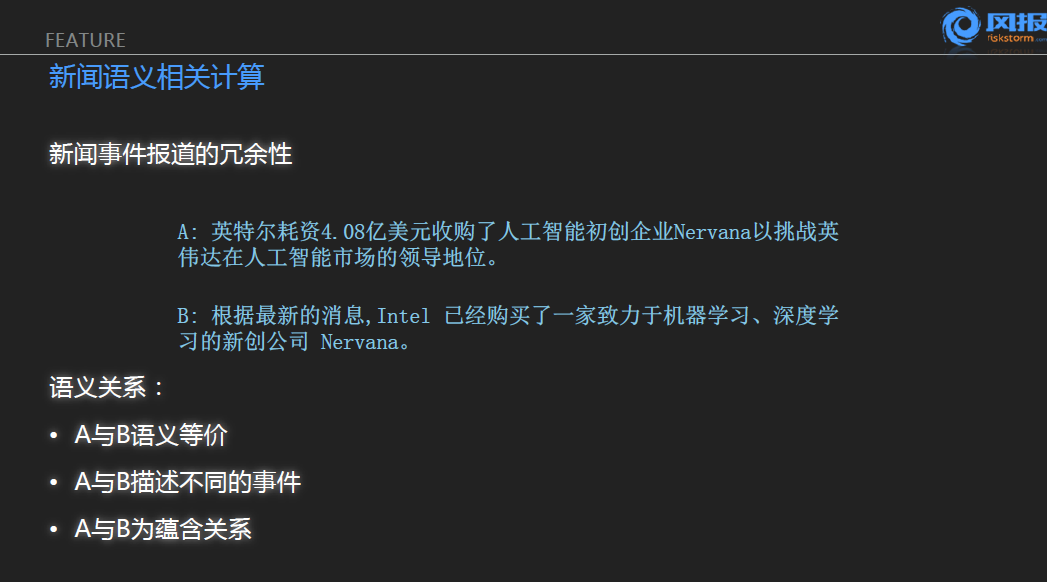
第一块的应用是跟大家分享的是新闻语义的相关计算,这个是比较直观理解的问题,通常就捕捉的信息是数以百万计的,比如万科的一个股权之争的事件可能有几百个平面媒体或者上千个网络自媒体都会进行大肆的讨论。对于这样的情况,当我们输入一个相应的关键词后,可能是翻上10页的前100条信息讲的是同样一件事情,这对于信息的整理和浏览是一个非常低效的工作。再举个例子,前几天英特尔以4.08亿美元收购了一家公司,这之中我们得到了两条信息,实际上我们人其实可以看的出来,这两个字符串之间存在着很大的差异,所以我们在这样的一个问题当中,实际上是把新闻的事件的语义相关性总结成三类。
- 第一类是A语义B,两条信息是语义的等价,也就是说在这两条信息当中会认为任何一条信息其实已经足够表达完整事件的信息。
- 第二类这个关系我们会认为A与B我们描述的是不同的事情,也就是说虽然都是关于因特尔的投融资事件,因特尔在最近一年内频繁的发生了一起比较著名的投融资的事件,他收购了A公司跟他收购的B公司虽然他可能在字符的级别这两个事非常相似,但实际上在语义的级别是完全不同的事情。这个也是我们希望在语义关系里面希望做的一个区分。
- 第三类就是A与B其实是蕴含关系,刚刚举的这个因特尔投融资的事件,实际上我们会认为B语句中实际上是A蕴含在B当中的,因为他们都提到了因特尔的投融资事件。并且在A的信息里面还包含了额外的一个观念信息,就是一个因特尔的收购的一个价格,所以对于这类的信息在我们的规则体系里面我们会认为A和B实际上是一个蕴含关系。

而蕴含关系当中我们就希望找到那条包含最多的信息的那条,然后呈现给大家,而不是把所有的被蕴含的集团提供给用户。而这样一个问题实际上大家如果对经济学比较了解话可以把它看作经典的有监督的分类的一个问题。当我们给定A和B的相应的这个事件时,我们希望求得这两个事件给定定义中的等价关系、不同的事件或者包含的关系。
那么最传统的也是最经典的去解决这个问题的方法:我们往往是在寻找一个大F,这个F是根据我们给定的A和B的这两个事件或者说从计算机角度的话那么我们希望得到区分刚才我们所说的三类的特点。而最后我们把这样的一个问题转化成比较经典的在高危的空间寻找一个面积做区分。像向量技术的这类问题,就是在这样一个传统的方法当中,在相关的工程上的经验就会发现其实最难的部分就是在于如何F。

像我们刚才传统的方法其实是比较挑战的环节:第一个是我们采用人工的知识构造一个超平面可分的函数,然后该函数势必在构造过程当中产生的高位的稀疏的特征。而很多在计算F的过程当中我们用到的一些子过程他实际上产生的比较高的时间常数,包括我们提到的BLEU函数。
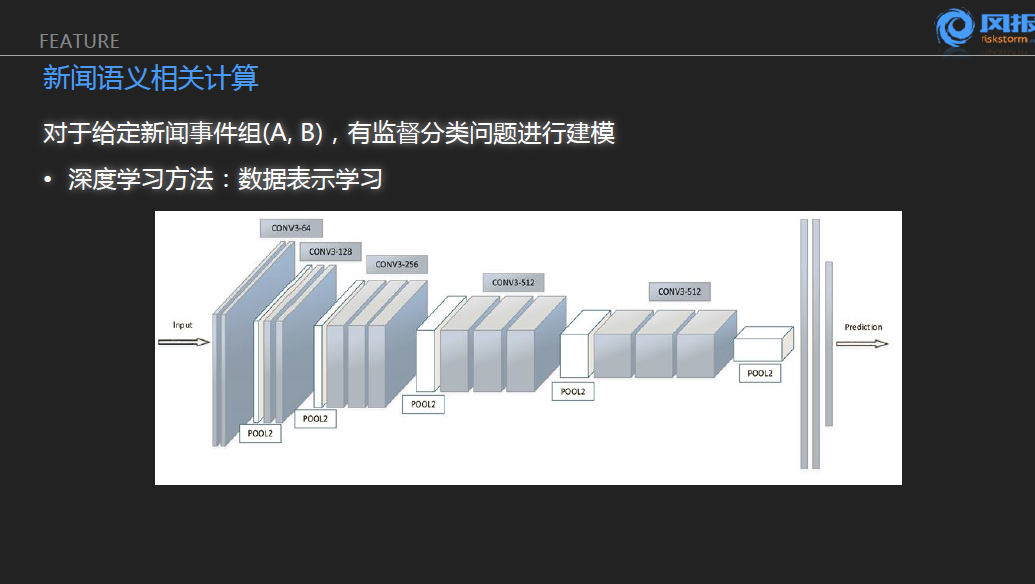
我们在第二个版本当中实现语义的相关性的计算实际上用到了深度学习的方法,,采用深度学习方法,最重要的是希望对于一个原始的文本去生成一个相对的能够高度抽象语义的特征表示。从上面的示意图可以看到相当于通过一个四层的CONV的络对于每一篇文章和每一篇事件得到1000位的的实向量的表达,并且所有后续的计算,我们希望借助于这样一个实数向量能够去简单的运算即可。
关于整个网络的应用

这一块是关于整个网络的应用。如果大家对图像识别比较熟悉的话,这实际上是类似于牛津大学提出一个网络结构。最后一层的输出一个1000维的语义向量,得到了语义指纹的VA-VB的绝对值和VA×VB的两千位的向量,再进行计算。
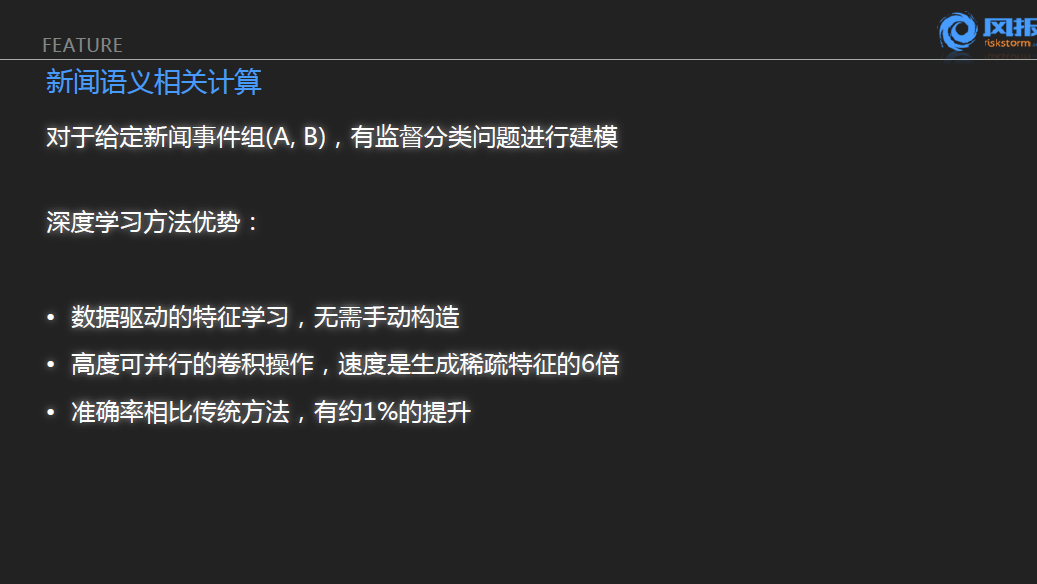
对比这两个方法,可以看到深度学习带来的优势:首先它几乎是一个纯粹的数据驱动为特征的学习方法,无需手工构造;其次高度可并行的卷积操作,速度是生成稀疏特征的6倍;此外,准确率相比传统方法,有约1%的提升。
关系抽取的计算
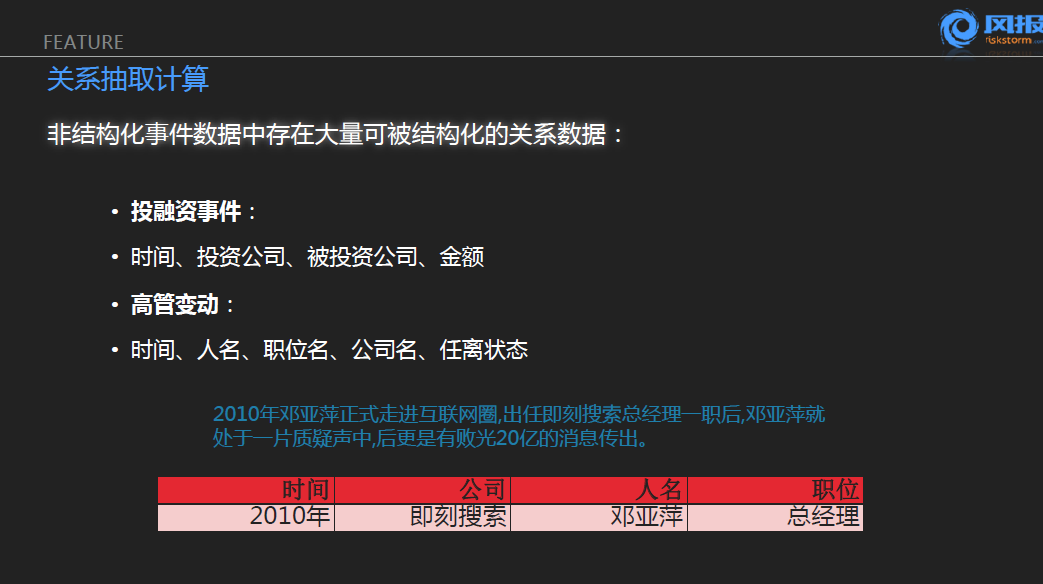
第二块是关系抽取的计算。刚才说的到对于大量的新闻报道,很多报道是有一定格式化类型的,就像投融资事件,它往往具有一些特性,比如说它应该涉及到什么时间、投资的公司是谁、被投资的公司是谁、它的金额是多少。当然这里面特定的信息一篇新闻报道不一定会出现,但我们希望上述信息在这个报道里面出现的话,能够把这样一篇非结构性报道转换成一个结构化的表格或信息。
在这里我举了一个关于邓亚萍的例子,这也是从我们的新闻库里面抽取出来的一句话,里面说到2010年邓亚萍正式走进互联网,出任即刻搜索总经理一职之后,邓亚萍处于一片质疑声中,后更是有败光20亿的新闻传出。实际上对于这样一句话,它有一些是直接描述到我们说的所谓的高管变动,然后有一些可能有其他语义的信息。但我们想的是:对这样一个关系抽取任务而言,我们可以直接得到的信息是什么呢?邓亚萍在什么时间担任这家公司的总经理的?我们希望直接从这种无结构的信息中得到这么一个结构。
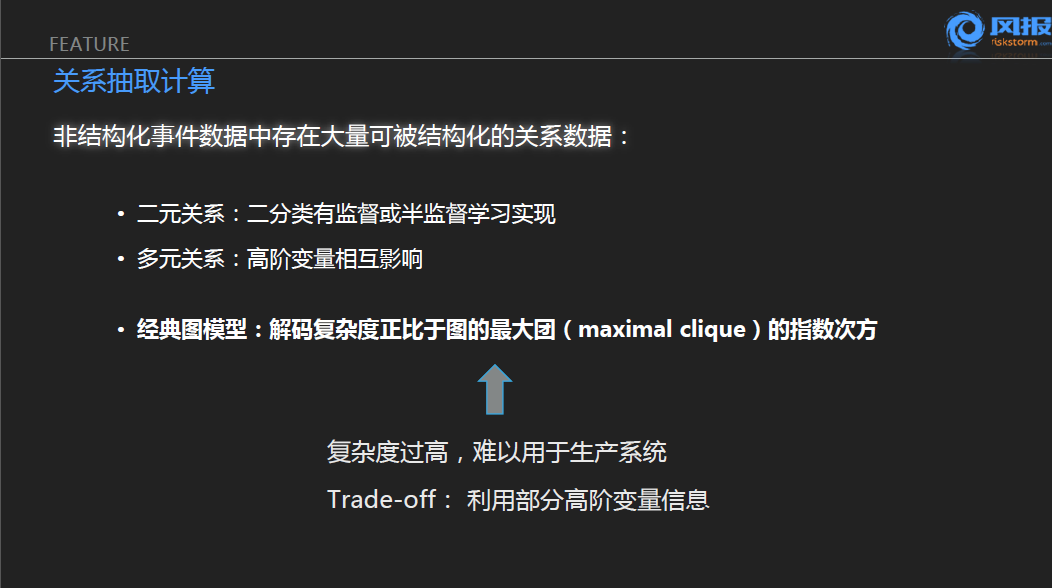
实际上大家要是对关系指令这类问题比较熟悉的话,会发现它们在学术界也有很多不同的看法。比如可以简单的认为任职离职关系等等都是简单的二元关系。既然是二元关系,我们就可以转化成一个有监督的二分类问题来解决。但是也可以看到实际上文提到语句,它的时间、公司、人名、职位等等都是会影响到我们对信息传递的。如果我们仅仅是把它建模成一个二元关系的话,实际上丢失了很多的信息。所以不考虑复杂度,按照经典的做法,就是把刚才提到时间和人的关系,时间和公司的关系,公司人名职位等这样一些关系,都建立一些随机变量进行建模,这样的话,实际上就能够成功建模出一个多元的关系。
总结来说,所有今天跟大家分享一部分是我们的风报产品;另外一部分是该产品用到的两个比较具体的自然语言和问题应用以及所做的相应算法优化和改进。

