动手吧.开发者:《用DataV Atlas探索杭州美食》有奖体验活动!点此进入!!
DataV 可视分析地图 Atlas 作为一款面向时空地理数据的可视分析工具,支持海量时空数据的快显渲染和实时分析,能够通过 SQL 分析方式对用户的海量时空数据进行实时渲染和多维分析,帮助用户快速构建自己的地理分析地图,挖掘时空数据价值。
下面通过一份杭州的美食娱乐兴趣点数据在 DataV Atlas 产品上为大家探索一下所谓的美食荒漠城市到底有没有美食?
登录产品控制台
1、领取DataV Atlas试用额度 https://free.aliyun.com/?searchKey=atlas;
2、打开产品控制台地址:https://atlas.datav.aliyun.com/,使用阿里云账号登录即可
查看数据中心样例数据
控制台登录默认进入的就是数据中心页,Atlas 数据中心提供了两个默认数据连接:
- Atlas 演示数据库:存放 Atlas 官方提供的一些演示案例数据,会不定期更新进一些数据集供用户试用
- 体验空间:免费提供 100MB 空间供用户上传自有的数据来体验产品功能

本次实验数据两张表存放于 Atlas 演示数据库的 public 文件夹下:
- "public"."hangzhou_poi_sample":杭州餐饮娱乐店样例数据,包括分类、地理位置和消费者评价等
- "public"."hangzhou_districts":杭州市行政区划数据,包括行政区划名称、行政区划代码、行政区划级别、行政区划中心点经纬度、行政区划边界等
在列表中点击表名称即可预览该数据,支持地图模式以及数据表模式预览,支持查看表记录数量以及存储占用



创建可视化项目
- 下面我们基于这两份样例数据开始我们的杭州美食探索之旅,点击顶部菜单从数据中心切换到 我的项目 ,点击 新建地理分析项目

- 默认会弹出添加数据对话框,选择 Atlas 演示数据库 下 "public"."hangzhou_poi_sample" 表添加到项目

- 添加至项目后会默认创建出一个可视化图层,点击左侧图层列表可以对图层进行样式配置

下面我们利用 SQL 来对这份样例数据进行一些好玩有趣的分析:
1、杭州各个区的吃货都爱吃些啥?
接下来为大家演示一下如何通过将行政区数据表与美食兴趣点数据表进行关联分析
新建一个 SQL 数据源,添加如下 SQL,这段 SQL 通过聚合出每个区数量最多的二级分类类别作为该区域的标签,并排除小吃快餐、水果生鲜、面馆以及本帮江浙菜
WITH CategoryCounts AS (SELECT b.name AS 区域名称, p.二级分类 AS 二级分类, COUNT(p.二级分类) AS 类型数量, b.geom as geom FROM public.hangzhou_districts b JOIN public.hangzhou_poi_sample p ON ST_Contains(b.geom, p.geom) WHERE 一级分类 = '美食' AND 二级分类 not in ('小吃快餐', '水果生鲜', '面馆', '本帮江浙菜') GROUP BY b.name, p.二级分类, b.geom), RankedCategories AS (SELECT 区域名称, 二级分类, 类型数量, row_number() OVER (PARTITION BY 区域名称 ORDER BY 类型数量 DESC) as rank, geom FROM CategoryCounts) SELECT 区域名称, 二级分类, 类型数量, 区域名称 || ' ' || '美食标签:' || 二级分类 as 标注字段, geom FROM RankedCategories WHERE rank = 1;

通过二级分类标签的类别进行着色还是不够直观,我们调整一下 SQL 语句,调整输出的CategoryCounts 中的 b.geom(行政区的几何字段) 字段为ST_PointOnSurface(b.geom)得到行政区内的标注点
WITH CategoryCounts AS (SELECT b.name AS 区域名称, p.二级分类 AS 二级分类, COUNT(p.二级分类) AS 类型数量, ST_PointOnSurface(b.geom) as geom --计算标注点 FROM public.hangzhou_districts b JOIN public.hangzhou_poi_sample p ON ST_Contains(b.geom, p.geom) WHERE 一级分类 = '美食' AND 二级分类 not in ('小吃快餐', '水果生鲜', '面馆', '本帮江浙菜') GROUP BY b.name, p.二级分类, b.geom), RankedCategories AS (SELECT 区域名称, 二级分类, 类型数量, row_number() OVER (PARTITION BY 区域名称 ORDER BY 类型数量 DESC) as rank, geom FROM CategoryCounts) SELECT 区域名称, 二级分类, 类型数量, 区域名称||' '||'美食标签:'||二级分类 as 标注字段, geom FROM RankedCategories WHERE rank = 1;
再次添加一个 SQL 数据源,粘贴上以上 SQL
我们将半径置为 0,打开文字标签,选择标注字段作为标签,调整一下字号和颜色,这样叠加后就可以清晰的看出各个行政区美食最多的二级分类是哪些类型了

2、高端大气上档次的火锅去哪吃?
如果想请吃火锅又想请吃点评分高、上档次并且性价比高,我们该如何利用 DataV Atlas 进行分析呢?很简单,我们可以通过以下 SQL 筛选出美食分类中的火锅店,然后选择评分大于四分,人均消费在 200 以上的
SELECT "店名", "人均消费", "评分", geom -- 别忘记带上 FROM "public"."hangzhou_poi_sample" WHERE "一级分类" = '美食' AND "二级分类" = '火锅' AND "评分" > 4 AND "人均消费" > 200
将上述 SQL 创建一个新的自定义 SQL 数据源,我们使用纯色带点透明作为颜色,根据评分作为半径的映射字段,映射区间设置为 5-15,再调整一下描边颜色和粗细

我们选择这个图层点击右侧的更多操作按钮,选择复制图层,创建一个新的图层

再对复制的图层,调整半径的映射为 人均消费 字段,再调整一下颜色为跟之前的图层对比度高的颜色

我们放大看一下,可以看到绿色的为人均消费,底下蓝色的为评分,我们想要找的高性价比自然是评分高人均低的,也就是环状的,小圈在上大圈在下

这样看起来还不是很清晰,我们再基于这个复制一个图层来作为标注图层,设置半径为 0 不显示点,打开标注选项,选择店名作为标签字段,调整标注的颜色和字号大小,记得打开顶部的 碰撞检测 开关来使标注更加清晰明了,还是很明显看出这些火锅店大部分都是海鲜火锅,毕竟海鲜也确实贵一些

3、为啥杭州被称为“美食荒漠”?背后成因的数据分析
更改底图
为了使得数据可视化的效果更明显,我们可以点击左侧的地图工具按钮来将默认的远山黛白色底图更改为雅士灰深色底图,并去掉底图默认的标注

添加 SQL 数据源
刚刚我们通过直接选择表的形式很方便地添加数据库中的任意一张空间表进行可视化,现在我们点击左侧数据源列表,通过底部的添加数据按钮以自定义 SQL 编写的方式来进行更强大的分析

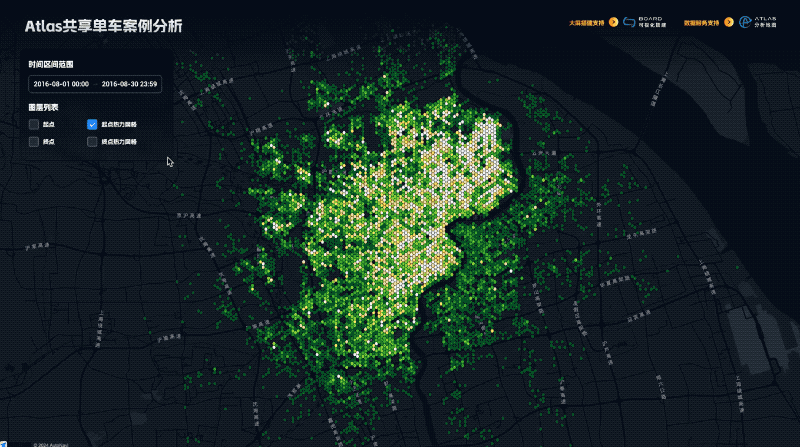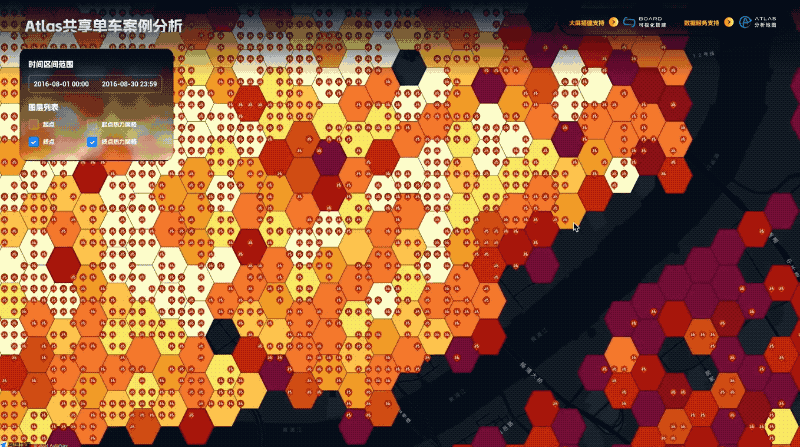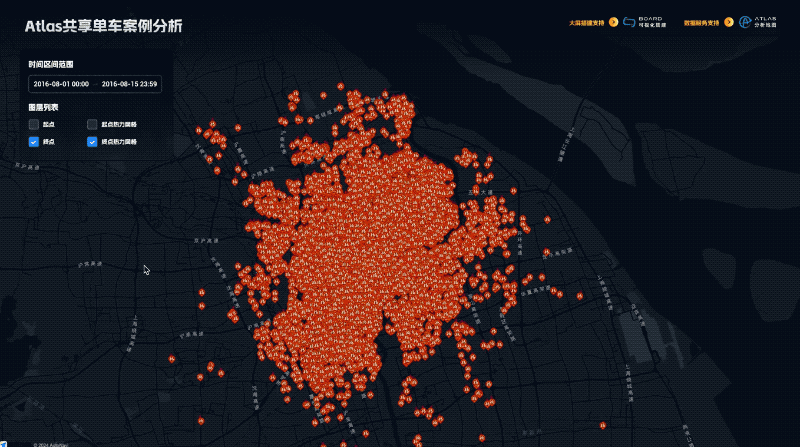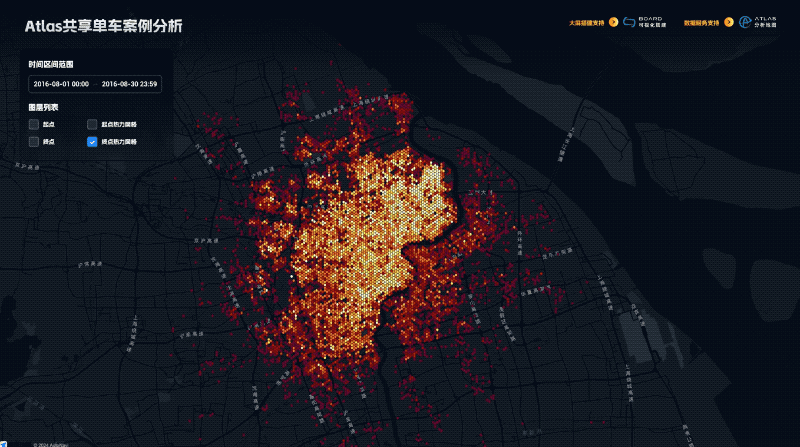
在底部弹出的 SQL 编辑器内添加以下 SQL 来计算杭州范围 500 米半径蜂窝网格中每个格子内的娱乐美食店铺数量,点击运行按钮
-- 计算杭州范围 500 米半径蜂窝网格中每个格子内的美食店铺数量 SELECT count(*) as 店铺数量, hexes.geom as geom FROM ST_HexagonGrid( 500.0 / 111000.0,--使用的的坐标系单位是度,1度约等于111千米,这里的意思是使用半径为500米的网格 ST_SetSRID(ST_EstimatedExtent('public', 'hangzhou_poi_sample', 'geom')::geometry, 4326) ) AS hexes INNER JOIN public.hangzhou_poi_sample AS p ON ST_Intersects(p.geom, hexes.geom) AND 一级分类 = '美食' GROUP BY hexes.geom;

对店铺数量进行颜色映射可视化
在左侧图层列表选择生成的蜂窝多边形的图层,点击颜色右侧的数据映射按钮,选择店铺数量字段进行映射,映射类型选择连续映射,预设模式我们选择极值映射(方便我们观察高值和低值数据对比),在色板中选择合适的色板,我们再将描边调细,颜色设置一些半透明来更清楚的看到填充颜色的映射规律,通过缩放底图可以很清楚的看到杭州的美食都聚集在哪些区域

对网格内人均消费进行聚合可视化
我们修改一下上述 SQL,再次创建一个自定义 SQL 数据源
SELECT hexes.geom as geom, AVG(人均消费) as 人均消费 FROM ST_HexagonGrid( 500.0 / 111000.0,--使用的的坐标系单位是度,1度约等于111千米,这里的意思是使用半径为500米的网格 ST_SetSRID(ST_EstimatedExtent('public', 'hangzhou_poi_sample', 'geom')::geometry, 4326) ) AS hexes INNER JOIN public.hangzhou_poi_sample AS p ON ST_Intersects(p.geom, hexes.geom) AND 一级分类 = '美食' AND 人均消费 IS NOT NULL GROUP BY hexes.geom;
这次我们选择三维拉伸面的展现形式来展示,为避免干扰可以暂时关闭其他图层的显示(通过图层列表项右侧的👀进行控制)

卷帘对比
点击右上角视图按钮可以切换分屏视图以及滑动视图进行对比分析

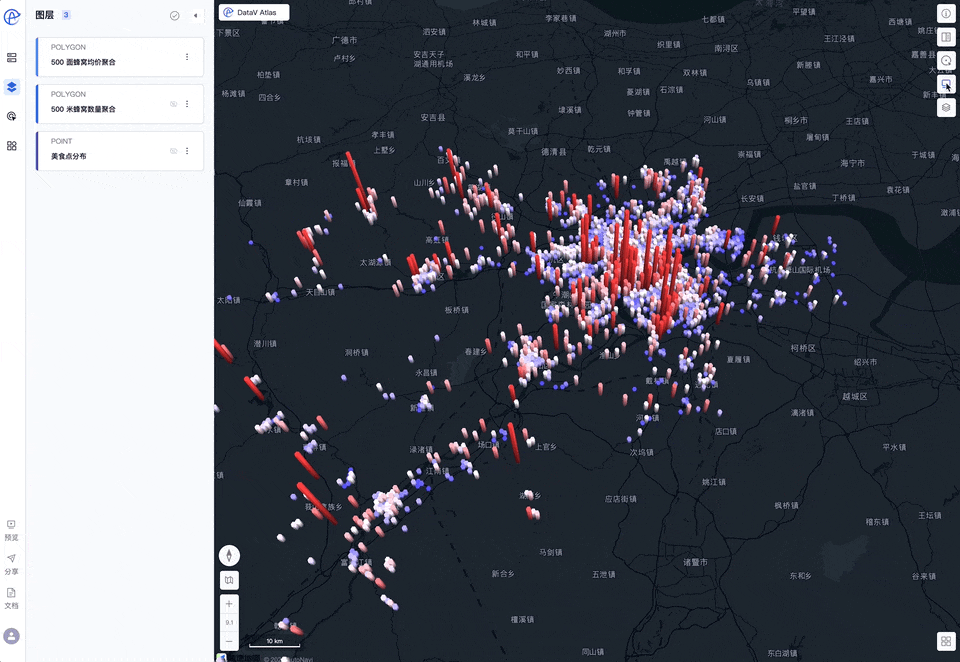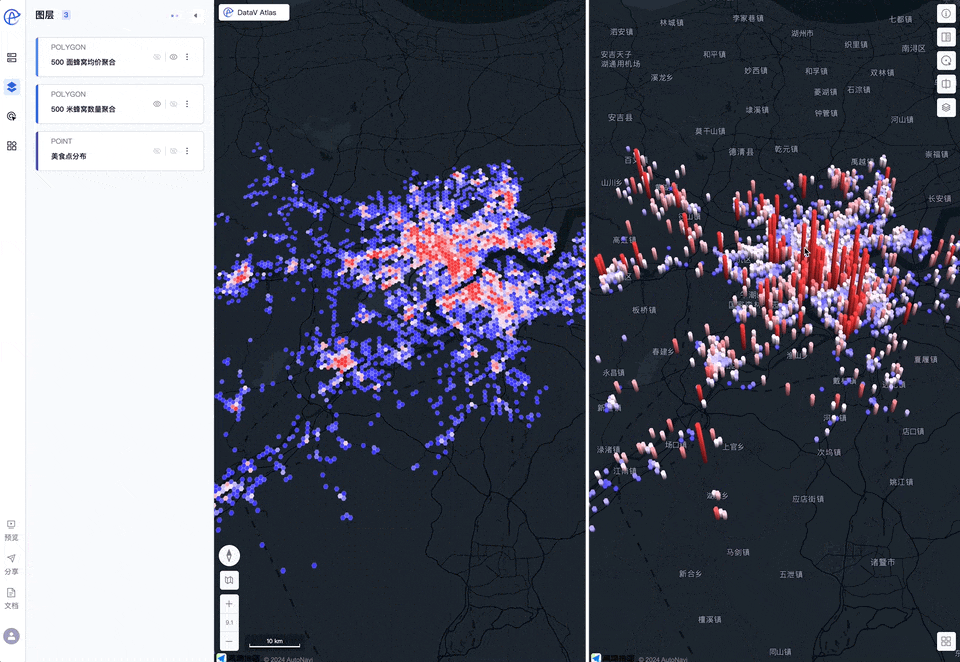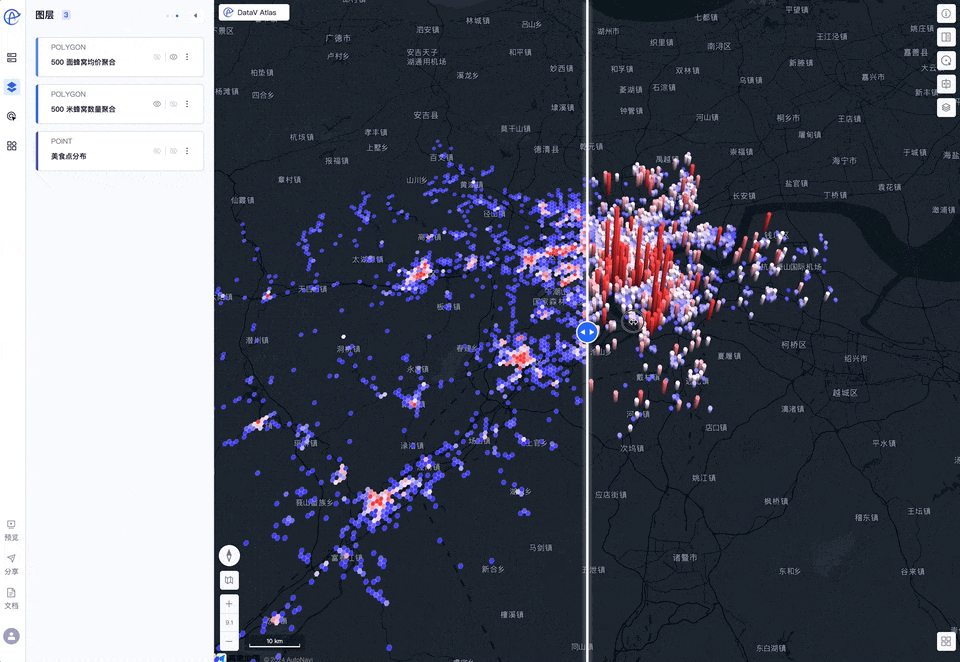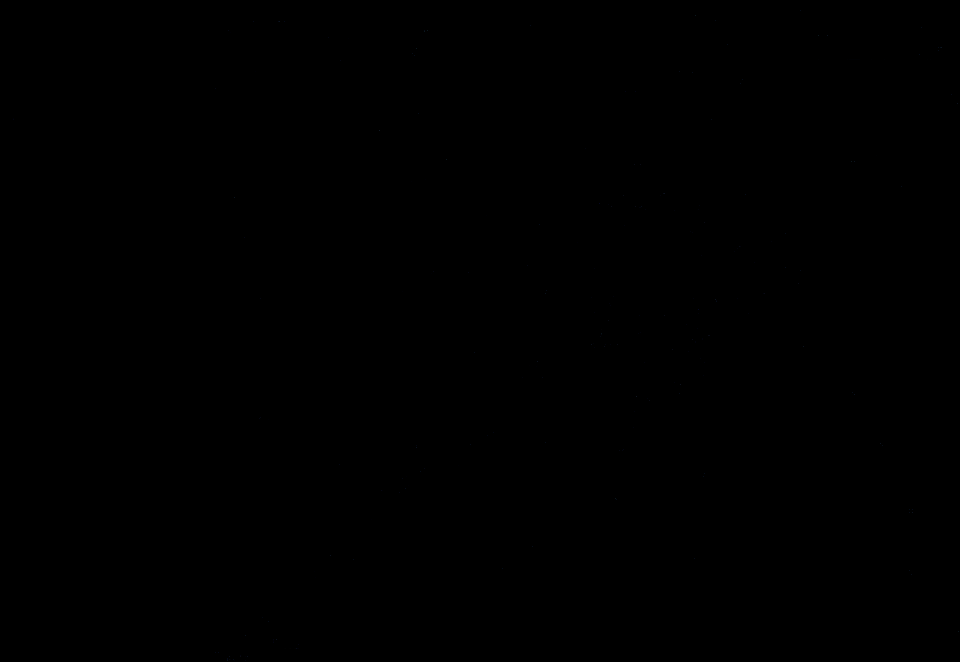
通过分析我们可以发现,杭州美食分布是非常不均衡的,人口和GDP大区-余杭区,美食数量少且高分店铺少,鉴于余杭区是互联网公司的聚集地,网络声量最大,由此造成了“杭州是美食荒漠”的网络论断!
附加技能:
配置交互
可以点击左侧的图层交互配置图层在鼠标点击或者悬浮时展示信息框,打开交互开关,选择点击或者悬浮,在每个图层的添加字段按钮可以添加需要显示在弹窗中的信息字段

分享报告
点击右下角分享按钮,点击分享项目即可获得一个可分享的链接 ,可以设置访问密码,可以鼠标 hover 到二维码上显示二维码,手机扫码即可查看分享地图,也可以把分享地址复制分享有趣的地理分析可视化作品给自己的好友。