引言
随着在CDH平台上物联网(IoT)使用案例的不断增加,针对这些工作负载的安全性显得至关重要。本篇博文对如何以安全的方式在Spark中使用来自Kafka的数据,以及针对物联网(IoT)使用案例的两个关键组件进行了说明。
Cloudera Distribution of Apache Kafka 2.0.0版本(基于Apache Kafka 0.9.0)引入了一种新型的Kafka消费者API,可以允许消费者从安全的Kafka集群中读取数据。这样可以允许管理员锁定其Kafka集群,并要求客户通过Kerberos进行身份验证。此外,也可以允许客户在与Kafka brokers(通过SSL/TLS)通信时加密数据随后,在Cloudera Distribution of Apache Kafka 2.1.0版本中,Kafka通过Apache Sentry引入了支持授权功能。这样可以允许Kafka管理员锁定某些主题,并针对特定角色和用户授予权限,充分发挥基于角色的访问控制功能。
而现在,从Cloudera Distribution of Spark 2.1的第一次发行版开始,我们已经具备了从Spark中的Kafka内安全读取数据的功能。
要求
- Cloudera Distribution Spark 2.1第一次发行版或更高版本。
- Cloudera Distribution Kafka 2.1.0版本或更高版本。
体系架构
使用Spark中新的直接连接器可以支持从安全的Kafka集群中获取消息。直接连接器不使用单独的进程(亦称为接收器)读取数据。相反,Spark驱动程序将跟踪各种Kafka主题分区的偏移量,并将偏移量发送到从Kafka中直接读取数据的执行程序中。直接连接器的简单描述如下所示。
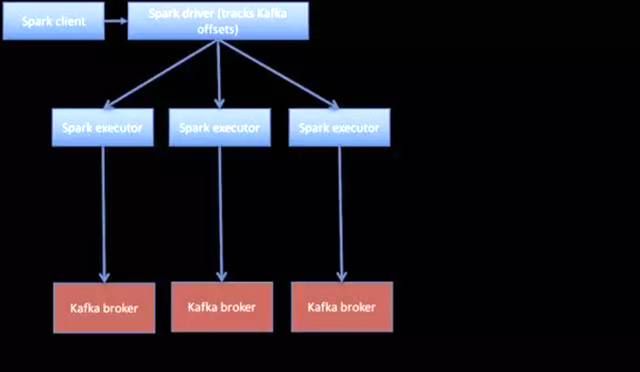
图1:Spark中的Kafka直接连接器
- Spark节点和Kafka 代理人(broker)不一定在同一地点。
- 一个Spark分区对应一个Kafka主题分区。
- 如果出于某种原因,多个主题分区位于单个Kafka节点上,则有多个Spark执行程序可能会命中该节点(不过没关系)。
- 上图只是一个简单的说明。
非常值得注意的一点是,Spark是以分布式的方式访问Kafka中的数据。Spark中的每一个任务都会从某个Kafka主题的特定分区中读取数据,该特定分区称为主题分区。主题分区理想地均匀分布在Kafka 代理人(broker)之间。
但是,为了以分布式的方式从安全的Kafka中读取数据,我们需要在Kafka(KAFKA-1696)中使用Hadoop风格的授权令牌,在写本篇博文时(2017年春季)还不支持这一功能。
我们已经考虑了各种解决这个问题的方法,但是最终决定采用从Kafka中安全读取数据的建议解决方案(至少应实现Kafka授权令牌的支持)将是Spark应用程序分发用户的keytab,以便执行程序可以访问。然后,执行程序将使用共享的用户密钥表,与Kerberos密钥分发中心(KDC)进行身份验证,并从Kafka 代理人(broker)中读取数据。YARN分布式缓存用于从客户端(即网关节点)向驱动程序和执行程序发送和共享密钥表。下图显示了当前解决方案的一览图。
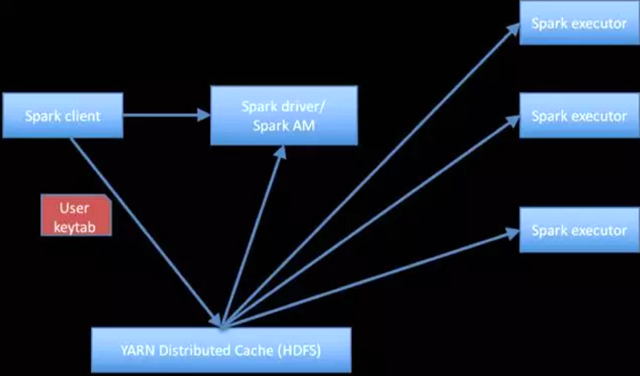
图2:当前解决方案(假设YARN集群模式)
这种方法存在以下一些常见的问题:
a. 这不能被认为是发送钥匙表的最佳安全实践
b.在具有大量Kafka主题分区的情况下,所有执行程序可能会同时尝试登录KDC,存在导致重送攻击的潜在风险(类似于DDOS攻击)。
关于问题a),Spark已经使用分布式缓存将用户的密钥表从客户端(亦称为网关)节点发送到驱动程序,并且由于缺少授权令牌,所以没有办法绕过。管理员可以选择自己在Spark外部将密钥表分发到Spark执行程序节点(即YARN节点,因为Spark在YARN上运行),并调整优化共享的示例应用程序以缓解该问题。
关于问题b),我们在Kafka主题中测试了1000多个主题分区,并且在增加分区数量后未见对KDC服务器产生不利影响。
与Apache Sentry集成
例应用程序假设没有使用任何Kafka授权。如果使用了Kafka授权的话(通过Apache Sentry),则必须确保应用程序中指定的消费者小组已经获得Sentry授权。例如,如果应用程序的消费者小组的名称是my-consumer-group,则必须同时对my-consumer-group和spark-executor-my-consumer-group授予访问权限(即您的消费者小组名称前缀为spark-executor-)。这是因为Spark驱动器使用是该应用程序指定的消费者小组,但spark执行程序在此集成中使用的是不同的消费者小组,该集成在驱动程序消费者小组的名称前指定的前缀是spark-executor-。
结论
简而言之,您可以使用Cloudera Distribution of Apache Kafka 2.1.0 版本(或更高版本)和Cloudera Distribution of Apache Spark 2.1第一次发行版(或更高版本),以安全的方式从Kafka中使用Spark内的数据——包括身份验证(使用Kerberos进行身份认证)、授权(使用Sentry进行授权)以及线上加密(使用SSL/TLS进行加密)。
本文作者:Cloudera中国
来源:51CTO