1、kafka是什么
-
Apache Kafka是一个开源消息系统,由Scala写成
-
Kafka最初是由LinkedIn开发,并于2011年初开源
-
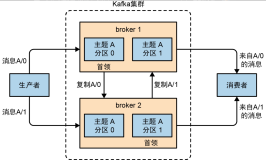
Kafka是一个分布式消息队列:生产者消费者的功能。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现
-
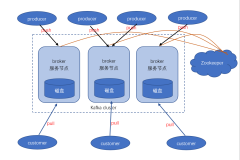
Kafka对消息保存时根据Topic进行分类,发送消息者称为producer,消息接受者称为Consumer,此外Kafka集群有多个Kafka实例组成,每个实例称为broker
-
无论是Kafka集群还是producer和consumer都依赖于zookeeper集群保存一些meta信息,来保证系统的可用性
JMS:jms是Java提供的一套技术规范。
可以用来异构系统集成通信,缓解系统瓶颈,提高系统的伸缩性增强系统用户体验,使得系统模块化和组件化变得可行并更加灵活。
类JMS消息队列,结合JMS中的两种模式,可以有多个消费者主动拉取数据,在JMS中只有点对点模式才有消费者主动拉取数据。

kafka是一个生产-消费模型。
01.Producer:生产者
只负责数据生产,生产者的代码可以集成到任务系统中。 数据的分发策略由producer决定,默认是defaultPartition Utils.abs(key.hashCode) % numPartitions
02.Broker:
当前服务器上的Kafka进程,俗称拉皮条。只管数据存储,不管是谁生产,不管是谁消费。在集群中每个broker都有一个唯一brokerid,不得重复。
03.Topic:
目标发送的目的地,这是一个逻辑上的概念,落到磁盘上是一个partition的目录。partition的目录中有多个segment组合(index,log)
一个Topic对应多个partition[0,1,2,3],一个partition对应多个segment组合。一个segment有默认的大小是1G。
每个partition可以设置多个副本(replication-factor 1),会从所有的副本中选取一个leader出来。所有读写操作都是通过leader来进行的。
特别强调,和mysql中主从有区别,mysql做主从是为了读写分离,在kafka中读写操作都是leader。
04.ConsumerGroup:
数据消费者组,ConsumerGroup可以有多个,每个ConsumerGroup消费的数据都是一样的。
可以把多个consumer线程划分为一个组,组里面所有成员共同消费一个topic的数据,组员之间不能重复消费。
(在下面代码配置文件中,可以设置groupID和读取的位置)
05.zookeeper
依赖集群保存meta信息(每次读取到哪的信息)。

2、kafka生产数据时的分组策略
默认是defaultPartition Utils.abs(key.hashCode) % numPartitions
上文中的key是producer在发送数据时传入的,produer.send(KeyedMessage(topic,myPartitionKey,messageContent))
3、kafka如何保证数据的完全生产
ack机制:broker表示发来的数据已确认接收无误,表示数据已经保存到磁盘。
0:不等待broker返回确认消息
1:等待topic中某个partition leader保存成功的状态反馈
-1:等待topic中某个partition 所有副本都保存成功的状态反馈
4、broker如何保存数据
在理论环境下,broker按照顺序读写的机制,可以每秒保存600M的数据。主要通过pagecache机制,尽可能的利用当前物理机器上的空闲内存来做缓存。
当前topic所属的broker,必定有一个该topic的partition,partition是一个磁盘目录。partition的目录中有多个segment组合(index,log)
5、partition如何分布在不同的broker上
int i = 0
list{kafka01,kafka02,kafka03}
for(int i=0;i<5;i++){
brIndex = i%broker;
hostName = list.get(brIndex)
}
6、consumerGroup的组员和partition之间如何做负载均衡
最好是一一对应,一个partition对应一个consumer。
如果consumer的数量过多,必然有空闲的consumer。
算法:
假如topic1,具有如下partitions: P0,P1,P2,P3
加入group中,有如下consumer: C1,C2
首先根据partition索引号对partitions排序: P0,P1,P2,P3
根据consumer.id排序: C0,C1
计算倍数: M = [P0,P1,P2,P3].size / [C0,C1].size,本例值M=2(向上取整)
然后依次分配partitions: C0 = [P0,P1],C1=[P2,P3],即Ci = [P(i * M),P((i + 1) * M -1)]
7、如何保证kafka消费者消费数据是全局有序的
伪命题
如果要全局有序的,必须保证生产有序,存储有序,消费有序。
由于生产可以做集群,存储可以分片,消费可以设置为一个consumerGroup,要保证全局有序,就需要保证每个环节都有序。
只有一个可能,就是一个生产者,一个partition,一个消费者。这种场景和大数据应用场景相悖。
8.kafka生产数据
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
|
import
kafka.javaapi.producer.Producer;
import
kafka.producer.KeyedMessage;
import
kafka.producer.ProducerConfig;
import
java.util.Properties;
import
java.util.UUID;
/**
* 这是一个简单的Kafka producer代码
* 包含两个功能:
* 1、数据发送
* 2、数据按照自定义的partition策略进行发送
* KafkaSpout的类
*/
public
class
KafkaProducerSimple {
public
static
void
main(String[] args) {
//1、指定当前kafka producer生产的数据的目的地
//创建topic可以输入以下命令,在kafka集群的任一节点进行创建。
//bin/kafka-topics.sh --create --zookeeper zk01:2181 --replication-factor 1 --partitions 1 --topic test
String TOPIC =
"orderMq"
;
//2、读取配置文件
Properties props =
new
Properties();
//key.serializer.class默认为serializer.class
props.put(
"serializer.class"
,
"kafka.serializer.StringEncoder"
);
//kafka broker对应的主机,格式为host1:port1,host2:port2
props.put(
"metadata.broker.list"
,
"kafka01:9092,kafka02:9092,kafka03:9092"
);
// request.required.acks,设置发送数据是否需要服务端的反馈,有三个值0,1,-1
// 0,意味着producer永远不会等待一个来自broker的ack,这就是0.7版本的行为。这个选项提供了最低的延迟,但是持久化的保证是最弱的,当server挂掉的时候会丢失一些数据。
// 1,意味着在leader replica已经接收到数据后,producer会得到一个ack。这个选项提供了更好的持久性,因为在server确认请求成功处理后,client才会返回。如果刚写到leader上,还没来得及复制leader就挂了,那么消息才可能会丢失。
// -1,意味着在所有的ISR都接收到数据后,producer才得到一个ack。这个选项提供了最好的持久性,只要还有一个replica存活,那么数据就不会丢失
props.put(
"request.required.acks"
,
"1"
);
// 可选配置,如果不配置,则使用默认的partitioner partitioner.class
// 默认值:kafka.producer.DefaultPartitioner
// 用来把消息分到各个partition中,默认行为是对key进行hash。
props.put(
"partitioner.class"
,
"cn.my.storm.kafka.MyLogPartitioner"
);
// props.put("partitioner.class", "kafka.producer.DefaultPartitioner");
//3、通过配置文件,创建生产者
Producer<String, String> producer =
new
Producer<String, String>(
new
ProducerConfig(props));
//4、通过for循环生产数据
for
(
int
messageNo =
1
; messageNo <
100000
; messageNo++) {
// String messageStr = new String(messageNo + "注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey," +
// "注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发" +
// "注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发" +
// "注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发" +
// "注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发" +
// "注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发" +
// "注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发" +
// "注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发" +
// "用来配合自定义的MyLogPartitioner进行数据分发");
// 5、调用producer的send方法发送数据
// 注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发
producer.send(
new
KeyedMessage<String, String>(TOPIC, messageNo +
""
,
"appid"
+ UUID.randomUUID() +
"itcast"
));
}
}
}
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
import
kafka.producer.Partitioner;
import
kafka.utils.VerifiableProperties;
import
org.apache.log4j.Logger;
public
class
MyLogPartitioner
implements
Partitioner {
private
static
Logger logger = Logger.getLogger(MyLogPartitioner.
class
);
public
MyLogPartitioner(VerifiableProperties props) {
}
public
int
partition(Object obj,
int
numPartitions) {
return
Integer.parseInt(obj.toString())%numPartitions;
// return 1;
}
}
|
9.kafka消费数据(低阶)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
|
import
kafka.consumer.Consumer;
import
kafka.consumer.ConsumerConfig;
import
kafka.consumer.ConsumerIterator;
import
kafka.consumer.KafkaStream;
import
kafka.javaapi.consumer.ConsumerConnector;
import
kafka.message.MessageAndMetadata;
import
java.util.HashMap;
import
java.util.List;
import
java.util.Map;
import
java.util.Properties;
import
java.util.concurrent.ExecutorService;
import
java.util.concurrent.Executors;
public
class
KafkaConsumerSimple
implements
Runnable {
public
String title;
public
KafkaStream<
byte
[],
byte
[]> stream;
public
KafkaConsumerSimple(String title, KafkaStream<
byte
[],
byte
[]> stream) {
this
.title = title;
this
.stream = stream;
}
@Override
public
void
run() {
System.out.println(
"开始运行 "
+ title);
ConsumerIterator<
byte
[],
byte
[]> it = stream.iterator();
/**
* 不停地从stream读取新到来的消息,在等待新的消息时,hasNext()会阻塞
* 如果调用 `ConsumerConnector#shutdown`,那么`hasNext`会返回false
* */
while
(it.hasNext()) {
MessageAndMetadata<
byte
[],
byte
[]> data = it.next();
String topic = data.topic();
int
partition = data.partition();
long
offset = data.offset();
String msg =
new
String(data.message());
System.out.println(String.format(
"Consumer: [%s], Topic: [%s], PartitionId: [%d], Offset: [%d], msg: [%s]"
,
title, topic, partition, offset, msg));
}
System.out.println(String.format(
"Consumer: [%s] exiting ..."
, title));
}
public
static
void
main(String[] args)
throws
Exception{
Properties props =
new
Properties();
props.put(
"group.id"
,
"dashujujiagoushi"
);
props.put(
"zookeeper.connect"
,
"zk01:2181,zk02:2181,zk03:2181"
);
props.put(
"auto.offset.reset"
,
"largest"
);
props.put(
"auto.commit.interval.ms"
,
"1000"
);
props.put(
"partition.assignment.strategy"
,
"roundrobin"
);
ConsumerConfig config =
new
ConsumerConfig(props);
String topic1 =
"orderMq"
;
String topic2 =
"paymentMq"
;
//只要ConsumerConnector还在的话,consumer会一直等待新消息,不会自己退出
ConsumerConnector consumerConn = Consumer.createJavaConsumerConnector(config);
//定义一个map
Map<String, Integer> topicCountMap =
new
HashMap<>();
topicCountMap.put(topic1,
3
);
//Map<String, List<KafkaStream<byte[], byte[]>> 中String是topic, List<KafkaStream<byte[], byte[]>是对应的流
Map<String, List<KafkaStream<
byte
[],
byte
[]>>> topicStreamsMap = consumerConn.createMessageStreams(topicCountMap);
//取出 `kafkaTest` 对应的 streams
List<KafkaStream<
byte
[],
byte
[]>> streams = topicStreamsMap.get(topic1);
//创建一个容量为4的线程池
ExecutorService executor = Executors.newFixedThreadPool(
3
);
//创建20个consumer threads
for
(
int
i =
0
; i < streams.size(); i++)
executor.execute(
new
KafkaConsumerSimple(
"消费者"
+ (i +
1
), streams.get(i)));
}
}
|
10.kafka和zookeeper使用JavaAPI能够拉取到数据(高阶消费)
properties配置文件
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
###zookeeper\u548ckafka\u914d\u7f6e\u5730\u5740
zk.connect=xxxxx
#zk.connect=xxxxx
###kafka\u6d88\u8d39\u7684group\u5fc5\u987b\u8c03\u6574\u4e3a\u72ec\u5360
adinfo.log.group.name=qinbin_ad_interfaceLog_20171218
###kafka\u7684topic.\u9700\u8981\u548cadstat\u6a21\u5757\u7684kafka topic\u4e00\u81f4
adinfo.log.topic.name=ad_interfaceLog
adinfo.log.queue.max=
10000
adinfo.log.list.size=
1
###\u4e2d\u95f4\u7ed3\u679c\u4fdd\u5b58\u65e5\u5fd7
adinfo.log.pathFile=E:/opt/realtime/avro/file/
###\u9ed8\u8ba4\u4e0d\u8981\u52a8
adinfo.statistics.time=
120000
adinfo.statistics.commitSize=
3000
|
kafka配置文件(注意groupID)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
<?xml version=
"1.0"
encoding=
"UTF-8"
?>
<beans xmlns=
"http://www.springframework.org/schema/beans"
xmlns:xsi=
"http://www.w3.org/2001/XMLSchema-instance"
xmlns:
int
=
"http://www.springframework.org/schema/integration"
xmlns:
int
-kafka=
"http://www.springframework.org/schema/integration/kafka"
xmlns:task=
"http://www.springframework.org/schema/task"
xsi:schemaLocation="http:
//www.springframework.org/schema/integration/kafka http://www.springframework.org/schema/integration/kafka/spring-integration-kafka.xsd
http:
//www.springframework.org/schema/integration http://www.springframework.org/schema/integration/spring-integration.xsd
http:
//www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http:
//www.springframework.org/schema/task http://www.springframework.org/schema/task/spring-task.xsd">
<
int
:channel id=
"inputFromAdinfo"
>
<
int
:queue/>
</
int
:channel>
<
int
-kafka:inbound-channel-adapter
id=
"kafkaInboundChannelAdinfo"
kafka-consumer-context-ref=
"consumerContextAdinfo"
auto-startup=
"true"
channel=
"inputFromAdinfo"
>
<
int
:poller fixed-delay=
"10"
time-unit=
"MILLISECONDS"
max-messages-per-poll=
"5"
/>
</
int
-kafka:inbound-channel-adapter>
<bean id=
"consumerPropertiesAdinfo"
class
=
"org.springframework.beans.factory.config.PropertiesFactoryBean"
>
<property name=
"properties"
>
<props>
<prop key=
"auto.offset.reset"
>smallest</prop>
<prop key=
"socket.receive.buffer.bytes"
>
314572
</prop> <!-- 5M -->
<prop key=
"fetch.min.bytes"
>
26214
</prop><!-- 256k -->
<prop key=
"fetch.message.max.bytes"
>
104857
</prop><!-- 3M -->
<prop key=
"fetch.wait.max.ms"
>
5000
</prop>
<prop key=
"auto.commit.interval.ms"
>
2000
</prop>
<prop key=
"rebalance.backoff.ms"
>
5000
</prop>
<prop key=
"rebalance.max.retries"
>
5
</prop>
</props>
</property>
</bean>
<
int
-kafka:consumer-context id=
"consumerContextAdinfo"
consumer-timeout=
"4000"
zookeeper-connect=
"zookeeperConnectAdinfo"
consumer-properties=
"consumerPropertiesAdinfo"
>
<
int
-kafka:consumer-configurations>
<!-- 需要注意如果两个线程同时互不相干去消费通一个topic,则需要注意group-id不能重复 -->
<
int
-kafka:consumer-configuration group-id=
"${adinfo.log.group.name}"
max-messages=
"500"
>
<
int
-kafka:topic id=
"${adinfo.log.topic.name}"
streams=
"1"
/>
</
int
-kafka:consumer-configuration>
</
int
-kafka:consumer-configurations>
</
int
-kafka:consumer-context>
<
int
-kafka:zookeeper-connect id=
"zookeeperConnectAdinfo"
zk-connect=
"${zk.connect}"
zk-connection-timeout=
"6000"
zk-session-timeout=
"6000"
zk-sync-time=
"2000"
/>
</beans>
|
然后在spring配置文件中import kafka的配置文件
Java接收:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
|
import
java.io.UnsupportedEncodingException;
import
java.util.Collection;
import
java.util.Iterator;
import
java.util.List;
import
java.util.Map;
import
java.util.Map.Entry;
import
java.util.Set;
import
java.util.concurrent.ConcurrentHashMap;
import
javax.annotation.Resource;
import
org.apache.avro.io.DatumReader;
import
org.apache.avro.specific.SpecificDatumReader;
import
org.slf4j.Logger;
import
org.slf4j.LoggerFactory;
import
org.springframework.integration.channel.QueueChannel;
import
org.springframework.messaging.Message;
import
com.ElasticSearchServiceImpl;
import
com.IElasticSearchService;
import
com.AdInfoRealTimeThread;
import
com.ConfigUtil;
import
com.AdInfo;
public
class
AdInfoConsumer {
// DatumReader<AdInfo> adInfoDatumReader = new
// SpecificDatumReader<AdInfo>(AdInfoOld.getClassSchema(),AdInfo.getClassSchema());
DatumReader<AdInfo> adInfoDatumReader =
new
SpecificDatumReader<AdInfo>(AdInfo.
class
);
private
Logger logger = LoggerFactory.getLogger(AdInfoConsumer.
class
);
@Resource
(type = ElasticSearchServiceImpl.
class
)
private
IElasticSearchService elasticSearchServiceImpl;
@Resource
(type = ConfigUtil.
class
)
private
ConfigUtil configUtil;
private
QueueChannel queueChannel;
public
QueueChannel getQueueChannel() {
return
queueChannel;
}
public
void
setQueueChannel(QueueChannel queueChannel) {
this
.queueChannel = queueChannel;
}
private
AdInfoRealTimeThread adInfoRealTimeThread;
public
AdInfoRealTimeThread getAdInfoRealTimeThread() {
return
adInfoRealTimeThread;
}
public
void
setAdInfoRealTimeThread(AdInfoRealTimeThread adInfoRealTimeThread) {
this
.adInfoRealTimeThread = adInfoRealTimeThread;
}
public
void
consumerLog()
throws
UnsupportedEncodingException {
@SuppressWarnings
(
"rawtypes"
)
Message msg;
while
((msg = queueChannel.receive()) !=
null
) {
// msg = queueChannel.receive();
try
{
Map<String, Object> map = (Map<String, Object>) msg.getPayload();
Set<Entry<String, Object>> set = map.entrySet();
for
(Map.Entry<String, Object> entry : set) {
String topic = entry.getKey();
ConcurrentHashMap<Integer, List<
byte
[]>> messages = (ConcurrentHashMap<Integer, List<
byte
[]>>) entry
.getValue();
Collection<List<
byte
[]>> values = messages.values();
for
(Iterator<List<
byte
[]>> iterator = values.iterator(); iterator.hasNext();) {
List<
byte
[]> list = iterator.next();
for
(
byte
[] object : list) {
String message =
new
String(object,
"UTF-8"
);
StringBuilder megJson =
new
StringBuilder(message);
megJson.delete(
0
, megJson.indexOf(
"="
) +
1
);
// logger.info("json:"+megJson.toString());
// adinfoToSaveES.saveAdLogToEs(megJson.toString());
elasticSearchServiceImpl.executeSearch(configUtil.clusterName,megJson.toString());
//System.out.println(megJson.toString());
}
}
}
}
catch
(Exception ex) {
logger.error(
"===AdInfoConsumer consumer is exception"
, ex);
}
}
logger.error(
"====AdInfoConsumer receive is interrupted===="
);
}
/*
* public void consumerLog() throws UnsupportedEncodingException {
*
* @SuppressWarnings("rawtypes") Message msg; while ((msg =
* queueChannel.receive()) != null) {
*
* try {
*
* Map<String, Object> map = (Map<String, Object>) msg.getPayload();
* Set<Entry<String, Object>> set = map.entrySet(); for (Map.Entry<String,
* Object> entry : set) { // String topic = entry.getKey();
* ConcurrentHashMap<Integer, List<byte[]>> messages =
* (ConcurrentHashMap<Integer, List<byte[]>>) entry .getValue();
* Collection<List<byte[]>> values = messages.values(); for
* (Iterator<List<byte[]>> iterator = values.iterator(); iterator.hasNext();) {
* List<byte[]> list = iterator.next(); for (byte[] object : list) {
*
* try { Decoder decoder = DecoderFactory.get().binaryDecoder(object, null);
*
* AdInfo adInfo = adInfoDatumReader.read(null, decoder);
*
* String json=adInfo.toString(); System.out.println("*************"+json);
* //logger.info("json:"+json); //adInfoRealTimeThread.statistics(json);
*
* } catch (Exception e) {
* logger.error("===AdInfoConsumer consumer one is exception", e); }
*
*
* } } } } catch (Exception ex) {
* logger.error("===AdInfoConsumer consumer is exception", ex); } }
*
* logger.error("====AdInfoConsumer receive is interrupted===="); }
*/
}
|