免费体验阿里云高性能向量检索服务:https://www.aliyun.com/product/ai/dashvector

Embedding向量检索技术一般包括in batch negatives, hard batch negatives, gradCache, Cross batch negatives, 知识蒸馏(一般是把cross encoder的知识蒸馏到retriever里面),maxsim(也叫multi vector,出自Colbert), Matryoshka(中文叫做俄罗斯套娃,可以灵活变化embeddingsize,也是openai最近公布的技术),MAE,MLM预训练,随着时代的发展,现在的Embedding检索技术呈现出吸取大模型技术的趋势,比如instruction tuning, SwiGLU, flash attention,lora,nltk,alibi长序列,利用大模型进行打分,生成数据集等等,也有人直接探索使用大模型本身来做embedding,使用的是bitfit,LORA等技术,来微调LLM的部分参数。
而GRITLM有点特别,它是直接把BERT的双向注意力和对比学习直接搬到大模型里面,这样后续就一个大模型能够解决几乎所有的NLP任务了,不需要单独的Embedding模型来做这件事,RAG技术里面最重要的一项就是检索,RAG技术的核心应用难点就是检索的不准,导致大模型出现幻觉或者回答信息不全等问题,检索模型没办法做到很通用(即使是现在的搜索引擎也经常翻车,搜不到你想要的结果),需要定制化,那这样的话,Embedding训练就是一个必须的选项。
RAG基础
RAG其实是大模型时代最容易,最有效的一种大模型技术,首先通过信息检索获取上下文,然后把上下文输送给大模型来生成最终的输出,这种简单的范式能够解决大模型的幻觉问题,为大模型补充额外的知识,做事实性的校验等等。另外,在agents时代,其中的检索技术衍生的tool retriever,example retriever,memory retriever等技术在Agent的应用落地方面发挥着重要的作用。下面是一个最简单也是最流行的RAG技术应用到问答的示例:

RAG系统由两个关键阶段组成:
- 利用编码模型基于问题检索相关文档,如BM25、DPR、ColBERT和类似方法
- 生成阶段:使用检索到的上下文作为条件,生成答案文本
为什么需要Embedding向量化技术?
纯参数化语言模型(LLM)将从大量语料库中获取的世界知识存储在模型的参数中。本身有以下的局限性:
- 很难保留训练语料库中的所有知识,尤其是不太常见和更具体的知识。
- 由于模型参数不能动态更新,参数知识很容易随着时间的推移而过时。
- 参数的扩展导致训练和推理的计算费用增加。
RAG和Fine tuning的优缺点
从10个方面比较RAG和Fine Tuning LLM,方便大家对Embedding向量化技术有一个更深入的认识:
| 特征比较 | RAG | Fine-Tuning |
| 知识更新 | 直接更新检索知识库确保信息保持最新,而不需要频繁地再训练,使其非常适合于动态数据环境。 | 存储静态数据,需要对知识和数据更新进行再训练。 |
| 外部知识 | 精通利用外部资源,特别适合访问文档或其他结构化/非结构化数据库。 | 可用于将从预训练中获得的外部知识与大型语言模型相结合,但可能不太适合用于频繁更改的数据源。 |
| 数据处理 | 涉及最少的数据处理(data processing and handling)。 | 取决于高质量数据集的创建,有限的数据集可能不会显著提高性能。 |
| 模型定制 | 专注于信息检索和整合外部知识,但可能无法完全定制模型行为或写作风格。 | 允许基于特定音调或术语(specific tones or terms)调整LLM行为、写作风格或特定领域知识。 |
| 可解释性 | 响应可以追溯到特定的数据源,提供更高的可解释性和可追溯性。 | 与黑盒类似,人们并不总是清楚为什么模型会以某种方式做出反应,从而导致相对较低的可解释性。 |
| 计算资源 | 【数据库需要计算和存储】依赖于计算资源来支持与数据库相关的检索策略和技术。此外,它还需要维护外部数据源集成和更新。 | 【训练需要】高质量训练数据集的准备和管理,定义微调目标,并提供相应的计算资源是必要的。 |
| 延迟要求 | 涉及数据检索,这可能会导致更高的延迟。(一般来说检索的效率会比LLM生成的效率高很多,延迟可以做到ms级别) | 微调后的LLM可以在不检索的情况下响应,从而降低延迟。 |
| 减少幻觉 | 本质上不太容易产生幻觉,因为每个答案都以检索到的证据为基础。 | 可以通过基于特定领域数据训练模型来帮助减少幻觉,但在面对陌生输入时仍可能表现出幻觉。 |
| 道德和隐私问题 | 从外部数据库中存储和检索文本会引起道德和隐私方面的问题。 | 训练数据中的敏感内容可能会引发道德和隐私问题。 |
RAG的技术栈
主要分为prompt工程的方法和微调训练的方法,prompt工程的方法利用的是LLM本身的能力,现在典型的是llama_index和langchain工具包,而基于微调训练的方法分为对Embedding模型和大模型进行微调,一方面是增强Embedding模型的召回能力,另一方面是微调LLM做RAG对齐训练。

RAG技术落地有哪些难点?
从技术上的角度出发,现在最新的Embedding技术对跨语言,长序列的能力进行了拓展,通用能力得到了增强,但是实际业务场景还是需要微调(向量检索模型在特定领域还会出现不如BM25检索的情况),甚至预训练。另外,Embedding检索模型的训练的epoch不是越长越好,可能一个epoch或者几百个step之后,模型的性能就会下降。
Matryoshka Representation Learning
这个是让Embdding模型在inference time具备可变embedding size的方法(embedding size小能节约存储和计算消耗)。

原理图如下图所示,它是一个从粗粒度到细粒度的处理过程,对于检索任务,给定一个query,首先利用低纬度的query embedding来搜索候选集,然后用更高维度的向量来重新排序搜索候选集;对于分类任务,该方法使用级联的大小的表示来做分类(嵌套分类),通过阈值来判断是否需要提升为高纬度来进行分类。
Matryoshka表示学习(MRL)适用于任何表示学习设置,并通过优化O(log(d))所选表示大小处的原始损失L(.)来产生Matryoshka Representation z。Matryoshka表示可以有效地用于跨环境和下游任务的自适应部署。

Matryoshka表示学习的损失函数如下,其中L是Cross Entropy的分类损失,M表示嵌套的维度,在论文的imagenet分类中使用的是M= {8, 16, . . . , 1024, 2048},N表示的是数据集的数量,F表示深度神经网络,cm是relative importance(通常设置成1,超参数):

Retrieve Anything To Augment Large Language Models
LLM-Embedder,通过训练Embedding,来提升LLM在问答,tool检索,few shot,memory上的性能。

大模型的局限性:Knowledge boundary,Memory boundary,Capability boundary。
解决上述问题的一种方法是Retrievers:Knowledge Retriever(提供额外的知识), Memory Retriever(检索上下文), Tool Retriever(选择工具),Example Retriever(in context learning)。
LLM-embedder改进的点:
1.Reward from LLM.利用LLM得到rewards。
2.Stabilized distillation: 同时利用reward-based labels(LLM打分)和ranked base labels()来提升蒸馏的效果。
3.Instruction based fine-tuning:为了减小不同数据源带来的影响,使用了指令微调的方法(在query前面加入了特定的instruction文本,方便区分不同的任务)。
4.Homogeneous in-batch negative sampling:使用了cross device batch negatives,另外异构数据会导致一个batch里面有不同的任务的数据,因此构造的mini-batch需要保证是来自同一个任务(论文说使用了regularization strategy来构造训练集保证in batch negatives的数据来自同一个任务)。
下图显示的是LLM-Embedder的应用范式,本质上跟RAG差不多。

Nomic Embed: Training a Reproducible Long Context Text Embedder

这个模型本质上是一个吸收了大模型的模型技巧的BERT,效果超过了text-embedding-3-small,但是没超过text-emabedding-3-large,但是代码,数据和权重全部开源。
主体模型是一个BERT,但做了一些修改,模型结构:
- 把绝对位置嵌入替代为旋转位置嵌入(为了支持长序列)
- 使用SwiGLU激活而不是GeLU(训练速度更快)
- 使用了Flash Attention (节省显存,提速)
- Dropout设置成了0
- Vocab大小为64的倍数
经历了无监督预训练,有监督对比训练等等,在训练的时候最大序列长度是2048,然后在推理阶段使用Dynamic NTK interpolation把序列长度拓展到了8192. 使用SwiGLU在flash attention的情况下能够提升25%的效率。
训练细节:
Masked Language Modeling: 30% masking rate,global batch size 4096(batch size一般设置的都比较大),bfloat16,其他参数设置比较常规
无监督对比预训练: InfoNCE contrastive loss(如下图), 16,384 batch size, 1 full epoch, GradCache,specific prefixes来区分

retrieval的task的prefix是search query,检索的文档的prefix是search document,classification用于STS相关的任务,clustering用于聚类的任务,加上这些prefix能够对任务进行区分。使用specific prefix来区分是相似度的问题还是检索答案的问题,如果不加prefix,就无法区分任务,例如下面的例子:
What is the capital of France?”:
1. “What is the name of the capital city of France? (相似度任务)
2. “Paris is the capital of France.” (检索任务)
有监督对比微调:hard negatives training(根据人类标注的强负样本进行训练)。
注意:
1.将hard negatives次数增加到7以上并不能显著提高性能。对于多个epochs,性能会受到损害。
2.训练使用的配置是8xH100,Masked language modeling使用了4天,Contrastive pretraining使用了3.5天。
3.nomic-bert只是在部分数据集上比openai的embedding效果好。

JINA EMBEDDINGS 2: 8192-Token General-Purpose Text Embeddings for Long Documents
起因:许多embedding模型受到了最大序列长度的限制,一个解决方法就是把文档切分成很多chunks,但是这会造成文档的embedding向量过多,语义分散,还消耗存储空间,增加搜索的计算消耗,时延变长。
Jina Embedding 2采用的是BERT+Alibi的结构(Jina Embedding1采用的是T5 Encoder),其训练过程分为三个阶段:
Pre-training the Backbone: 设计了一个改进的BERT能够使用多达8192个token对文档进行编码,该模型是使用masked language modeling在全文语料库上训练的。
First Fine-tuning with Text Pairs: 为了将文本段落编码成单个向量表示,以无监督的方式对文本对模型进行微调。损失函数使用的是双向的(不是很理解),使用的是mean-pooling的embedding。

Second Fine-tuning with Hard Negatives:使用带有hard negatives的文本对,对模型进行了进一步的微调。这一阶段对于使模型能够更好地区分相关段落和相关但不相关的文本段落至关重要,模型训练的目标是InfoNCE+。

15表示的是负样本的数量,k表示的是batch size(本质上是普通的batch negative和in batch negative的叠加)。
BERT的结构的改进:
1.Attention with Linear Biases: ALiBi最开始是casual language modeling,不适合bert,因此做了一些修改,支持双向的language modeling。

2.Gated Linear Units: small and base models使用的是GEGLU,large model使用的是ReGLU(更稳定)。
3.Layer Normalization: 使用的是post-layer normalization,pre-layer normalization并没有增强稳定性和性能。
训练:使用了deepspeed的FP16,BF16在MLM accuracy和downstream GLUE tasks的表现不稳定。
MTEB的实验结果如下,模型能够达到openai text embedding差不多的水平,但是没有超过它。

注意:模型在预训练的时候使用的还是512个token长度,并不是8192.
Improving Text Embeddings with Large Language Models
使用大模型来合成数据来训练LLM的Embedding,选用的LLM模型是Mistral-7B,使用GPT4来合成数据,下面使用的是Prompt示例。使用GPT-4生成合成数据的两步提示模板示例。首先提示GPT-4做头脑风暴,列出潜在的检索任务,然后为每个任务生成(query、positive、negative)三元组。“{…}”表示占位符,它将被从预定义的值集中采样所取代。

训练的数据集构造如下,在前面加了task_definition的instruction:

在query和document的末尾加上[EOS]的token,然后使用LLM对应的[EOS]位置的向量作为最终的向量,目标函数采用的是InfoNCE loss。

其中N表示的是负样本的数量,q表示query,d表示document,如果对对比学习很了解,这个公式就是普通的对比学习公式。实验部分,模型训练了1个epoch,使用的是LoRA,DeepSpeed ZeRO-3,mixed precision,gradient checkpointing。

注意:1.模型从4K拓展到32K会造成性能下降,但调ROPE的参数可以达到90%的精度。
2.XLM-R large能够从预训练中获得性能提升,Mistral-7B使用对比学习预训练没有啥影响。
ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction
ColBERTv2采用的是ColBERT(BERT)的结构,使用的是MaxSim的操作来计算向量的相似度(cosine或者L2距离),colbert的公式和原理图如下:

#表示的是[mask]的token(模型使用的是mask的token进行padding到固定长度的),[Q]是query的special token,[D]是documents的special token,filter表示的是document里面的标点符号会被去除,不参与计算late interaction.【公式里面的CNN不知道表示的是啥,论文也没给解释?】



Q表示的是query vector,N表示query的N个token的vector,D表示passage,M表示passage有M个vectors。colBERT的检索流程使用的是faiss IVFPQ index,为了加快检索,embedding向量则会使用byte进行编码,然后在ranking流程才会采用maxsim。colBERTv2模型在训练的时候按照RocketQAv2的做法,引入KL-散度来把cross-encoder(采用的是23M MiniLM)的知识蒸馏到ColBERT中,训练的策略包括in-batch negatives和hard negatives训练,还补齐了检索的性能瓶颈,有兴趣可以看看论文了解更详细的信息。
BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation
BGE M3-Embedding支持100多种语言以及跨语种的检索,利用了dense,sparse,multi vec的检索来进行知识蒸馏训练,其中dense retrieval用的是[cls] embedding,sparse和multi vector retrieval用的是其他的token embedding。

下图是M3-Embedding和自我知识蒸馏的多阶段训练流程,包括pre-trainging和fine-tuning,

注意:
1.这里的基模型使用的是XLMRoBERTa,作者对长序列的支持是通过预训练把数据集和max seqence length调整到了8192的(不可思议),而没有使用长序列的的trick。
2.论文给的结果比open ai的text embedding要好很多。

Generative Representational Instruction Tuning

GRIT模型处理基于给定指令的文本表示和生成任务。对于表示任务,指令理想地包含目标域、意图和单元。表示是数字的张量,而生成输出是文本。

左图:GRITLM在嵌入任务的输入上使用bidirectional attention。mean pooling应用于最终隐藏状态,以产生最终表示。右图:GRITLM在生成任务的输入上使用causal attention。隐藏状态之上的语言建模头预测下一个标记。该格式支持多个回合的对话(用“…”表示)。对于Embedding任务使用的是in-batch negatives。
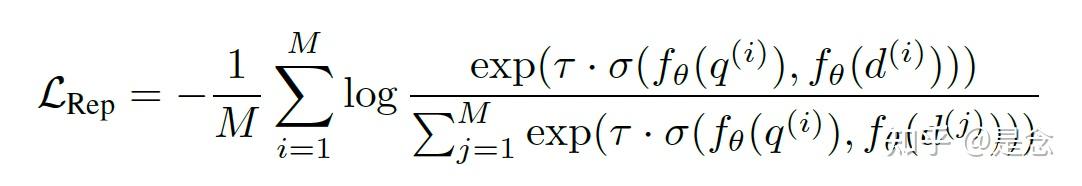
生成式任务使用的是next token prediction。


论文给出的实验结果也挺惊艳的,效果超过了OpenAI的 模型。

应用
- 对话搜索引擎
- 复杂内容生成
让大模型根据多篇文档生成综述或者调研报告是一件比较复杂的事情,由于大模型长度的限制,所以多篇文档不可能同时送入大模型来进行生成,所以这里就需要search and generate的方式,实际上就是一个RAG技术的泛化。
- Agents
Agents(即使用工具的能力)是当前最流行的应用范式,除了知识库跟Agents来解决外部知识的问题外,Agents跟检索结合的地方还有很多,比如tool retriever, few shot retriever, memory retriever等等,这些技术都极大的拓展了Agents的能力,这些retriever并不是把检索模型应用一下进行,需要进行训练和prompt工程进行优化。
总结和展望
现在的向量检索技术呈现出吸取大模型技术的趋势,要么就是直接改造原始的BERT模型,然后预训练,无监督微调,有监督微调,要么就是直接上大模型,直接进行LORA,Bitfit微调等等。总体来讲,向量检索技术的更新稍落后于大模型的技术更新,但是大模型技术的发展,对向量检索模型起到了促进的作用,未来可能会把向量检索模型合并成大模型的一个子任务,这样所有的NLP任务就呈现出来大一统的局面了。
了解更多阿里云向量检索服务DashVector的使用方法,请点击:
https://help.aliyun.com/product/2510217.html?spm=a2c4g.2510217.0.0.54fe155eLs1wkT




![人工智能创新挑战赛:海洋气象预测Baseline[4]完整版(TensorFlow、torch版本)含数据转化、模型构建、MLP、TCNN+RNN、LSTM模型训练以及预测](https://ucc.alicdn.com/fnj5anauszhew_20230607_83592c071f9241edb19dec6aabfa5f4e.png?x-oss-process=image/resize,h_160,m_lfit)
![推荐系统[三]:粗排算法常用模型汇总(集合选择和精准预估),技术发展历史(向量內积,Wide&Deep等模型)以及前沿技术](https://ucc.alicdn.com/images/user-upload-01/44083e4c130841f894e36366a71f8d96.png?x-oss-process=image/resize,h_160,m_lfit)