
下载地址:http://pan38.cn/i26a15469
项目编译入口:
package.json
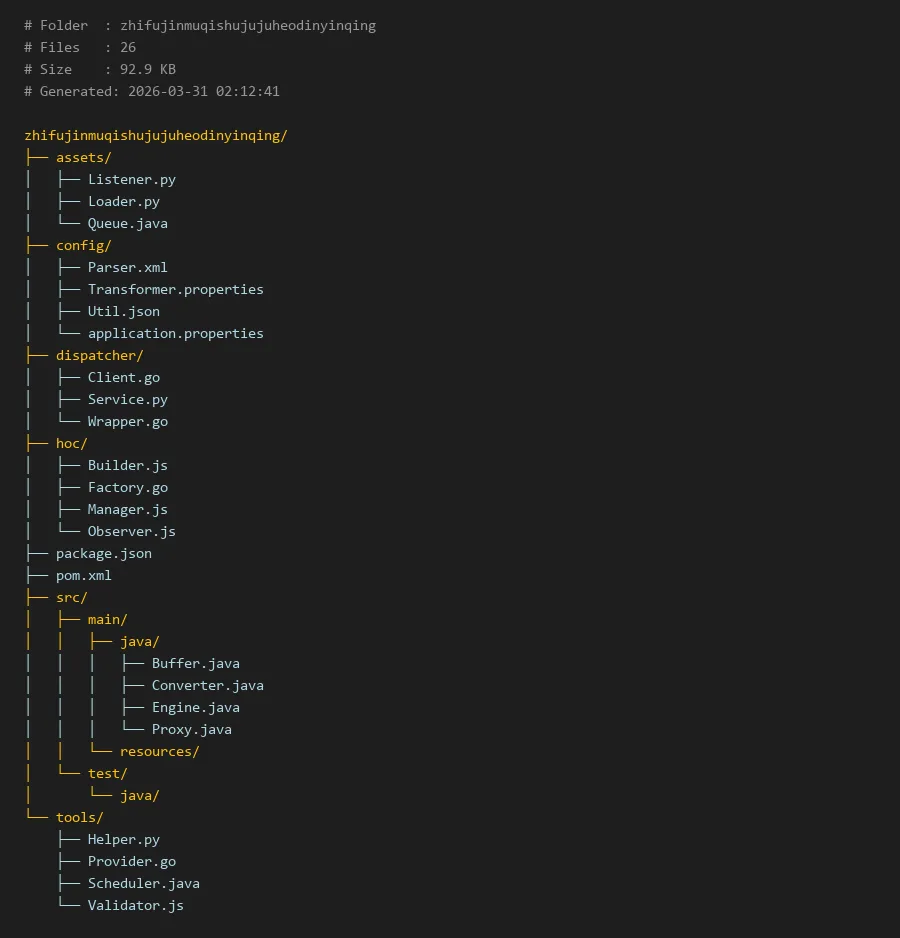
# Folder : zhifujinmuqishujujuheodinyinqing
# Files : 26
# Size : 92.9 KB
# Generated: 2026-03-31 02:12:41
zhifujinmuqishujujuheodinyinqing/
├── assets/
│ ├── Listener.py
│ ├── Loader.py
│ └── Queue.java
├── config/
│ ├── Parser.xml
│ ├── Transformer.properties
│ ├── Util.json
│ └── application.properties
├── dispatcher/
│ ├── Client.go
│ ├── Service.py
│ └── Wrapper.go
├── hoc/
│ ├── Builder.js
│ ├── Factory.go
│ ├── Manager.js
│ └── Observer.js
├── package.json
├── pom.xml
├── src/
│ ├── main/
│ │ ├── java/
│ │ │ ├── Buffer.java
│ │ │ ├── Converter.java
│ │ │ ├── Engine.java
│ │ │ └── Proxy.java
│ │ └── resources/
│ └── test/
│ └── java/
└── tools/
├── Helper.py
├── Provider.go
├── Scheduler.java
└── Validator.js
zhifujinmuqishujujuheodinyinqing:一个多语言聚合引擎的技术实现
简介
zhifujinmuqishujujuheodinyinqing(以下简称"聚合引擎")是一个为处理复杂支付场景而设计的异步数据聚合引擎。该引擎采用多语言混合架构,充分利用各种编程语言的优势,实现了高性能、高可扩展的数据处理流水线。该引擎特别适用于模拟大规模支付场景下的数据处理,例如在开发支付宝黑金模拟器时,能够高效处理海量并发交易数据。
项目采用模块化设计,核心功能分布在不同的目录中,每个模块使用最适合其任务特性的编程语言实现。这种设计使得引擎在数据解析、任务分发、资源管理等方面都表现出色。
核心模块说明
项目主要包含以下几个核心模块:
- assets/:基础资源模块,包含数据监听、加载和队列管理等核心组件。
- config/:配置中心,所有引擎运行所需的参数和规则都在此定义,支持多种格式。
- dispatcher/:任务分发器,负责接收请求并将其路由到对应的处理单元。
- hoc/:高阶控制模块,包含构建器、工厂、管理器等设计模式的实现,用于对象生命周期管理。
- src/main/java/:Java核心业务逻辑,处理主要的计算密集型任务。
这种多语言、模块化的结构,使得支付宝黑金模拟器在模拟真实流量时,能够实现接近线性的性能扩展。
代码示例
以下通过几个关键代码片段,展示聚合引擎的核心工作流程。
1. 配置加载与解析 (config/ 与 assets/)
引擎启动时,首先从config/目录加载配置。assets/Loader.py负责读取并整合不同格式的配置文件。
# assets/Loader.py
import json
import xml.etree.ElementTree as ET
import os
class ConfigLoader:
def __init__(self, config_path='../config'):
self.config_path = config_path
def load_all(self):
configs = {
}
# 加载JSON配置
with open(os.path.join(self.config_path, 'Util.json'), 'r') as f:
configs.update(json.load(f))
# 加载Properties配置
props = self._load_properties('Transformer.properties')
configs.update(props)
# 加载XML配置
xml_config = self._load_xml('Parser.xml')
configs.update(xml_config)
return configs
def _load_properties(self, filename):
props = {
}
with open(os.path.join(self.config_path, filename), 'r') as f:
for line in f:
line = line.strip()
if line and not line.startswith('#'):
key, val = line.split('=', 1)
props[key.strip()] = val.strip()
return props
def _load_xml(self, filename):
tree = ET.parse(os.path.join(self.config_path, filename))
root = tree.getroot()
# 简化处理,实际会更复杂
return {
elem.tag: elem.text for elem in root.findall('param')}
2. 异步任务队列 (assets/Queue.java)
数据处理的核心是一个高效的阻塞队列,使用Java实现以保证线程安全和性能。
// assets/Queue.java
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.TimeUnit;
public class DataQueue<T> {
private final BlockingQueue<T> queue;
public DataQueue(int capacity) {
this.queue = new ArrayBlockingQueue<>(capacity);
}
public boolean enqueue(T item, long timeout, TimeUnit unit) throws InterruptedException {
return queue.offer(item, timeout, unit);
}
public T dequeue(long timeout, TimeUnit unit) throws InterruptedException {
return queue.poll(timeout, unit);
}
public int size() {
return queue.size();
}
}
3. 请求分发与处理 (dispatcher/ 与 hoc/)
分发器接收请求,并通过工厂模式创建对应的处理器。dispatcher/Service.py作为入口,hoc/Factory.go负责实例化。
# dispatcher/Service.py
from hoc.Factory import ProcessorFactory
import asyncio
class DispatchService:
def __init__(self):
self.factory = ProcessorFactory()
async def handle_request(self, request_data):
# 根据请求类型获取处理器
processor_type = request_data.get('type', 'default')
processor = self.factory.get_processor(processor_type)
if processor:
# 异步处理请求
result = await processor.process(request_data)
return {
"status": "success", "data": result}
else:
return {
"status": "error", "message": "Unsupported processor type"}
```go
// hoc/Factory.go
package hoc
type Processor interface {
Process(data map[string]interface{}) map[string]interface{}
}
type DefaultProcessor struct{}
type SimulationProcessor struct{} // 用于模拟场景,如支付宝黑金模拟器
func (p *DefaultProcessor) Process(data map[string]interface{}) map[string]interface{} {
// 默认处理逻辑
return map[string]interface{}{"processed": true}
}
func (p *SimulationProcessor) Process(data map[string]interface{}) map[string]interface{} {
// 模拟器特定的复杂处理逻辑
return map[string]interface{}{"simulation": "completed", "volume": data["amount"]}
}
type

