数据科学关注查找噪声中隐藏的信号。这一点说起来容易做起来难,但无需依靠众多数据专家即可实现。本文介绍的定量分析技术是非常实用的入门方法(链接中提供额外信息),适用于想亲自使用基础统计技术的人员。从本质上来讲,其流程可以总结为以下四步:
1.观察:移动用户数据趋势可能会带来一些不可预料的见解,帮助更好地理解用户使用应用程序的方式、时间、地点和原因。这些见解具有潜在价值,可以据此制定后续决策,优化用户体验。
2.形成假设框架:无法获取全部信息时,需要进行归纳推理。对于移动应用程序来说,这一点显然正确,因为目标用户不可能聚在一起等着你去采访。
3.数据采集:对假设进行判断需要面对的挑战是确定对相关任务有帮助的可用证据。在我看来,这得先做好才考虑机器学习算法的细节。
4.评估假设:生成模型的出发点是希望进一步解释数据。接下来,根据模型对目前所观察到数据的解释情况,对模型可信度进行评估。
制定高质量并且切实可行的决策
数据科学可以描述为业务假设实际运行情况之间的竞争。与 Countly 合作将获取完整的移动用户行为数据集以及数据可视化所需的整套工具。定量分析需要使用完整的移动用户行为数据集,而非抽样技术分析所采集的数据,后者可能会在分析中引入不确定性的偏差。只需单击几次,就能够以可视化方式查看关于用户的各种详细信息。例如,可以使用 Countly 在多种语言环境下快速可视化应用程序用户的原始数据和百分比数据(请参见下方屏幕截图)。此方法比 Excel 更加形象生动,无需额外导出原始数据进行日常数据分析,为团队节省时间。
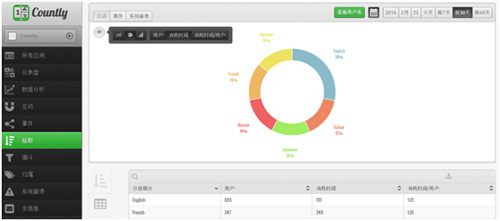
此外,Countly 可以灵活整合其他来源的移动数据和人口统计数据,例如银行可能需要从后端整合数据(年龄、估计收入、婚姻状况、最近大宗交易记录和近期地址变更),以便 Countly 更好地了解用户在应用程序内的行为并通过特定推送通知促进微目标定位。这样数据分析就能够更具有针对性,更加适应业务需要。
为了帮助您在令人兴奋的数据驱动领域中不断发展,您需要扩展成功的定义:对您来说,“成功”意味着什么?这个问题其实并不像看起来那样简单。您优先考虑什么问题?如果您重点关注应用程序内购买,那么您的目标是收入和用户生命周期价值 (LTV)。对于其他大部分不以货币化为中心的应用程序来说,主要关注点可能在于留存用户。
那么,现在我们开始观察数据。利用 Countly 您能够访问 100% 应用程序用户数据,还可以详细查看高参与度用户(假设您运营一款健身应用程序,并选择留存率作为成功标准)以及这些用户注册时执行的操作。观察高参与度用户行为模式,然后进行定量访问确定应用程序最令人兴奋的特点。随后,您的团队可以获取下载应用的初 10 天内完成对提高留存率有帮助操作的主要假设:
1.完成 3 项推荐锻炼
2.在社区发布 5 件信息
3.关注5 份健康饮食
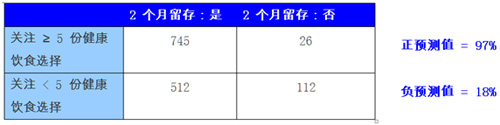
我们为每项操作定义队列,然后在采样数据上使用二分类测试比较注册 2 个月后每组用户留存表现。之后我们可以观察每项测试的正负预测值(定义如下),确定我们正在寻找的关键阈值。
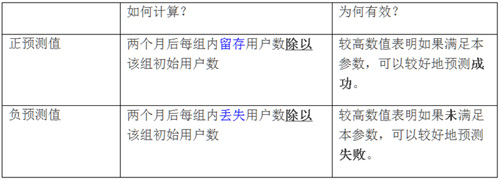
测试 1:用户在初 10 天内是否完成 ≥ 3项推荐锻炼?
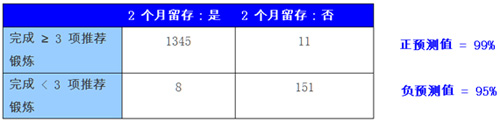
测试 2:用户在初 10 天内在社区发布 ≥ 5 件信息?

测试 3:用户在初 10 天内关注 ≥ 5 份健康饮食?
显然完成 3 项推荐锻炼胜出。因此,这项操作有较高的 2 个月留存正预测值;相反地,完成少于 3 项锻炼有较高的负预测值。这项测试可以很好地预测 2 个月留存情况:达到标准,有 99% 机率留存应用程序;未达到标准,有 95% 机率会丢失用户。
发布 5 件信息和关注 5 份健康饮食与留存情况有很大关联(因此有较高的正预测值),但未达到关键条件标准。未执行这些操作的用户仍有很高机率在 2 个月后仍留存应用程序。
到目前为止,完成推荐锻炼似乎成为关键性阈值。另一项评估要点在于让用户完成行动的价值。换言之,让用户完成 3 项推荐锻炼进而提高 2 个月后留存应用程序所需付出的代价。分析数字时,完成 3 项推荐锻炼可使 2 个月后留存机率提高大约 20 倍,而发布 5 次更新和关注 5 份健康饮食甚至无法让留存率翻倍(分别提高 1.3 倍和 1.1 倍)。你可以通过回归分析得出这一结论,但所需时间过长。如要了解更多信息,我建议阅读该URL。数据分析结果表明,值得投入时间和精力鼓励用户完成 3 项推荐锻炼。发布 5 件信息和关注 5 份健康饮食与留存情况有很大关联(因此有较高的正预测值),但未达到关键条件标准。未执行这些操作的用户仍有很高机率在 2 个月后仍留存应用程序。
如果对机器学习和更复杂的模型感兴趣,我建议针对非结构化数据使用 K 均值聚类(K-Means Clustering),使用 R 语言实现。该技术提供另一种识别与 3 个月后留存率等业务目标相关特定聚类的方法。观察结果按指定标准分为 K 组并重新分组,形成关联最为紧密的聚类(请参见以下示例)。
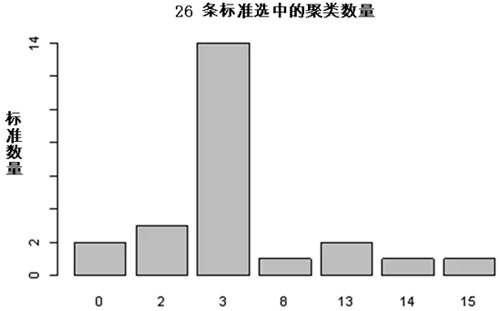
与分层聚类相比,K 均值聚类可以处理更大规模的数据集。此外,观察结果不会永远固定在一个聚类中。分析时,观察结果会移动,从而改善整体结果。要了解更多关于 K 均值聚类的信息,我建议阅读《R 语言实战》作者 Rob Kabacoff 发表的文章。
保持简洁
误差最小的通用模型最有可能准确预测未来观察结果——奥卡姆剃刀原理。确定关键性阈值时的两个重要注意事项:保持稳定简洁。如果涉及过多不同行动,将难以衡量并且可能会随时间发生变化。同时也会分散团队的注意力 — 这引出我们的下一步骤。
采取行动
既然已经确定关键指标,即必须加以克服以便提高用户满意度和参与度的阈值,那么就应该采取相应行动。Sokrati,印度领先的网络广告绩效管理公司,已成功在开节日期间展开2-3天的Facebook 活动为珠宝品牌赢了超过300%的销售增长。他们的策略包括三个步骤:
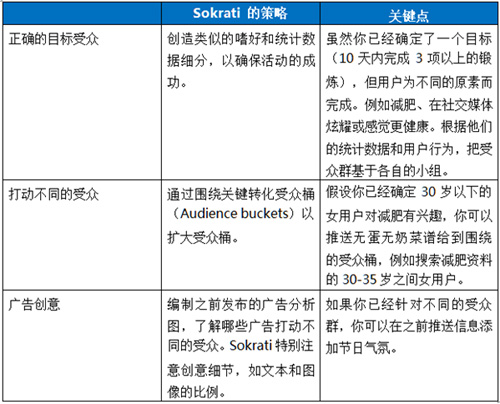
关键在于利用节日期间有针对性地鼓励更多用户尽快行动。深入挖掘不同的受众群以扩大受众群体,你会看到参与和保留度上升。我希望这些概念与结构可以帮你。欢迎你联系Countly继续讨论与分享自己的故事!


