
本文来介绍一下怎么下载 Ollama 并部署 AI 大模型(DeepSeek-R1、Llama 3.2 等)。通过 Ollama 这一开源的大语言模型服务工具,你就可以在自己的电脑上跑其它开源的 AI 模型。接下来,我们将分步骤说明如何完成下载和安装,以便你能够轻松地与 AI 开展对话。
步骤 1:下载并安装 Ollama
首先访问 Ollama 的官方 Github 地址:https://github.com/ollama/ollama,然后在页面上选择相关的系统进行下载(笔者在本文中以 macOS 为例,Windows 系统也是差不多的操作):

下载完成后安装即可:

安装完成后,打开「终端」窗口(macOS 可按 F4 搜索“终端”),输入ollama后出现以下提示说明安装完成。

步骤 2:安装 AI 模型
Ollama 安装完毕,我们还需要下载相应的 AI 模型才可以使用,可输入以下命令来下载相关模型:
ollama run Llama3.2
当然,你可以根据你的系统配置来下载其它 AI 模型,这是 Ollama 官方列出的模型,里面也列出了相应的下载命令:
Model |
Parameters |
Size |
Download |
DeepSeek-R1 |
7B |
4.7GB |
|
DeepSeek-R1 |
671B |
404GB |
|
Llama 3.3 |
70B |
43GB |
|
Llama 3.2 |
3B |
2.0GB |
|
Llama 3.2 |
1B |
1.3GB |
|
Llama 3.2 Vision |
11B |
7.9GB |
|
Llama 3.2 Vision |
90B |
55GB |
|
Llama 3.1 |
8B |
4.7GB |
|
Llama 3.1 |
405B |
231GB |
|
Phi 4 |
14B |
9.1GB |
|
Phi 4 Mini |
3.8B |
2.5GB |
|
Gemma 2 |
2B |
1.6GB |
|
Gemma 2 |
9B |
5.5GB |
|
Gemma 2 |
27B |
16GB |
|
Mistral |
7B |
4.1GB |
|
Moondream 2 |
1.4B |
829MB |
|
Neural Chat |
7B |
4.1GB |
|
Starling |
7B |
4.1GB |
|
Code Llama |
7B |
3.8GB |
|
Llama 2 Uncensored |
7B |
3.8GB |
|
LLaVA |
7B |
4.5GB |
|
Granite-3.2 |
8B |
4.9GB |
|
在控制台中,出现这个界面代表正在下载(时间会有点久,此过程跟你的网速有关):

当出现Send a message 提示时你就可以跟它进行对话了。

步骤 3:与 Llama3.2 模型开展对话
比如我给 Llama3.2 AI 模型发送一个“你是谁?”的对话:

你可以点击快捷键control+d来结束当前对话,当你关闭这个控制台窗口,下次还想开展对话的时候,也是运行这个命令ollama run Llama3.2,你下载了哪个 AI 模型,就运行哪个。
步骤 4:安装视图界面
每次都打开控制台来开展对话会非常的不方便,所以我们可以装一个 GUI 界面或者 Web 界面。Ollama 的官方 Github 上列有很多,你可以选择一个来安装,每个项目下都有详细的教程,这里不再详细展开说明。
步骤 5:调试 AI API
通过 Ollama 安装的 AI 模型,默认是提供 API 的,你可以在 Ollama API Docs 中查看。

下面我们通过 Apifox 来调试 Ollama 生成的本地 API,没有 Apifox 的可以去安装一个,它是一个非常好用的 API 调试、API 文档、API Mock、API 自动化测试工具。
1. 新建接口
首先复制下面的 cURL。
curl --location --request POST 'http://localhost:11434/api/generate' \ --header 'Content-Type: application/json' \ --data-raw '{ "model": "llama3.2", "prompt": "Why is the sky blue?", "stream": false }'
然后在 Apifox 中新建一个 HTTP 项目,在项目中新建一个接口,将上面的 cURL 直接粘贴到地址栏中,Apifox 会自动解析相关的参数,粘贴后保存即可。

2. 发送请求
保存接口后,来到「运行」页,点击「发送」,你将收到来自 AI 模型返回的响应。

如果要启用流式输出,你可以将 "stream": false 改为 "stream": true。


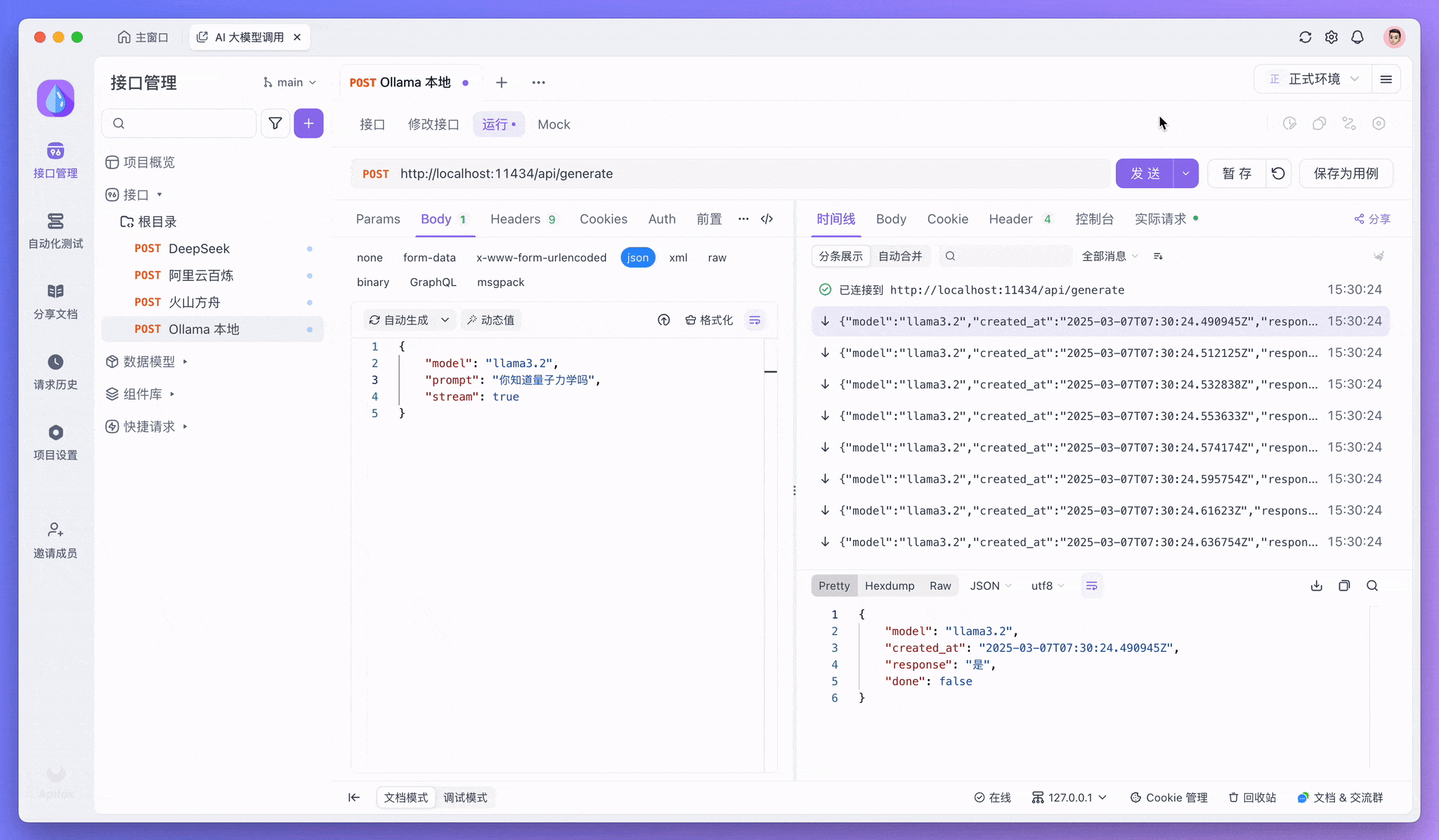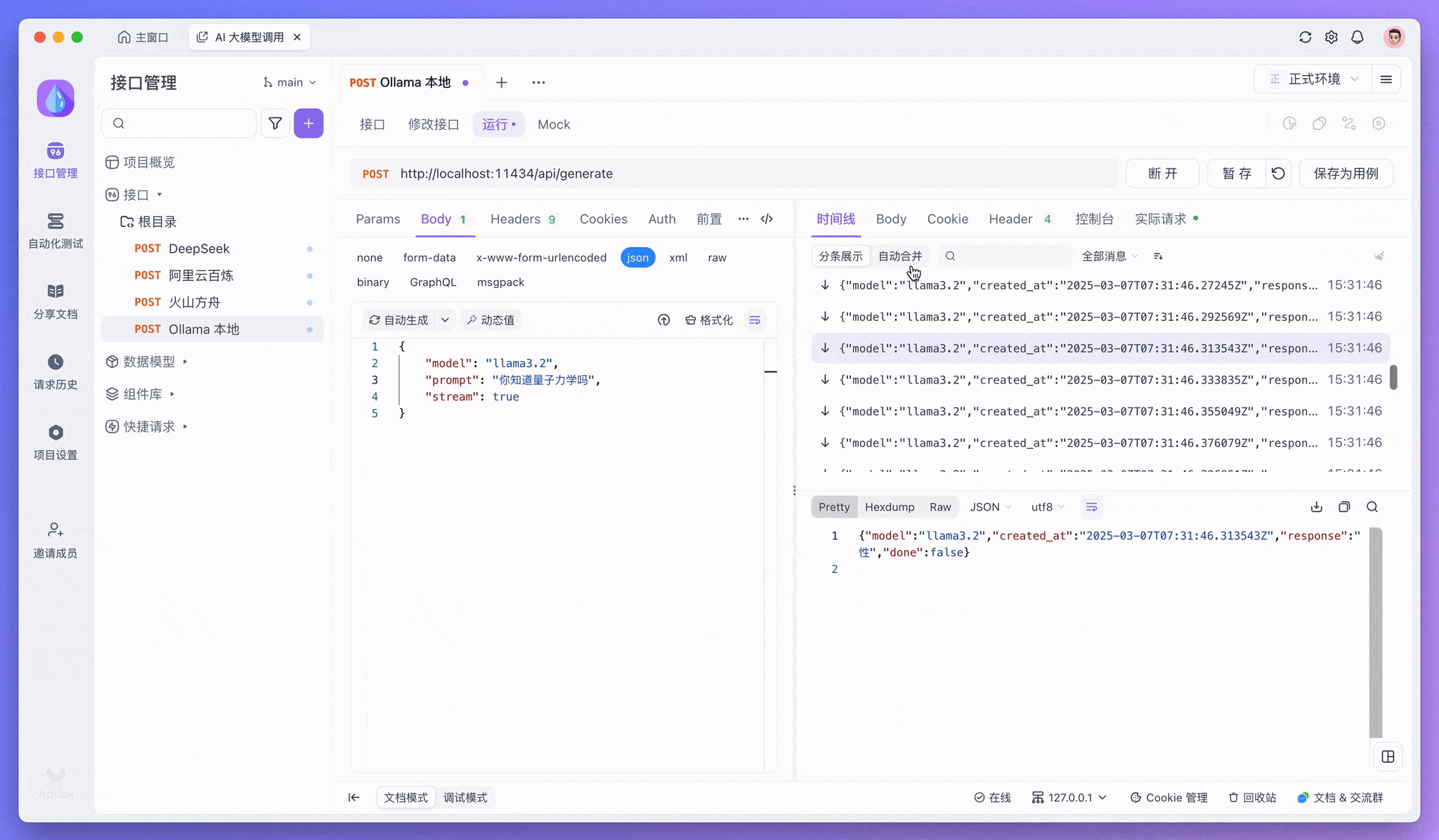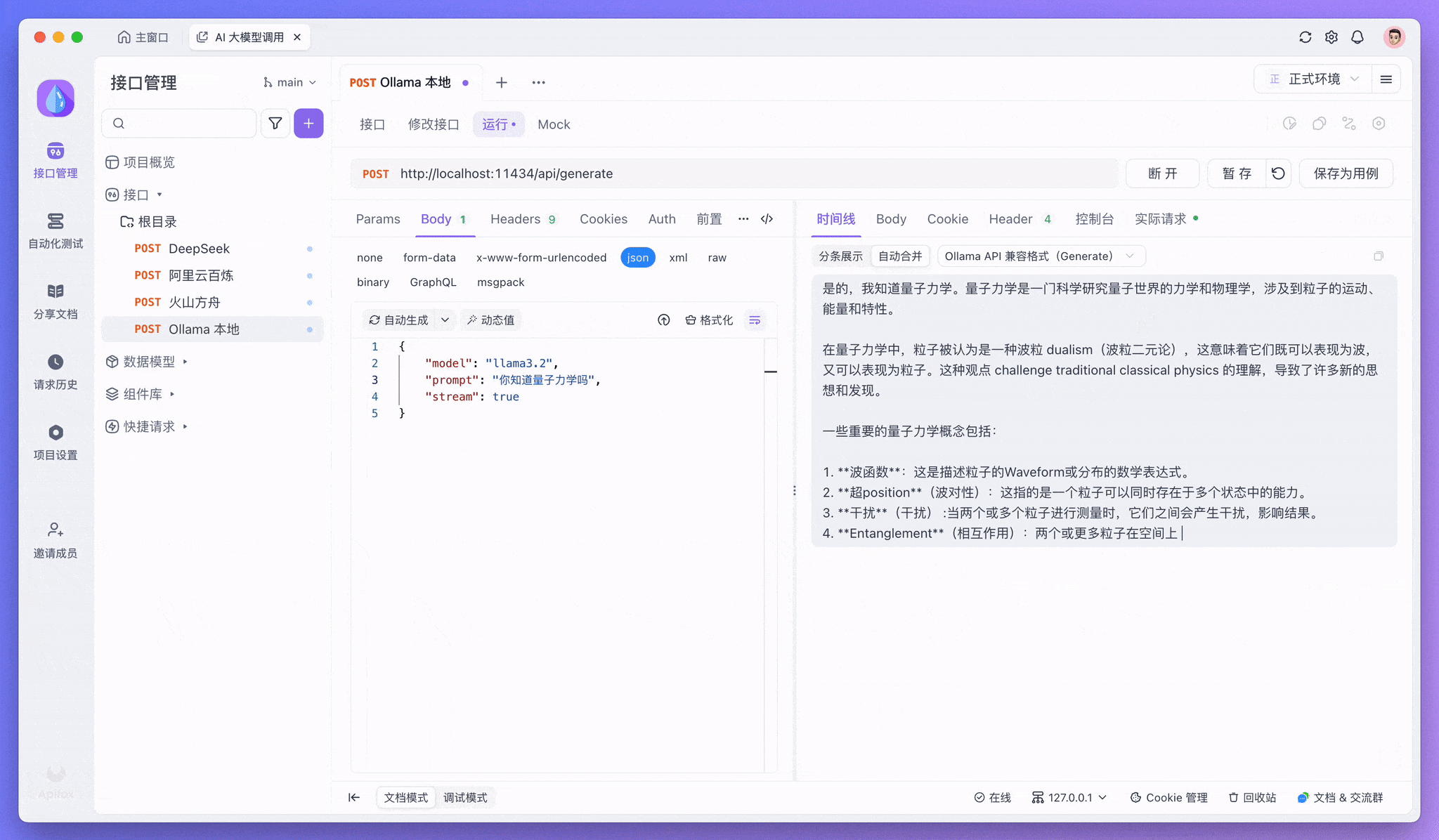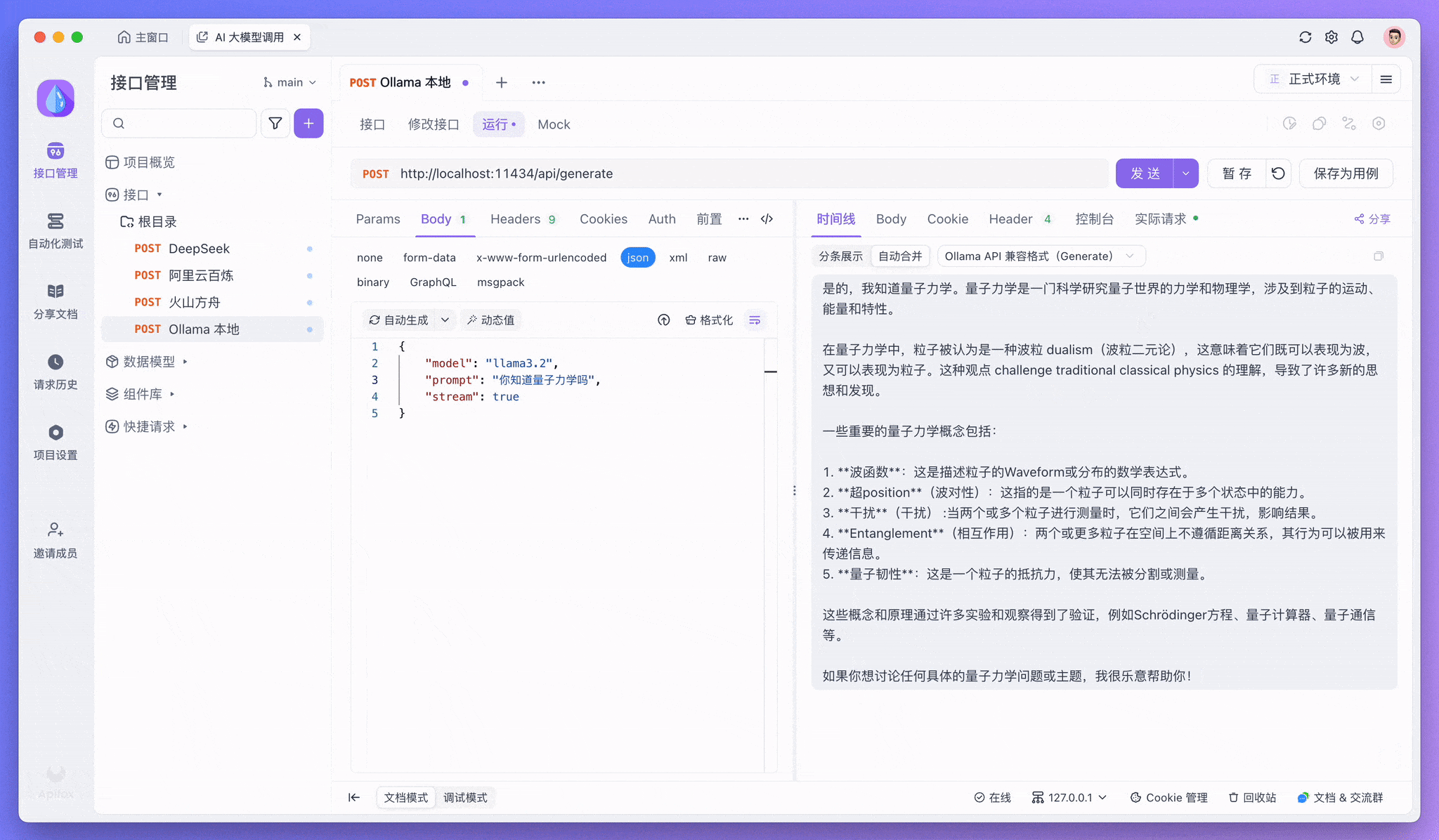
控制台中「校验响应结果」的提示可以忽略。
总结
本文详细介绍了如何利用 Ollama 工具在本地下载、安装和运行开源 AI 大模型(如 DeepSeek-R1、Llama3.2 等),分步骤讲解了从 Ollama 安装、模型下载、命令行对话到 API 调试的全过程,为实现高效便捷的 AI 互动应用提供了完整指南。

