
前言
大家好!我叫阿勇~本次基于强化学习(Reinforcement Learning,RL)完成了送餐场景的智能体训练。从最初毫无行为逻辑,到最终让智能体掌握完整的配送策略,整个过程收获良多。
我把本次实践中的经历和有意思的细节整理出来分享给大家,希望大家会喜欢。
任务背景
这次的送餐任务,用的是及第平台(jidiai.cn)提供的 AI 仿真环境。在这个网格世界里,我的目标是训练出一个智能体,让它在限定时间内把订单从餐厅送到客户手上,拿到尽可能高的累计回报。
玩家训练好智能体后,可上传至平台与其它玩家在进行1V1对抗,最后由平台按玩家最后 30 盘平均奖励进行排名。
下面就着地图,先说说这个环境的基础
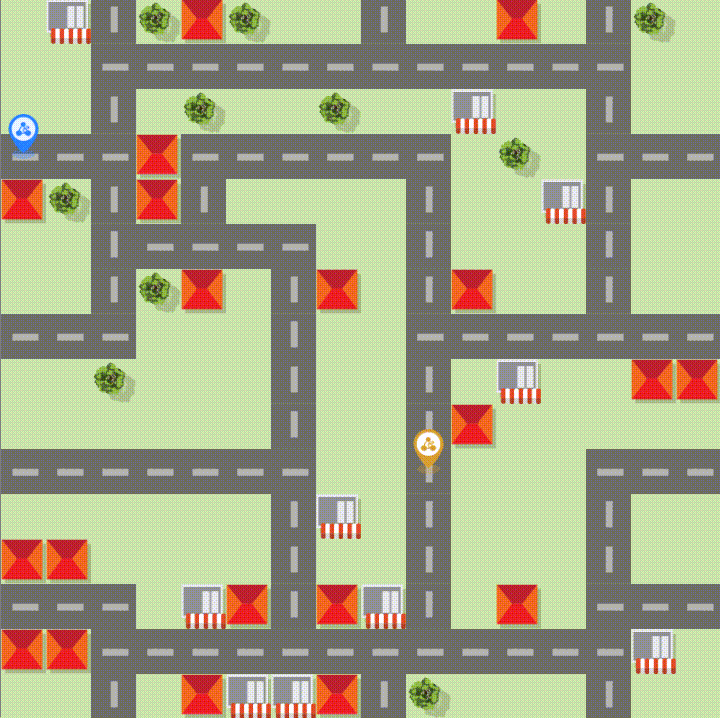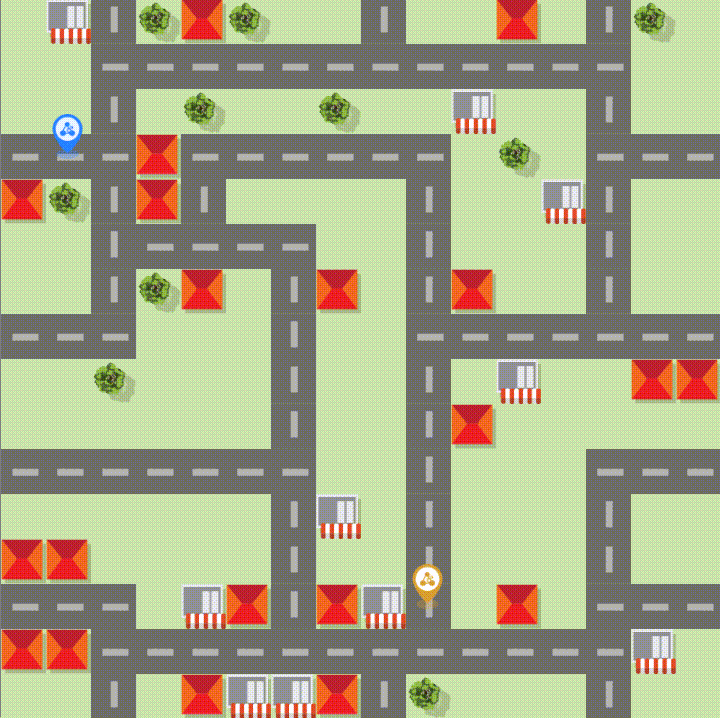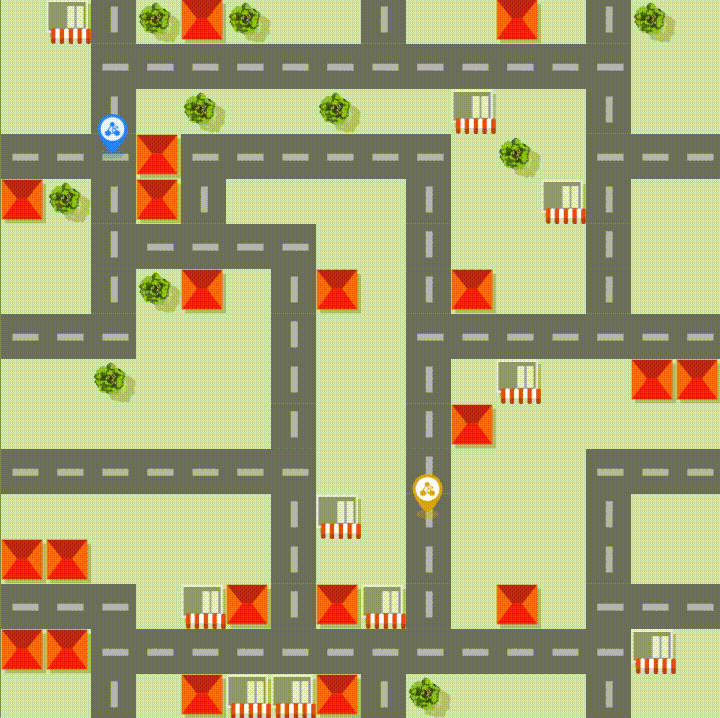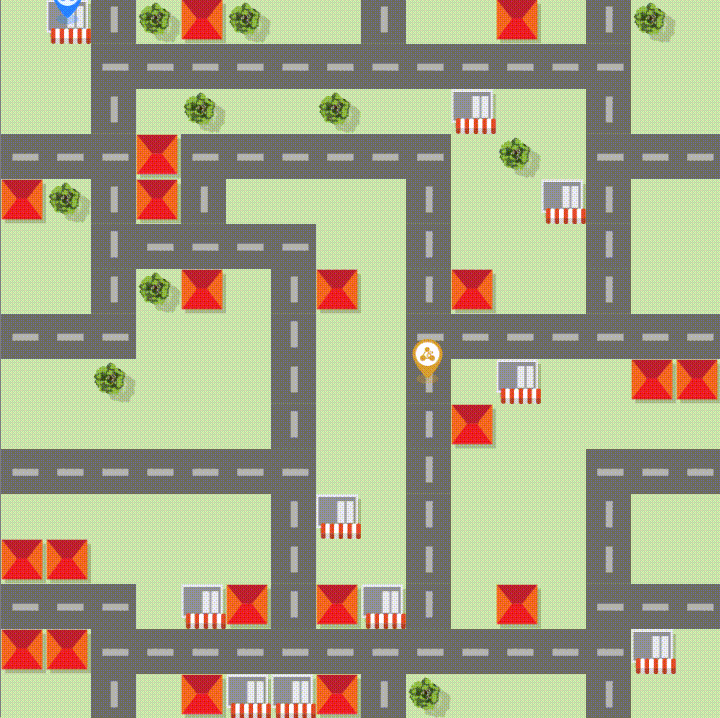
这是一个 16 × 16 的网格世界,地图中有 10 个餐厅,20 个客户。地图中有道路。除道路与餐厅、客户外,骑手不能进入。
餐厅和客户的位置在游戏开始时在道路中随机产生。骑手初始位于道路的随机位置中,每步可以移动一个网格。
每经过10个时间步,随机产生 20 个餐厅订单,餐厅的订单容量没有上限。若订单在规定截止时间后仍未被骑手接受,该订单被自动取消。
每个时间步,系统会从还未被抢的订单集中选取最多 10 个订单,供骑手进行抢单(可同时抢 0 - 10 张订单),骑手在到达餐厅后根据已抢到的订单取单。 每个骑手最多可以抢 20 个订单(尚未取餐),但身上最多只能同时携带 5 个已取餐的订单。
在餐厅取餐时,对非本店的订单进行取餐,视为无效操作,订单状态也保持不变。
智能体的动作空间有四类操作:
1、移动:只能在可行区域(道路、餐厅、客户点)内行动,可选方向是上、下、左、右,也可以选择原地不动。
2、抢单:每个时间步,都可以对系统展示的订单发布列表里的任意订单发起抢单。
3、取餐:当骑手处于餐厅位置时,可以对属于该餐厅、且已经抢到的订单执行取餐操作。
4、放餐:当骑手处于客户位置时,可以对已经取餐的订单执行放餐操作,放餐成功即完成该订单的配送。如果不在对应客户放餐,视同“丢弃订单”
整个任务的目标,是在 500 个时间步内拿到尽可能高的累计总收益,收益是奖励和惩罚的总和:
奖励:在订单规定的结束时间前把餐送到客户点,就能获得奖励,奖励的数值等于餐厅到客户点的曼哈顿距离。
惩罚:出现以下两种情况会被惩罚,惩罚值是对应订单奖励值的一半:
① 抢单后,没能在规定时间送到客户点;
② 中途主动放弃已抢到 / 已取餐的订单(也就是丢弃订单)。
另外还有个细节:如果同一个订单被两个骑手同时抢,环境会随机选一个骑手来接受这个订单。
关于捷径

这里还有个有意思的细节,就是地图里的「捷径」,按任务的基础规则,骑手只能在道路格子上走,但餐厅和客户所在的格子骑手是可以进入的,这就形成了一些可以抄近路的路径,也让路网的复杂度比单纯的道路网格更高了。
如上图中的2条蓝色移动线路,都是捷径的利用。
任务难点分析:
在跑这个任务的时候,我觉得最大的难点,就是环境里的各种「随机性」: 餐厅和客户的位置、因为捷径带来的路网变化、骑手的初始位置、订单的生成(餐厅与客户的组合及对应收益,发布时间,截止时间)、待抢订单池里展示的订单,全都是随机的。
这些随机性带来的影响很直接:智能体在训练时几乎每次收到的状态都是新的,就算执行了同一个动作,下一个环境状态也有很大差异,状态转移的复杂度比固定环境高很多。 这也倒逼智能体不能只记住某几条固定的配送路线,必须真正学会通用的配送策略。
为了对抗这些随机性,我在训练里做了不少尝试,比如在注意力机制里加了噪声因子、调了广义优势估计(GAE)里的超参数 λ(lambda)、让价值网络输出分布而不是单一的数值。
除了随机性之外,还有个难点是奖励和惩罚的延迟性。抢单、移动、取餐这些动作,都不会立刻得到奖励或惩罚,只有等订单送到客户手上才会有奖励,或者订单超时了才会触发惩罚。这意味着智能体需要学习长跨度的累积回报,建立面向长期目标的决策逻辑。
相关技术简介
受文章篇幅限制,我会对技术相关、算法细节、网络结构做适当简化,还请大家理解。
1、深度强化学习
深度强化学习的核心思路,是借助神经网络搭建智能体,让它在和环境不断交互、试错的过程中,逐步学习到最优决策策略。
因此,不需要人为给智能体预设固定规则,它会在持续交互中吃透任务逻辑,慢慢摸索出对应的执行策略,这也是我觉得强化学习最有魅力的地方。
本次项目我选用了基于 AC 架构的 PPO 算法,其策略网络依托策略梯度实现优化。简单来说,算法的优化逻辑就是:提高好的行为概率,降低坏的行为概率,以此不断迭代完善决策策略。
至于如何判断行为的好坏,这个就是优势函数的定义:行为比期望收益高,就是好的行为,反之就是坏的行为。
2、预训练表征学习
想要让智能体做出合理的配送决策,首先得让它理解整张地图的布局。为此我设计了代理任务(最短路径)开展预训练,让模型先学习地图特征,生成对应的高维特征向量(表征),这个向量浓缩了地图的结构信息。有了这份基础表征后,再开展下游送餐主任务训练,就能事半功倍。
一句话就是让智能体先「理解」再「决策」。
实际开发中,我对下游任务的算法、网络结构迭代了非常非常非常多版本,但全程都直接复用预训练得到的地图表征,大大提升了开发和训练效率。
3、图神经网络
地图本身的结构和图数据特性高度契合:骑手、餐厅、客户都可以看作图中的节点,道路则是连接节点的边,距离相关是边的属性,时间等信息作为全局特征参与计算。
我主要在地图预训练阶段使用图神经网络,具体选用的是图注意力网络。
4、Transformer-Encoder
当下主流的 Transformer-Encoder 架构,我应用在了下游送餐主任务中。智能体每一步决策,都需要综合考量不同订单之间的关联关系,而该架构天然适配这类场景,其 N × N 的注意力复杂度,刚好能满足多订单关联分析的需求。
成果展示
很遗憾的是,截止本文成文时间2026年5月及第平台仅接收智能体的提交,但不再开放玩家之间的PVP对战,因此无法直接拿到对战模式下的官方评分。下面我以本地单机运行的测试成绩作为参考。
平台排名前两名玩家的 30 局平均回报分别是 772.47,764.63。
而我的智能体在本地 100 局单机测试中,平均回报是 824.19,标准差 102.86,最小值 554.5,最大值 1069.0
虽然无法直接对比,但我做了一个粗略估计:每局生成的订单数量,比双人对战模式下两位玩家能够处理的订单总量还要多得多。这意味着即使转移到对战环境,订单资源依然非常充足,不太可能出现因为抢不到单而导致的性能骤降。当然,对战中的策略干扰仍然会存在,所以实际成绩大概率会低于单机成绩,但我判断不会断崖式下跌。
展示说明
为了让大家更直观地理解智能体的运行逻辑,下面我会结合 Pygame 的可视化界面,先说明界面里的关键元素,方便大家看懂后续的运行示例。
 骑手标识:我操控的智能体;A_0 为环境自带的静止骑手,可忽略
骑手标识:我操控的智能体;A_0 为环境自带的静止骑手,可忽略 餐厅标识:全地图随机生成 10 间餐厅
餐厅标识:全地图随机生成 10 间餐厅 客户标识:全地图随机生成 20 个客户
客户标识:全地图随机生成 20 个客户 障碍标识:骑手不能进入的区域
障碍标识:骑手不能进入的区域 取餐路线标识:标记从骑手当前位置到餐厅的路径,连续取餐会标注顺序
取餐路线标识:标记从骑手当前位置到餐厅的路径,连续取餐会标注顺序 配送线路标识:标记从餐厅到客户的路径,连续配送会标注顺序
配送线路标识:标记从餐厅到客户的路径,连续配送会标注顺序
订单列表界面说明

智能体行为总结
结合本地测试的运行日志和 Pygame 可视化界面,我观察到训练完成的智能体,在具体的订单处理和路径规划上,展现出了多种实用的策略:
1、订单聚合决策
○ 同源同宿订单聚合:骑手会在不同时刻进行凑单,将“餐厅相同、客户相同”的多张订单聚合起来,再一并取餐、配送。这是效率最高的策略。
○ 区域邻近订单聚合:与上同理,骑手进行位置邻近的订单进行凑单,包括 “餐厅相同、客户邻近”“餐厅邻近、客户相同”“餐厅和客户都邻近” 这几类情况,这样就能实现连续取餐或者连续配送,减少来回绕路的时间。
2、动态路径规划
骑手的目标地不是固定不变的,会根据环境变化随时调整:
○ 比如离开餐厅不远,又抢到了该餐厅的新订单,骑手会主动回头取餐,而不是硬着头皮继续往前走;
○ 也不会死板地遵守 “取餐→清空所有配送库存→再取餐” 的模式,而是会根据实际情况灵活调整,比如 “取餐→先送部分订单→再去取餐→最后清空配送库存”,而且配送的顺序也不一定和取餐的顺序一致,完全以效率为优先。
3、库存感知与利用
智能体会同时感知两类库存的状态,做出最优选择:
○ 对「提单库存」(已抢单但未取餐的订单):在满足取餐的情况下,不会把库存抢满,而是会保留一部分库存,应对后续出现的高收益订单;
○ 对「配送库存」(已取餐待配送的订单):会尽量提高库存利用率,规划「取餐→配送」的高效路线,减少空载行驶,最大化单位步数的收益。
4、时间感知与优先级判断
骑手对订单的剩余时间、本局的剩余时间都有清晰的感知:
○ 会优先配送临期订单,避免超时产生惩罚;
○ 开局阶段不会做复杂的长距离规划,而是就近取餐开始配送,不浪费开局的时间步。
地图级别的决策偏好

在地图层面,智能体形成了两个很明显的行为倾向:
1、偏爱长距离配送策略 按任务规则,奖励值等于订单的曼哈顿距离,理论上长短距离订单的收益效率是一样的。但因为地图里有障碍(白色单元格),很多短距离订单的实际移动路径会比曼哈顿距离长得多 —— 比如左图订单收益只有 3 (绿色虚线),实际却要走 15 步(绿色实线)才能送到,收益效率极低。而长距离订单能避开这些弯弯绕绕的路线,整体效率更高,因此智能体更倾向于选择这类订单。
2、优先选择左上角片区的订单 观察地图能发现,左上角片区的道路之间只有一格障碍,随机生成的餐厅和客户很容易形成捷径,能大幅缩短配送路程;而其他片区的道路之间,障碍至少有两到三格,很难形成这样的抄近路机会。因此智能体也会更偏爱以左上角片区为核心的配送路线。
最后也说明一下:经过训练的智能体确实掌握了不少高效的配送策略,但它并不是完美的,偶尔还是会出现判断失误、效率不高的情况,请理解。
示例









































网络与训练设计
开发环境:Python、PyTorch
训练平台:Kaggle(仅使用 CPU)
受限于个人硬件资源,本次训练未使用 GPU 加速。考虑到强化学习探索过程存在随机性,我采用了稳健的迭代训练策略:每日训练 5 个模型版本分支,筛选出当日最优结果后,次日基于该最优版本继续训练 5 个版本分支,逐步迭代优化模型性能。
预训练阶段

训练过程:在地图中随机选取两个位置,作为出发地、目的地。然后算法目的是寻求两地之间的最近可行路径。
为简单化说明网络设计,以右上角6 * 6作为地图说明。


上左图中A点作为出发点,代表智能体Agent,目的地是 E
智能体Agent可以选择往“上、下、左、右”向可行单元格移动
上右图是我设定的地图节点类型:餐厅及相邻单元格、客户及相邻单元格、出发地、目的地,三叉路口,十字路口,拐弯处。此图我为了方便展示,节点作了很大程度的简化
图神经网络设计

上游预训练任务收敛后,取最后一层图神经网络所有节点的输出结果。
这些半成品,就是我要的节点高维表征。
训练相关
使用的是常规强化学习PPO算法,每个时间步预测下一移动方向
奖励:到达终点 reward = 1
惩罚:每个时间步 reward = -0.001
这个设计的核心目的,是引导智能体以尽可能少的步数从出发地到达目的地,也就是学会最短路径规划。
训练初期我使用过不少奖励塑形,例如虹吸效应,即越靠近目的地,辅助奖励越大;走回头路给予惩罚;同时也留意了避免奖励挟持的问题等等。但后来发现不使用辅助奖励也能训练起来,可能地图还算小吧。
渐进式训练策略:
为了让智能体平稳适应路径规划任务,我采用了由易到难的渐进训练方式,逐步增加任务难度:
初期:固定 1 个出发地,目的地从固定的几个点中随机选择,让智能体先熟悉任务目标;
中期:扩展为多个固定的出发地和目的地,进行随机组合训练,让智能体适应更多场景;
后期:出发地和目的地都改为全地图随机生成,让智能体掌握通用的路径规划能力。
预训练成果

上图展示了地图数据中各节点的原始特征,并通过TSNE 降维进行可视化。
这种原始特征仅能反映节点之间的L2 距离,但无法准确体现其实际路径关系。
观察点:绿框[3,4],与黑框[3,2] 与[5,4] 在L2 距离中相等,与实际可行路径距离不符。 注:白色单元格不可通行

原始特征经过表征学习后,已经能反映出真实的路径关系:绿框距离[5,4] 最近,[3,9] 次之,[3,2] 最远

在另外一次随机地图中,存在[3,3] 的可通行路径,经过表征学习后:
绿框与[5,4],[3,2] 距离基本相同。可见高质量的表征,能根据实际地图情况准确反映路径信息。
下游主任务阶段
基于 Transformer Encoder 架构

训练相关
1、 奖励与惩罚设计
主任务的奖励和惩罚完全按照任务原规则执行,没有额外添加任何奖励塑形,直接以任务的收益规则作为优化目标。
2、 动作空间的改造与简化
主任务的原始动作空间维度:移动(5) × 抢单(2^10) × 取餐(2^20) × 放餐(2^5),直接训练难度很大。为了让智能体能聚焦在核心的订单规划决策上,我对动作空间做了关键改造:
○ 不再让智能体直接输出 “上、下、左、右、不动”5 个移动动作,改为让智能体输出目标地(可选目标为地图上的 20 个餐厅位置 + 5 个客户位置);
这里解释一下为什么是 5 个客户位置而不是 20 个,因为骑手最多能携带 5 张订单在身上,也就是最多 5 个不同的客户具备即时配送需求。前往其它客户点位没有实际业务意义,这里也是用到先验知识作分析,进一步压缩不必要的决策空间。
○ 目标确定后,再通过 BFS(广度优先搜索)算法,分析骑手当前位置到目标地的最短路径,就能得到当前时间的移动决策。
这样改造的核心目的,是把 “寻径” 这个已经在预训练阶段学会的能力,从主任务的学习目标中剥离出来,让智能体把全部学习精力放在订单抢取、取餐配送的规划决策上,不用再从零学习路径移动。
3、渐进式训练策略
为了让智能体平稳适应完整的配送决策流程,我采用了分阶段放开动作空间的渐进式训练方式,逐步提升任务难度:
阶段一:基础规则学习(动作空间:目标地 × 抢单)
取餐和放餐操作由手写脚本实现:当骑手到达餐厅时,会按订单序列自动对已抢单的订单取餐;到达客户时自动放餐。
这个阶段的核心目标,是让智能体先学会任务的基础规则:抢单→去餐厅取餐→去客户放餐,理解 “完成订单获得收益、超时会有惩罚” 的底层逻辑,初步学会基础的配送策略。
阶段二:取餐决策放开(动作空间:目标地 × 抢单 × 取餐)
放餐操作仍由手写脚本实现,但放开了取餐动作的决策权:智能体到达餐厅时,不再自动对所有已抢单的订单取餐。现在需要学习分辨属于该餐厅的订单,并进行取餐。还要根据环境因素,自行决定在同一餐厅优先取餐哪些订单。
这个阶段,智能体需要开始根据订单的时间、收益等信息,自主判断取餐优先级,配送策略会更灵活,也能获得更高的收益回报。
阶段三:全动作放开(动作空间:目标地 × 抢单 × 取餐 × 放餐)
完全放开所有动作的决策权,智能体可以自主决定在任意位置(包括非客户位置)执行放餐操作。
理论上这个阶段智能体有了完整的决策权限,但实际测试中,收益回报的提升非常有限 —— 因为在非客户位置放餐是非法操作,会触发惩罚,只有提前清空库存这一个潜在好处,对整体配送效率的提升几乎没有帮助。
强化学习算法相关
一、网络结构优化:PPO + Transformer + 值分布 + 记忆单元
本次任务核心使用PPO算法进行训练。
考虑到送餐环境具备极强的随机性,我参考了 DSAC(Distributional Soft Actor-Critic) 算法的价值网络设计思路做了优化:让价值网络不再输出单一的价值数值,而是输出一个高斯分布,以此提升智能体对随机环境的适应能力。
在 Transformer 架构中,我额外加入了一个记忆单元,参与多头注意力机制(MHA)的计算,用于传递智能体的历史决策记忆。
我个人认为,强化学习天然适配 RNN 类的记忆结构 —— 因为强化学习的推理过程本就是按单步时序依次决策的,RNN 推理速度较慢的特点,在强化学习场景中并不会造成负面影响。
为此我做了消融实验:将记忆单元替换为高斯随机分布噪声。实验结果显示,智能体的核心能力没有大幅下降,仅策略稳定性略微变差。 我分析原因是:本任务中环境的核心状态(已抢订单库存、已取餐库存、餐厅 / 客户位置)都相对稳定;只有抢单列表会实时变化,但当提单库存已满时(或者接近满时),智能体并不会持续抢单,时序状态的变化对决策影响有限。
即便如此,我依旧认为记忆单元是更高效优雅的设计,比直接拼接上一时间步的状态特征要合理得多。
结合以上优化,我将自己魔改后的 PPO 算法命名为DR-PPO。
二、策略更新优化:自定义重要性采样(IS)
标准 PPO 在策略网络损失计算中,会通过重要性采样将样本损失权重限制在采样策略的 ±20% 以内。
但我在训练中考虑一个假设:训练初期策略并不稳定,智能体采样优质动作时,若分配给该动作的概率极低(如 p=0.05),按照标准±20%更新后,权重上限仅为 0.06,很容易丢失优质动作样本。
针对这个问题,我对重要性采样做了改造:将权重系数拆分为固定部分(10%)和浮动部分(10%)。 以初始概率 0.05 为例,更新后权重上限为 0.1 + 0.05×1.1 = 0.155,能有效避免初期遗漏优质动作。 随着训练逐步稳定,固定部分的系数会衰减至 0%,浮动部分逐步提升,最终恢复为标准的 ±20% 更新范围。
删除于 2026-6-21,对IS理解错误
三、训练策略优化:适配 Kaggle 训练环境
我的训练基于 Kaggle 平台,仅使用 CPU 进行训练,内存也有限。因此在一个训练的BatchSize里,无法直接将完整 500 步的对局样本全部纳入损失计算,这种方式也不够简洁高效,而且训练时间也会变漫长。
因此我做了两点适配:
1、时间信息归一化:由于我可以为每局设置时长,便将这个时长归一化映射到 0~1 区间(对应 0~500 步)作为全局变量之一,让智能体能感知当前对局的设定游戏时长;
2、滑动时间窗口采样:训练初期,单局运行步数控制在 100~300 步,后期提升至 200~400 步。训练时,从每局中随机截取连续 200 步的样本进行学习。
通过这种方式,不需要在训练时进行 500 步的训练,也能较好地适应 500 步的完整对局。
四、尝试过的各种技巧
1、热启动:我先写一个简单的规则脚本,使智能体在训练初期,能直接获得由取餐到完成配送的训练样本,加快前期学习速度。
2、使用AdaLN处理全局信息:AdaLN是自适应层归一化(Adaptive Layer Normalization)。我把全局变量分别映射成斜率与截距,从而改写LayerNorm的仿射过程。为了稳定,要把斜率与截距初始化均值分别是1与0的高斯分布。
3、奖励与惩罚:试过初期只有奖励,而惩罚系数(由0到1)随训练增长;也试过把“超时扣罚”改成“抢单时先预扣一部分惩罚,等配送成功后再把预扣的部分返还(并正常发放奖励)”,结果智能体变得特别胆小,不敢轻易抢单,反而不利于探索。
4、模仿学习:在反复设计网络时,需要智能体从头开始训练时,会从旧有智能体学习知识。但不能过度模仿,避免失去探索能力。
5、MoE(混合专家模式):参考了DeepSeek大模型里的前馈神经网络(FFN)设计。我使用的是 1 + (1/3) 专家设计,1 个共享专家加上 3 选 1 个候选专家,专家维度是原维度的 3 / 4。我感觉需要训练的时间要更多,因为网络的宽度在训练时,比普通FFN,多了 3 个候选专家。
6、价值网络双结果输出:价值网络输出,通常是智能体预测回报的期望。而这个项目回报明显是由两部分构成,奖励与惩罚。因此尝试价值网络参数共享,分别输出奖励价值以及惩罚价值。模型同样能训练起来。
7、动态记忆型智能体:由于这个任务的「可抢单的订单列表」,是随机展示的,对于智能体决策并不友善。如果人类面对这种随机展示的信息,我第一反应是「做笔记」。因此我为智能体的网络添加「 N 长笔记区」功能,让其自行对把随机展示的订单挑选写入「笔记区」,以便后续决策参考,除写入操作外,还支持自主删除操作。
我觉得是挺有意思的设计,但当时我还没重视动作空间过大的问题,导致训练困难。现在回想我同样会进行渐进式训练,而且这种网络设计更具可解释性,通过分析智能体「笔记区」去解读他的行为。
仿生,仍然是人工智能发展的坚实工具。
有很多尝试,我都没法具体说明效果如何,或者性能提升多少。我个人时间与算力有限,最主要是技术水平有限,无法做更多消融测试。但至少这些尝试模型都是可以训练起来,差别在于性能上限与收敛速度。
每次思考,每次尝试,每次网络的设计都能带给我兴奋与期待,这个过程很令人享受。同时我也犯了很多的错,从错误中亦能吸取很多宝贵的经验教训。这个曲折的过程,本身就像是强化学习,我在探索试错中成长。
训练心得 TIP
这里我分享一条本次项目实战中非常关键的训练心得,也是我整套渐进式训练方案的核心底层逻辑。
举个很通俗的例子:如果做决策时只有唯一选项,那将完全不需要权衡、没有决策压力;当选项增加为两个,就需要开始权衡利弊、判断优劣;当同时存在多项决策维度,且每个维度都有大量可选动作,整体就会变成极度复杂的联合决策问题。
从强化学习的角度来看,多维度联合决策是联合概率的过程。随着动作维度增多、可选动作变多,概率的乘积会持续变小,不确定性大幅升高(熵变大),这也直接导致智能体的学习难度呈指数级上升。
所以在复杂交互任务中,尽可能降低决策不确定性,是提升训练成功率、加快收敛的关键。基于这个核心思路,我在本次下游主任务训练中用了三套实用技巧:
第一,渐进式放开动作空间。
我没有直接让模型学习全部动作空间,而是由少到多、逐步增加单步决策的动作概率连乘项。让智能体先掌握简单决策逻辑,再逐步适配复杂的多维度联合决策,大幅降低初期的训练难度。
第二,引入先验知识做 Action_Mask。
在计算损失中的联合概率时(非采样过程),我通过掩码机制,把当前状态下可执行但无效的动作概率直接置为 1。概率为 1 意味着该项不影响整体联合概率结果,等价于屏蔽了无效动作的干扰。
我用到的先验规则非常贴合任务逻辑:骑手不在餐厅时,屏蔽取餐动作;提单库存为空时,屏蔽取餐动作;配送库存为空时,屏蔽放餐动作;提单库存已满时,屏蔽抢单动作;配送库存已满时,屏蔽取餐动作等等。通过这种方式,极大精简了有效决策空间,减少无效噪声。
第三,分阶段冻结网络参数 + Action_Mask。
在逐次放开新动作的训练过程中,我不会一次性更新全部网络参数。初期会冻结整个主干网络,只单独训练新增动作的输出头;待智能体完全掌握新动作的决策逻辑后,再解冻全网参数进行联合微调,这些都是预训练到下游任务常见手段。 同时在训练新动作头时,我会通过 Action_Mask 将旧有成熟动作的概率置为 1,让损失函数在计算联合概率时,只专注学习新增动作的优化逻辑,避免新旧动作互相干扰。
总的来说,在结构可控、可以通过先验规则约束的交互环境中,结合渐进训练、概率掩码、参数冻结这套组合方法,能非常高效地降低学习难度、提升训练稳定性,是个人落地强化学习复杂任务时性价比极高的实操技巧。
总结
看着自己设计的送餐智能体,从零基础不断试错、迭代成长,性能一步步稳步提升,是整个项目过程中最有成就感的事情。
我在坚持学习强化学习相关知识,目前也开始接触各类带约束条件的复杂交互环境。相比大语言模型,强化学习的优化目标更加直接、聚焦,优化函数始终围绕任务核心目标展开,因此所需算力成本更低,让个人与普通企业能落地实操、进行项目迭代。
回顾本次项目的网络设计与训练落地: 整体网络架构由两部分组成,预训练阶段采用 4 层 32 维的图神经网络作为骨干网络,现在复盘来看,网络层数还有精简优化的空间;下游送餐主任务,则采用 2 层 64 维的 Transformer 架构搭建骨干网络。能看出模型参数量很小。
本次全程依托 Kaggle 平台,使用 CPU 进行训练。仅需 24 小时的持续训练,智能体就能基本掌握任务规则。我在 30 天的持续迭代训练中,筛选出效果最优的策略模型作为本次项目的最终展示成果。
可以的话,建议大家尽量用代码生成工具进行代码编写。人可以天马行空,充满激情与创意去构思你的算法,设计训练过程等等,而代码生成工具则可以避免很多人为编码出错。深度学习与强化学习,很多时编码出错不在于语法,而在于逻辑。这会出现代码跑通,但算法不收敛的情况,耗费的算力成本、时间成本都很昂贵。代码生成工具真的是很好的生产力工具。
前提是你要完全弄懂算法的方方面面,不含糊,才能驾驭代码生成工具。而不是被他牵着走。
我认为,优化问题是工程实践中最常见、最具经济价值的问题,这与强化学习“最大化回报”的目标高度一致。只要问题的结构满足马尔可夫决策过程(MDP),强化学习就是一个值得优先考虑的方案。
希望大家喜欢我这次的分享,关注并加入强化学习当中。
很想写出真情实感,奈何文笔生硬,上述文案经LLM润色修正,特此说明。
2026年6月上旬 阿勇

