
MaxCompute管家使用前提
1、用户购买了 MaxCompute 预付费CU资源,60CU以上的用户(备注:CU过小无法发挥计算资源及管家的优势)。
2、支持区域,MaxCompute 华北2北京、华东2上海、华南1深圳 3个Region的用户。
系统状态
通过系统状态了解CU计算资源和存储的消耗情况, 如图所示:

上图①可以选择所查看的资源组,根据选择的资源组,展示当前资源组的消耗信息和当前存储量。
上图②可以选择查看所选资源组的时间区间,选择的区间不同,资源组数据展示的粒度不同(计算资源CU每6分钟采集一次/存储每一小时采集一次)。
Quota设置
Quota是指资源组。举个例子,有用户购买了100CU,表示他全部 Quota 的额度是100CU。该用户可以通过大数据管家来新建 Quota,这样就可以对 Quota 进行资源分配。运维人员可以很方便的将各个项目的资源隔离,保证重要项目的计算资源充沛。
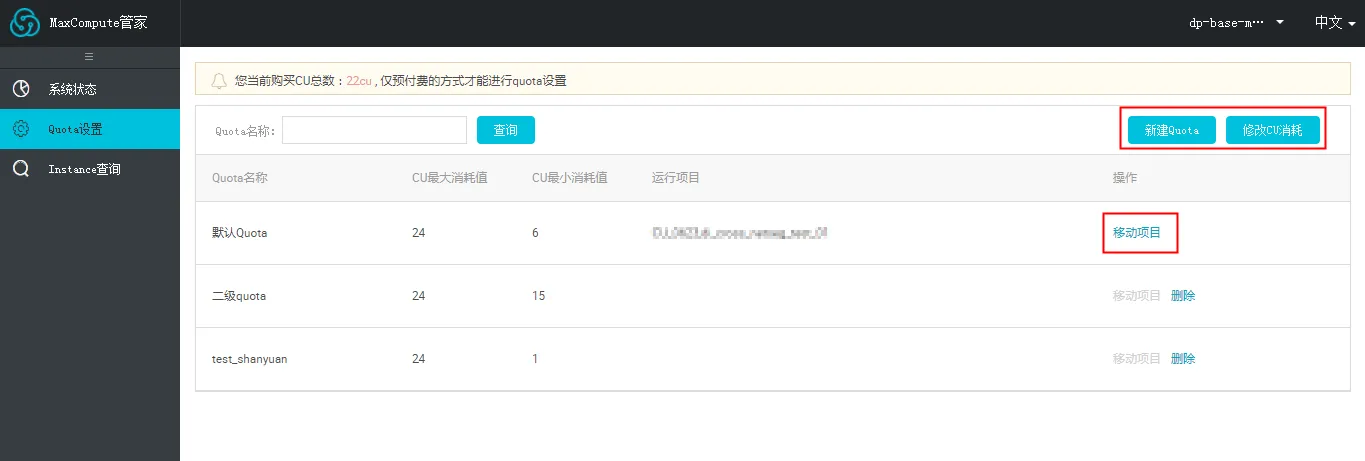
新建Quota:新建一个 Quota 组,建好后可以通过移动项目功能,来将项目移动到 Quota 下。创建的 Quota 可以删除,但若当前 Quota 下有项目,则无法删除。
修改CU消耗:建好的 Quota 支持修改CU最小消耗值。
移动项目:支持将当前 Quota 下的项目移动至其他 Quota 下,新建的 Quota 就可以通过这个移动项目这个功能来做到资源隔离。
删除:支持删除 Quota 组,若当前 Quota 下有项目,则无法删除。
注意:计算资源CU升级和降配时,默认Quota组Max、Min会相应变化,其他组不会改变配置。如果降配时,剩余默认Min组小于降配额度时,会发生降配失败。
Quota组配置示例,比如60CU,两个部门使用。
资源组独享,【MaxCU,MinCU】,A组【40,40】,B组【20,20】
资源组倾斜, 【MaxCU,MinCU】,A组【60,40】,B组【40,20】
Instance查询
通过计算任务监控,了解当前任务排队状态,资源被哪些任务抢占,然后做分析或 Kill,详细如下图所示:

可以根据 Quota 组名称和项目名称两个维度来筛选,精确搜索。
InstanceId:每一个 MaxCompute任务都会有一个 Instance,通过点击 InstanceId 可以跳转到Logview页面,查看具体的任务进度,查看Logview的方法请参考:
Logview查看。
账号:运行这个MaxCompute任务的操作人,可以根据这个账号信息找到任务所属的责任人,如果该任务占用太多资源而影响其他任务的运行,可以与该责任人联系,是否 kill 掉该 Instance,Kill 掉 Instance 的方法请参考:
实例操作。
MaxCompute Project:当前 Instance 所属的项目名称。
cpu消耗: 当前quota组实际使用的CPU资源比例。
memory消耗: 当前quota组实际使用的内存资源 比例。
提交时间:当前 Instance 任务的提交时间。
等待时间:等待运行资源的时长。
操作:可以在此处查看当前 Instance 任务的状态,此处会显示当前状态和历史状态。
华北2(北京)Region MaxCompute购买地址:https://common-buy.aliyun.com/?commodityCode=odpsplus#/buy
欢迎加入“数加·MaxCompute购买咨询”钉钉群(群号: 11782920)进行咨询,群二维码如下:


