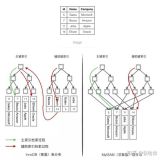
用示例说明索引数据块中出现热块&Latch的场景,并给出解决方案推荐
引言:索引的热块其实和数据块的热块发生的原理大相径庭,也都是因为大量会话一起访问同一个索引块造成的,我们的解决方案有反向索引,分区索引等。我们说任何一种方式都不是完美的,有优点就必然有缺点,我们把包含索引键值的索引块从顺序排列打散到无序排列,降低了latch争用,同时也增加了oracle扫描块的数量。我们在实际使用时多测试取长补短,以提高系统的整体性能为目标。
LEO1@LEO1>create table leo1 (id number , name varchar2(200)); 创建了一个leo1表
Table created.
LEO1@LEO1>insert into leo1 (id,name) select object_id,object_name from dba_objects; 将dba_objects前2个字段复制到leo1表中。
71966 rowscreated.
LEO1@LEO1>select id,name from leo1 where rownum<10; 好已经完成
ID NAME
----------------------------------------------------
673 CDC_CHANGE_SOURCES$
674 I_CDC_CHANGE_SOURCES$
675 CDC_CHANGE_SETS$
676 I_CDC_CHANGE_SETS$
677 CDC_CHANGE_TABLES$
678 I_CDC_CHANGE_TABLES$
679 CDC_SUBSCRIBERS$
680 I_CDC_SUBSCRIBERS$
681 CDC_SUBSCRIBED_TABLES$
LEO1@LEO1>create index leo1_index on leo1(id); 在leo1表上id列创建一个索引
Index created.
LEO1@LEO1>execute dbms_stats.gather_table_stats('LEO1','LEO1',cascade=>true); 对表和索引一起做一个分析,cascade=>true 指的是级联表上的索引一起做分析
PL/SQL proceduresuccessfully completed.
LEO1@LEO1>create table leo2 (id number,name varchar2(200)); 创建leo2表
Table created.
LEO1@LEO1>insert into leo2 (id,name) select object_id,object_name from dba_objects; 插入71968行
71968 rowscreated.
为什么比leo1表多了2行呢,就是多了leo1和leo1_index这2个对象,我们刚刚建的。
LEO1@LEO1>create index leo2_index on leo2(id) reverse; 创建一个反向索引
Index created.
LEO1@LEO1>execute dbms_stats.gather_table_stats('LEO1','LEO2',cascade=>true); 做分析
PL/SQL proceduresuccessfully completed.
LEO1@LEO1>select index_name,index_type,table_name,status from dba_indexes wheretable_name in ('LEO1','LEO2');
INDEX_NAME INDEX_TYPE TABLE_NAME STATUS
--------------------------------------------------------- ------------------------------ --------
LEO1_INDEX NORMAL LEO1 VALID
LEO2_INDEX NORMAL/REV LEO2 VALID
LEO2_INDEX 是反向索引,我们使用它来把顺序的索引块反向成无序索引块存储,这样我们在查询一个区间范围时,索引键值就会落在不连续的索引块上,防止热块的产生,降低“latch 链表”争用。这可能算是反向索引唯一被使用的情况。因为反向索引不支持index range scan功能,只支持index full scan 全索引扫描,如何理解呢,举个简单的例子 反向索引 不能帮你检索出 id> 1 and id < 10 的行,但可以帮你检索出 id=10的行,也就是说对范围扫描效率低,等值扫描效率还是很高的。
LEO1@LEO1> set autotrace on; 启动执行计划
LEO1@LEO1>select count(*) from leo1 whereid<100; 这是B-TREE索引执行计划
COUNT(*)
----------
98
Execution Plan
----------------------------------------------------------
Plan hash value:423232053
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 5 | 2 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1| 5 | | |
|* 2 | INDEX RANGE SCAN| LEO1_INDEX | 96 | 480 | 2 (0)| 00:00:01 |
--------------------------------------------------------------------------------
索引范围扫描,因为我们查询索引键值都是存放在连续的索引块中,所以只有仅仅的2个一致性读,它只扫描符合条件的索引块就能找到相应的记录。
PredicateInformation (identified by operation id):
---------------------------------------------------
2 - access("ID"<100)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
2 consistent gets
0 physical reads
0 redo size
526 bytes sent via SQL*Net to client
523 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
LEO1@LEO1>select count(*) from leo2 whereid<100; 反向索引执行计划
COUNT(*)
----------
98
Execution Plan
----------------------------------------------------------
Plan hash value:1710468575
------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 5 | 45 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 5 | | |
|* 2 | INDEX FAST FULL SCAN| LEO2_INDEX | 96 | 480 | 45 (0)| 00:00:01 |
------------------------------------------------------------------------------------
快速全索引扫描,因为我们查询索引键值在反向索引中是存放在不连续的索引块上,由于索引键值在磁盘物理块位置上的无序,因此只能执行全索引扫描,即所有的索引块全扫一遍抽取符合条件的记录出来,从这里就可以看出检索相同行数,全索引扫描执行计划要比索引范围扫描执行计划多扫了84倍的块,那么反过来看“latch 争用”的几率小了84倍。
PredicateInformation (identified by operation id):
---------------------------------------------------
2 - filter("ID"<100)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
168 consistent gets
0 physical reads
0 redo size
526 bytes sent via SQL*Net to client
523 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
下面我写个存储过程,作用呢就是通过索引频繁的访问表中的记录,当有多个会话一起执行时看看有没有发生争用
存储过程
LEO1@LEO1>create or replace procedure p10
as
l number;
begin
for i in 1..50000
loop
select count(*) into l from leo1 whereid<10000;
end loop;
dbms_output.put_line('successfully');
end;
/
2 3 4 5 6 7 8 9 10 11
Procedure created.
三个会话同时反复访问表leo1
session:19
LEO1@LEO1>execute p10;
successfully
PL/SQL proceduresuccessfully completed.
session:147
LEO1@LEO1>execute p10;
successfully
PL/SQL procedure successfullycompleted.
session:148
LEO1@LEO1>execute p10;
successfully
PL/SQL proceduresuccessfully completed.
session:144
LEO1@LEO1>select s1.sid,s2.event from v$session s1,v$session_wait s2 where s1.sid=s2.sidand s1.status='ACTIVE' and s2.event like '%buffer%';
SID EVENT
--------------------------------------------------------------------------
19 latch: cache buffers chains
148 latch: cache buffers chains
147 latch: cache buffers chains
从会话等待事件中出现了“latch 链表”争用,在你操作的过程中可能执行一次并没有显示,因为latch等待非常快就结束了多多执行几次就能看出效果。同理访问leo2表的时候可能碰巧也会发现latch等待,由于数据分布的比较广,因此你碰到的概率就很小很小。
 用示例说明索引数据块中出现热块&Latch的场景,并给出解决方案.pdf (146.71 KB, 下载次数: 0)
用示例说明索引数据块中出现热块&Latch的场景,并给出解决方案.pdf (146.71 KB, 下载次数: 0)
本文转自 leonarding151CTO博客,原文链接:http://blog.51cto.com/leonarding/1083038,如需转载请自行联系原作者


![[MySQL优化案例]系列 — 索引、提交频率对InnoDB表写入速度的影响](https://ucc.alicdn.com/pic/developer-ecology/c2f83387419e42d79388f316eb675ec7.png?x-oss-process=image/resize,h_160,m_lfit)