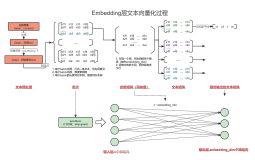
免费体验阿里云高性能向量检索服务:https://www.aliyun.com/product/ai/dashvector
文本转换为向量有多种方式:
方法一:通过模型服务灵积DashScope将文本转换为向量(推荐)
方法二:通过ModelScope魔搭社区中的文本向量开源模型将文本转换为向量
方法三:通过Jina Embeddings v2模型将文本转换为向量
本文介绍方法三:如何通过Jina Embeddings v2模型将文本转换为向量,并入库至向量检索服务DashVector中进行向量检索。
前提条件
- DashVector:
- 已创建Cluster:创建Cluster
- 已获得API-KEY:API-KEY管理
- 已安装最新版SDK:安装DashVector SDK
- Jina AI
- 已获得API密钥:Jina Embeddings v2模型
Jina Embeddings v2模型
简介
Jina Embeddings v2模型,唯一支持 8192 个词元长度的开源向量模型,在大规模文本向量化基准 (MTEB) 的功能和性能方面与 OpenAI 的闭源模型 text-embedding-ada-002 相当。
模型名称 |
向量维度 |
度量方式 |
向量数据类型 |
备注 |
jina-embeddings-v2-small-en |
512 |
Cosine |
Float32 |
|
jina-embeddings-v2-base-en |
768 |
Cosine |
Float32 |
|
jina-embeddings-v2-base-zh |
768 |
Cosine |
Float32 |
|
说明
关于Jina Embeddings v2模型更多信息请参考:Jina Embeddings v2模型
使用示例
说明
需要进行如下替换代码才能正常运行:
1.DashVector api-key替换示例中的{your-dashvector-api-key}
2.DashVector Cluster Endpoint替换示例中的{your-dashvector-cluster-endpoint}
3.Jina AI api-key替换示例中的{your-jina-api-key}
以下为Python示例:
from dashvector import Client import requests from typing import List # 调用Jina Embeddings v2模型,将文本embedding为向量 def generate_embeddings(texts: List[str]): headers = { 'Content-Type': 'application/json', 'Authorization': 'Bearer {your-jina-api-key}' } data = {'input': texts, 'model': 'jina-embeddings-v2-base-zh'} response = requests.post('https://api.jina.ai/v1/embeddings', headers=headers, json=data) return [record["embedding"] for record in response.json()["data"]] # 创建DashVector Client client = Client( api_key='{your-dashvector-api-key}', endpoint='{your-dashvector-cluster-endpoint}' ) # 创建DashVector Collection rsp = client.create('jina-text-embedding', 768) assert rsp collection = client.get('jina-text-embedding') assert collection # 向量入库DashVector collection.insert( ('ID1', generate_embeddings(['阿里云向量检索服务DashVector是性能、性价比具佳的向量数据库之一'])[0]) ) # 向量检索 docs = collection.query( generate_embeddings(['The best vector database'])[0] ) print(docs)
了解更多阿里云向量检索服务DashVector的使用方法,请点击:
https://help.aliyun.com/product/2510217.html?spm=a2c4g.2510217.0.0.54fe155eLs1wkT