上一篇主要介绍了 Fluss 的核心概念和定位,这一篇将深入探讨 Fluss 的内部原理,剖析 Fluss 的集群核心架构。下一篇将扩展到湖仓集成部分。
01Fluss 集群核心架构(不含湖仓)
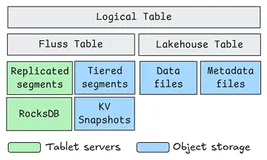
Fluss 包含三个核心组件:
- Tablet 服务器(即TabletServer):构成实时存储组件。
- 协调器服务器(即CoordinatorServer):类似于 Kafka 中的 KRaft,不仅存储通用元数据,还充当协调层。
- Fluss 客户端:向 Flink 提供读写 API,并负责部分统一工作,以融合历史数据和实时数据。客户端既与 Fluss CoordinatorServer、Fluss TabletServer交互,也直接从对象存储读取数据。

02日志表
Fluss 日志表分为两个逻辑层级,用于定义数据的分片方式:
1. 顶层:表按分区列划分为多个分区,这是数据的逻辑分组,类似于 Paimon(及其他表格式)中的分区。分区列可以是日期列、国家列等。
2. 分区内:每个分区内的数据进一步细分为桶(buckets),桶是读写并行度的单位;每个桶都是独立的仅追加流,对应于一个 Flink source split(后续将讨论)。这与 Paimon 在分区内的数据划分方式一致,使得两者的逻辑模型高度对齐。

每个桶在物理上由 Fluss 集群存储为多副本备份的 log tablet。log tablet 相当于 Kafka 主题分区,其代码借鉴了 Kafka 及其复制协议。
当 Fluss 客户端向日志表追加数据时,必须为每个记录确定正确的表分区和分桶。表分区的选择基于分区列,而桶的选择则采用与 Kafka 生产者类似的方式,如轮询(round-robin)、粘性(sticky)或基于分桶键的哈希(hash)。

Log tablet 复制
每个log tablet 是多副本复制的仅追加记录日志,借鉴了 Kafka 复制协议构建,相当于 Kafka 主题分区。因此,默认情况下,每个log tablet 有三个副本,包括一个领导者(leader)和两个追随者(follower)。

它包含HW(high watermark)和 ISR(In-Sync Replica)的概念。不过,近期为增强协议抵御同步相关故障(simultaneous correlated failures)而进行的加固工作[1] 并未被包含在内。
列式存储
Fluss 以列存格式存储日志表数据,以支持将列投影下推到文件系统层,并可利用 Arrow 格式的优势。Fluss 客户端将数据积攒成批,然后使用 Arrow IPC 将每批数据序列化为 Arrow vectors。Log tablet 副本将这些 Arrow IPC record batches直接追加到磁盘上的log segement files。这些 Arrow 数据是自描述的,其元数据允允许文件reader在读取磁盘数据时(当获取请求中包含投影时)仅读取所需的列。
投影下推指客户端在获取请求中包含列投影,该投影被一路下推到文件存储层,在从磁盘读取数据时剪枝不需要的列。这避免了网络 IO,但如果投影的列在文件中分布较为分散,则可能会增加存储 IO 开销。
将日志表数据存储为一批批 Arrow IPC 格式数据,与使用单个 Parquet 文件作为segment file有很大不同。一个包含 100 批Arrow IPC 记录的segment file,每个批次都是独立的列式块;因此,读取文件中的单个列需要访问每个批次的元数据和缓冲区。而 Parquet 文件将列在整个文件中连续排列,支持通过投影下推直接批量读取列。与 Parquet 相比,Arrow IPC 的方式增加了一些文件 IO 开销,使得对已分层到远程的日志数据的列剪枝变得不切实际且开销大。但在客户端将批次序列化为 Parquet 文件也不是理想选择,因此 Arrow IPC 文件的方式是一种折中方案。未来可能通过compaction将segment file重写为 Parquet 格式,以实现对已分层到远程的日志数据更优的列式访问。
在消费侧,Fluss 客户端将 Arrow vectors转换回行数据。这种列式存储对应用代码完全透明,应用代码仍基于行进行处理。
带变更类型的日志记录
每个日志记录都有一个变更类型,可被 Flink 和 Paimon 在流作业中使用:
- 日志表:+A(追加,Append)
- 变更日志:+I(插入,Insert)、+U(更新后,Update After)、-U(更新前,Update Before)、-D(删除,Delete)对于日志表,Fluss 客户端为每个记录分配 +A 变更类型。其余变更类型用于主键表的变更日志,将在 “主键表” 部分详细说明。Log tablet 分层Fluss 有两种分层类型:1. 内部分层(类似于传统分层存储):本节将介绍。2. 湖仓分层:将在下一部分 “Fluss 湖仓架构” 中介绍。TabletServer将log tablet segment files分层到远端对象存储,这与 Kafka 的总体方法一致。不同之处在于,当 Fluss 客户端从已分层的偏移量获取数据时,log tablet 仅返回一组log segments的元数据,以便 Fluss 客户端自行下载这些 segments。这在追赶读取(catch-up reads)时减轻了 Fluss 服务器的负载。

Fluss 决定将部分逻辑放在客户端,以融合 TabletServer 磁盘上的本地数据和对象存储上的内部分层数据。这与 Kafka API 不同 —— Kafka 不支持客户端直接下载远端segments,而是由 Kafka 代理(Broker)承担下载负担。
每个 TabletServer都包含一个RemoteLogManager组件,负责通过log tiering任务将segments分层到远程存储。需注意的是,RemoteLogManager仅能为 “leader副本位于本服务器” 的log tablet 触发分层任务。单个分层任务的执行步骤如下:1. 任务范围界定:针对单个log tablet,识别需上传的本地log segment files,以及需根据 TTL 过期删除的远程segment files;2. 上传segment files:将目标segment files上传到对象存储;3. 提交分层结果:
- 生成包含 “当前所有远程segments” 的新清单文件(Manifest File);
- 将清单文件写入对象存储;
- 向CoordinatorServer发送CommitRemoteLogManifestRequest请求,其中包含远程存储中清单文件的路径(CoordinatorServer自身不存储清单文件);
- 4. 清理过期文件:提交成功后,删除对象存储中已过期的segment files;
5. 异步通知:CoordinatorServer通过NotifyRemoteLogOffsetsRequest通知log tablet副本,以便副本知晓:
- 已分层的偏移量范围(以便副本判断何时返回分层元数据、何时读取本地磁盘);
- 可删除的本地segments列表。
正如我之前提到的,由于客户端需要下载分层存储的 segment file,列式存储的网络 IO 优势仅适用于 Fluss TabletServer上的 “热数据”。即使客户端执行全表扫描时仅需读取某一列,它仍然必须下载完整的 segemnt file。除非改用不同于 Arrow IPC(每个 segment file 包含 N 个记录批次)的列式存储格式,否则无法绕过这一限制。
Flink Source API 与日志表作为数据源
要理解 Flink 如何从 Fluss 读取数据,需先了解 Flink Datastream Source API 的核心概念:
- 分片(Splits):Flink 将读取工作分解为 “分片”,每个分片是独立的输入块(如一个文件、一个主题分区);
- 分片枚举(Split Enumeration):分片枚举器(Split Enumerator)在 JobManager 上运行,负责发现source inputs、生成对应分片,并将分片分配给reader任务;
- 读取器(Readers):每个 TaskManager 运行一个source reader,负责读取分配给它的分片数据,并将记录发送到下游任务。
这一设计清晰地将 “发现与协调”(enumerator)和 “数据读取”(readers)分离,同时通过 “小分片” 和 “可恢复” 特性保证容错性。
当 Flink 将 Fluss 作为数据源时:
1. Fluss 的 Split Enumerator 在 JobManager 上运行,负责发现并分配分片(分片描述了所对应的 Fluss 桶信息);
2. 每个 TaskManager 上的Reader通过split reader从分配的分片中获取数据,并发送到下游。

通过这种方式,日志表数据源可并行读取表的所有桶,将记录发送到 DAG 中的下一个算子。
日志表与 Kafka Topic的主要差异
尽管log tablet 借鉴了 Kafka 复制协议构建,但两者存在以下显著差异:
- Fluss 使用两级层级:
- 通过分区列进行表分区。
- 每个分区内有多个桶。
- Fluss强制表格Schema,支持基本数据类型(structs, arrays, maps 的支持已在路线图中)。
- Fluss采用列式存储(Arrow IPC),支持投影下推。
- Fluss采用分层存储,客户端自行下载远端segments。
- Fluss没有类似于Kafka的消费者组(Consumer Group)协议,而是由 Flink 分配分片实现并行消费。
03主键表
主键表同样采用 “分区 + 分桶” 的两级逻辑分层,客户端写入数据时的分区和分桶选择逻辑与日志表一致。但作为 “可变表”,主键表的 API 与日志表不同:
- 写入:通过 PutKV API 实现对表的更新插入(Upserts)和删除(Deletes);
- 读取:支持对表的查找(Lookups)、前缀查找(Prefix Lookups),以及变更日志扫描(可能涉及 KV 快照文件与变更日志的混合读取,后续将详细说明)。
主键表的每个桶由 “KV Tablet” 提供支持,KV Tablet 会将变更发送到子 log tablet。KV Tablet 的状态由两部分组成:
1. RocksDB 表:用于存储KV数据;
2. Log Tablet:用于存储变更日志,同时作为 “预写日志(WAL)”(详见 “写入 KV Tablet 与持久性” 小节)。
与Log Tablet 不同,KV Tablet 的数据存储在 RocksDB 中,不使用 Arrow 格式;但KV Tablet的子log tablet 仍正常使用 Arrow 格式。两者在数据写入、分层和读取逻辑上还有其他显著差异,将在以下小节说明。

写入 KV Tablet 与持久性机制
PutKV API 的输入为一批key-value records:当value值不为空时,Fluss 将其视为Upsert;当值为空时,视为删除(Delete)。KV Tablet 的写入流程如下:
- 对key-value records中的每条记录,查询 RocksDB 表以确定需发送到变更日志的变更类型:
- 若写入value值为空:生成包含旧行的 DELETE 记录;
- 若写入value值不为空且记录已存在:生成包含原记录的 UPDATE_BEFORE 记录和包含新记录的 UPDATE_AFTER 记录;
- 若写入值不为空且记录不存在:生成包含新记录的 INSERT 记录;
- 将新生成的变更日志记录和 RocksDB 写入操作暂时缓冲在内存中;
- 将所有缓冲的变更日志记录(以 Arrow IPC 格式存储)追加到子log tablet,并等待批次基于 Kafka 复制协议提交成功;
- 变更日志提交成功后,执行缓冲的 RocksDB 写入操作 —— 默认情况下,新记录会覆盖旧记录(关于合并引擎和部分列更新详见下一小节)。
持久性保障: log tablet 类似于 Kafka 分区,其副本分布在多个服务器上(1 个leader + 多个follower);而 KV Tablet 本身不复制,但会定期将 RocksDB 快照文件上传到对象存储。因此,变更日志充当了 KV Tablet 的Write Ahead Log(WAL):若服务器磁盘故障,可通过以下步骤恢复状态:
- 下载最新的 KV Tablet 快照文件;
- 从快照对应的下一个偏移量开始重放变更日志(快照中存储了最后一个偏移量)。
值得注意的是,KV Tablet 的 leader 没有 follower,而是会随子log tablet的leader的变化而迁移:当子log tablet 发生leader选举时,KV Tablet leader会迁移到新的子log tablet leader所在的 TabletServer。新的 KV Tablet leader需下载最新的 RocksDB 快照文件并重放变更日志,才能恢复原 KV leader的状态 —— 这意味着,如果 RocksDB 状态过大,每次leader选举时的下载和重放过程可能影响可用性,这一设计未来可能会调整。
合并引擎与部分列更新
默认情况下,主键表没有合并引擎,新行直接覆盖旧行(通过DefaultRowMerger类实现)。但 Fluss 支持在主键表中使用 FIRST_ROW 和 VERSIONED 两种合并类型,每种合并操作都涉及 “旧行” 和 “新行”(两者均可为空)。
合并类型:
- None:默认值,新行替换旧行;
- FIRST_ROW:保留旧行,若旧行为空则采用新行;
- VERSIONED:选择版本号最高的行(新版本号由客户端提供)
目前 Fluss 的 Flink 源支持 FIRST_ROW,但 VERSIONED 似乎尚未实际使用。
译注:合并引擎主要作用在写入端,读端不需要特殊处理,不过 FIRST_ROW 合并引擎只输出 insert-only changelog,因此 Fluss 在源端对 Flink 透出了该行为,是一种优化。实际上,这两种合并引擎在生产中都使用得很多。
部分列更新: 更新操作无需包含所有列,支持 “部分列更新”。需注意的是,部分列更新不能与合并类型结合使用:若写入仅包含部分列,Fluss 会使用PartialUpdateRowMerger类(而非DefaultRowMerger),按列逐一处理 —— 若新行包含某列,则采用新行的值;否则保留旧行的值,最终生成合并后的新行。
KV Tablet 分层
RocksDB 中的数据不能分层,必须完全容纳在磁盘上;其快照文件虽会存储到对象存储,但这属于 “备份 / 恢复” 和 “历史读取” 用途,而非分层。因此,KV Tablet 的键基数(Key Cardinality)不宜过大。KV Tablet 的变更日志是一个log tablet,其分层逻辑与前文 “Log Tablet 分层” 一致。

扫描 KV Tablet 变更日志
Fluss 客户端可向 KV Tablet leader发送 “点查” 和 “前缀查找” 请求,这些请求会被转换为 RocksDB 的点查和前缀查找操作。此外,客户端还可扫描变更日志,扫描的起始偏移量有三种选择:
- 最早偏移量(Earliest offset):从起始位置读取完整的变更流(假设log tablet 的保留期为无限);
- 最新偏移量(Latest offset):仅读取log tablet 的最新变更(会丢失历史数据);
- 完整模式(Full):先从 RocksDB 快照启动,再切换到读取变更日志。
完整模式(Full)的执行流程:
- Fluss 客户端联系CoordinatorServer,获取 KV 快照文件及其对应的变更日志偏移量;
- 客户端下载 RocksDB 快照文件,并基于这些文件初始化 RocksDB 实例;
- 客户端迭代 RocksDB 表中的记录,将每条记录视为 INSERT(+I)类型;
- 客户端切换到直接读取log tablet,从快照对应的下一个偏移量开始 —— 这一过程与日志表的读取逻辑一致,客户端可能收到实际数据,也可能收到已分层的log segments的元数据。
当然,上述流程通常集成在 Flink Source API 的 Split Enumeration 和 Split Reader架构中。

Flink 提供HybridSource抽象,支持先读取有界数据源,完成后切换到无界数据源;而 Fluss 选择在 Split这一抽象中实现这一逻辑:
- 对于基于主键的分桶,Split Enumerator会向CoordinatorServer请求 KV 快照的元数据,并生成包含 “快照 + log tablet 元数据” 的 “混合分片”(Hybrid Splits);
- 对于混合分片,每个分片reader会先将有界快照加载到 RocksDB 实例并处理记录,再切换到无界的log tablet(变更日志)。
Schema 管理
Schema 演进(Schema Evolution)已列入开发路线图[2]。
Fluss CoordinatorServer
Fluss CoordinatorServer在以下功能中扮演核心角色:
- 常规的集群元数据管理;
- 管理内部分层元数据并协调内部分层;
- 协调湖仓分层(详见下一部分);
- 直接向客户端提供元数据(用于客户端拼接)。
下一篇,我们将介绍 Fluss 核心架构如何扩展以支持湖仓集成。
[1]https://jack-vanlightly.com/blog/2023/8/17/kafka-kip-966-fixing-the-last-replica-standing-issue
[2]https://fluss.apache.org/roadmap/#storage-engine
来源 | Apache Flink公众号
作者 | Jack Vanlightly