免费体验阿里云高性能向量检索服务:https://www.aliyun.com/product/ai/dashvector
在聊这个问题之前,我们先来看一张Google Trends的图表:

从这张Google Trends的图表里,可以明显看出,在ChatGPT引爆全球之后,人们对向量数据库的关注度陡然上升。然而在此之前,这一领域却经历了极其漫长的沉寂期。
诚然,大语言模型(LLM)需要向量数据库,似乎已成为一个不争的事实。但可能鲜少有人关注到,早在LLM之前,基于向量数据库的应用早已进入我们的日常生活。举例来说,以文搜图、以图搜图这些常见的多模态数据检索,就广泛地应用于百度谷歌等搜索引擎,淘宝拼多多的“拍立淘”等组件。除此之外,向量数据库也在支持着搜索、推荐、广告等核心引擎中的模糊查询与模糊召回模块。
然而,以上提到的这些应用场景较小,而大模型所涌现的强大智能,却让资本看到了一个改写所有行业范式的可能性。在大模型的这阵东风下,向量数据库凭借着三方面优势终于“出圈”:
- 向量数据库可以大大缓解大模型的幻觉问题。
- 向量数据库可以降低大模型的推理成本。
- 高昂的训练成本和数据成本,让大模型不能持续跟进最新的信息数据,也让很多垂直行业中的企业望而却步。
向量数据库为什么会有这三大优势呢?
传统搜索引擎的天花板
向量数据库的蓝图构想,源自于计算机科学与人工智能前沿研究的一个野心:让神经检索(Neural Retrieval)成为现代信息检索的主流范式。
说到这里,可能会有同学想问:“传统的搜索引擎有什么问题呢?百度谷歌不是用得好好的吗?”为了解答这个问题,就让我们先来了解一下传统的文本搜索引擎的“前世今生”。
了解互联网历史的同学可能知道,搜索引擎大致经历了“目录索引”和“全文索引”两个阶段:
早期的目录索引阶段,搜索引擎首先要对互联网信息进行分门别类,将互联网上的信息整理成类似图书目录一样的层级分明的树状结构。用户使用的时候,其实是按照查询百科全书的流程,凭借自己的专业知识,一级一级定位到自己需要的信息。这样的“搜索引擎”其实并不能称为搜索引擎,比较确切的表述更像是“门户网站”。这类网站的维护和使用成本都非常高,只能在互联网信息比较少的早期使用,但随着互联网信息体量的指数的攀升,这类索引很快就被淘汰。
而现在我们看到的大部分搜索引擎,使用的是“全文索引”的方法。搜索引擎会定期使用爬虫爬取新增页面信息,通过简单的文本处理方法(主要指分词工具),构建“倒排索引”,来实现对包含特定关键词的网页的检索抽取。这样的引擎搜索方式,有一个很大的问题在于:它其实无法真实理解用户的搜索意图。下面,我们就来看一个当代搜索引擎的典型案例。

当我们把这样的搜索词条打入搜索框中,搜索引擎处理搜索请求的过程大致如下图所示:

如图所示,我们可以看到,这样的检索会带来一个核心问题:“无法真实理解用户的语义意图”。
而这个问题产生的原因有如下两方向:
1. 在处理请求时,按照“词”的粒度将请求分拆,分别到网页文档的倒排索引中去匹配。
2. 在构建索引时,将文档同样按照“词”的粒度分拆,分别构建到独立的倒排列表中去。
对于这个搜索请求,当我们想要的搜索答案为“处理收养孩子业务的律师都有谁”的时候,搜索的结果是可以满足诉求的。但是,当我们想要的搜索答案为“某个领养了孩子的律师叫什么”的时候,我们会发现页面中完全看不到满意的搜索结果。此时,只有在搜索匡中新增一些背景知识,进一步细化请求的时候,才可以得到比较满意的结果(如下图所示):
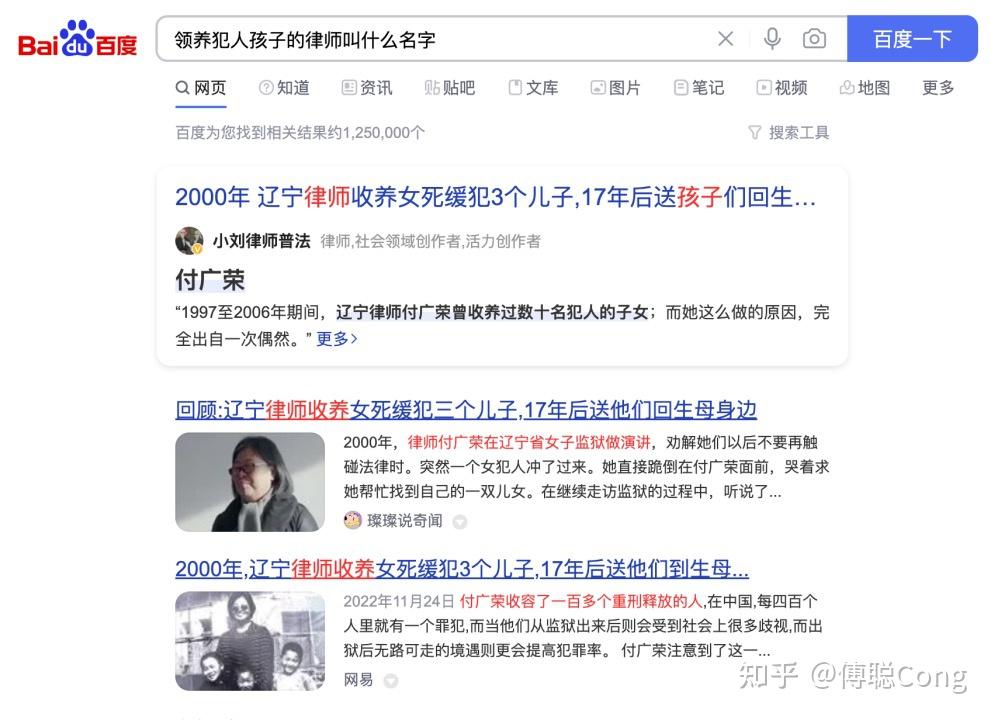
通过上面这个案列,我们可以发现当下的主流文本搜索引擎,仅仅按照独立的“词”的粒度去理解所有文档,很难对文档有一个全局的、语义层面的认知。这就使得,在海量信息蜂拥而至,用户数量和用户需求多元化的今天,传统搜索引擎已经逼近了自己的天花板。
一个理想的搜索引擎,应该是一个实用的解决问题的工具:它不能要求用户拥有超越引擎的背景知识,更不能要求理解引擎弱点,而进行自发自主的优化查询技巧。
一个理想的引擎应该在理解用户语义的基础上提供多样化理解的查询结果。这就是neural retrieval或semantic retrieval(语义搜索)所期待的效果。当然,neural retrieval的野心不仅如此,它还希望实现文本、图片、视频、音频所有常见多模态数据之间的互搜。而实现这一目标的重要途径,就是跨膜台统一的数据表征(neural representation)。
与压缩有关
在计算机中,如果一篇文章包含10000个字符,那么大约需要10KB去存储它,但如果可以用64个浮点数(计算机内对实数的一种数值表示)来表示这篇文章,那么就可以将存储空间压缩到256个字节。这就比以字符存储的方式缩小了大概40倍。而如果对于任意大小的文章,都用256个字节来压缩,那么此时除了存储空间之外,还能获得另一个优势——在内存或磁盘空间连续对齐存储,从而加速访问。这就引出了另外一个话题“对齐压缩”。
在今天的计算机系统里,已经有大量现存的无损压缩算法或格式,例如zip、rar等。但没有任何一种方法可以实现高效且对齐的压缩能力。为了实现这一压缩目的,表征学习压缩应运而生。而在介绍这个压缩方式之前,让我们先来简单了解一下什么是“表征学习”。
虽然基本元素以及表达的含义不同,所有模态的数据在计算机中都是以0和1进行表示。例如:“文本”是将文字的最小单元编码为二进制来存储;“图片”是将像素的色彩和位置用二进制来存储。由此可见,两种截然不同的编码方式,直接导致了两种数据无法互相“理解沟通”,最后归于两种不同的模态。
以此类推,如果人类可以通过某种方式,将“眼之所见”和“文之所写”一一对应起来,那么计算机是否也可以呢?举个列子来说:当人们提到“小猫”,我们的脑海中就会浮现出“小猫”的画面。那么计算机是否也可以以某种方式,将不同模态的数据表示统一到同一个领域内呢?从这一思考中,延伸出来的AI前沿领域就被称为表征学习“representation learning”。
了解完了“表征学习”,让我们再回到“表征学习压缩”,表征学习所做的压缩是不同于目前电脑系统中常见的无损压缩,简单来说,它是一种有损压缩。既然是有损压缩,那么如何决定压缩的损失和保留部分呢?
表征学习认为,能够抽取文档的核心信息,并且让表达相近信息的文档,在这个64维实数空间内尽可能互相靠近;让表达差异很大信息的文档,在这个空间中彼此远离,这样所伴生的良好属性即是“适合进行文档检索“的。换句话说,只要定义了度量文档相似度的方法,就相当于定义了文档相关性的函数f(x,y),就可以实现f(“dog”, dog.jpg) > f(“dog”, cat.jpg)的惊艳效果。
此时,一个新的问题就出现了——如何定义度量文档的相似度?在数学的高维空间中,常用的相似度度量方式有两种:欧式距离和内积距离。我们以下面这张图片为示例:多模态表征学习下,将不同模态的数据映射到统一的、以内积距离为度量的高维空间。通过特殊设计的多模态神经编码器(neural encoder),将不同模态的数据表示成同样长度(维度)的浮点数向量。可以看到,内容相似的文档可以形成“聚类”效应,聚集在一起;不相似的文档则形成“泾渭分明”的不同聚类(用不同颜色标记的点云)。

而大语言模型,在现阶段,很可能就是地表最强的encoder。这里有人可能会问,以GPT为代表的LLM不都被称为Decoder-only Transformer吗?为什么又说它是encoder呢?其实,当这类模型在预测下一个token的时候,所依赖的信息其实是前文(context)中的信息经过模型所获得的潜在语义表达,而这个表达的形式其实就是一个向量。简单来说,在LLM中,token是向量,模型在推理预测下一个token的时候,中间所有的信息传递过程也是通过向量。一言以蔽之——“向量或许才是LLM自我思考过程中的最基本的元素!”诚然,当下的很多主流大模型(解码模型)的表征还不够强力,一些应用方案往往在用传统的一些向量表征框架进行学习,随着大模型技术的持续发展,相信表征模型和解码模型会有统一的一天。
1+1> 2 的结合
前文提到,表征学习可以有效压缩多模态的信息,充分理解其中的语义;同时,向量数据库又是一个高效的针对向量的定制化搜索引擎。那么两者相遇自然一拍即合,有潜力解决传统搜索引擎的“天花板问题”。除此之外,当向量数据库遇见大语言模型(+表征学习),可以产生1+1>2的效果。
三方面的原因如何理解,如何生效?
向量数据库为什么可以缓解LLM的幻觉问题呢?
在解答这个问题之前,我们需要先理解LLM的幻觉是什么?而又为什么LLM会产生幻觉?
让我们以Kurt等人的经典论文《Retrieval Augmentation Reduces Hallucination in Conversation》中展示的一个GPT3出现幻觉的例子,来做为示例。下面,我就在chatGPT上再次尝试复现:



这三个图我们可以大概理解何为大语言模型的幻觉,即答非所问,甚至胡编乱造。当我们对大语言模型的“幻觉”行为进行针对性测试的时候,我们会发现大语言模型往往会对冷门、低频或缺乏权威度内容的提问产生错误响应。那么,这个问题是由什么引起的呢?
了解过大模型技术方案的同学可能比较熟悉,大模型是通过Softmax-Cross Entropy(交叉熵)损失函数进行训练的,这个损失函数的本质,是希望大模型预测的token的分布尽可能接近标签分布,也就是接近训练语料里面token序列的概率分布。大模型学习到的模式,就是当预测下一个词(token)的时候,在所有候选token上面进行概率的分配。同时,我们也知道,大模型是通过梯度下降的方法进行优化的。那么当某种特定序列频繁出现的时候,大模型可以根据对应的函数“损失”不断修正自己的预测分布,来逼近在自然语料中序列的效果。
正是出于这种训练方法和建模方式,大模型得以把“世界知识”高效地压缩到自身庞大的参数之中。但也是因为这样的属性,大模型容易出现两类较难解决的幻觉:
- 在公开电子资料中出现频次少的“冷门知识”。比如上述幻觉案例。
- 在公开资料中频繁更新,容易自我冲突的案例,OPEN AI对这类问题做了很好的规避。

很多人认为大模型通过持续的训练学习,就可以解决幻觉问题。然而现实情况是大模型在知识修正这一问题上仍步履维艰。如下图,是大模型在微调下依然难以修正幻觉的一个简单的图例:

从这个图我们可以看出,虽然通过在某些“易错”语料上进行持续训练,可以有效的改进模型的预测分布(经过训练后的模型,在预测Paris这个token的时候,概率有所下降),但对于有些“顽固”的分布是很难去扭转的(如图,Paris这个token的预测概率依然是最高的,模型依然会选择预测这个token)。而过度训练大多数时候则可能导致效果衰退。此外,通过持续训练大模型来跟随知识的更新和增强能力有以下几个难点:
1. 知识更新速度过快,但大模型训练成本过高。
2. 知识体系内部可能存在一些矛盾,增量训练很难扭转预测分布;过度训练会导致模型其他能力退化。
3. 模型自身记忆能力也有限。
但从2020年的研究开始我们就发现,当下的大模型在有prompt的情况下工作地更好(也就是大家常说的in- context learning)。那么我们可以把更多相关的信息嵌入到prompt之中来充分发挥模型的潜力,Retrieval Augmented Generation(RAG,搜索增强)应运而生。
为什么RAG可以解决以上三个问题呢?
首先,大模型可以在优质的prompt引导下给出更好的回答,主要在于大模型在训练的过程中,尤其是SFT阶段,会针对性地引导模型的推理以及指令跟随(instruction following)的能力。其次,优质的prompt可以更好地引导推理概率分布,使得模型可以从prompt当中或者自身压缩的记忆之中抽取答案。那么,针对RAG框架,让我们把零碎的、不连续的、但与搜索问题相关的知识塞到prompt之中的时候,大模型其实需要”跟随的指令“是根据自身推理能力定位相关信息的位置,然后完成复制和粘贴!
回忆起前文提到的传统搜索引擎的缺点,是很难理解用户的语义。它可能找到了与用户语义相关的内容,但却混杂在了成千上万不相关的内容之中,于是把最后一步:相关内容碎片的理解和拼凑的成本转移给了用户。而RAG的优势,主要就是将这一部分成本转移给自己,提供更优质的用户体验。
于是,我们不需要大模型有完备的知识储备,也不需要大模型有强到完全不出错的推理能力,我们只需要把相关的信息通过检索的方式嵌入到prompt当中,模型只需要在此基础上进行总结和推理即可。我们可以通过大模型外挂数据库或者搜索引擎来实现这一目标。
这里,很多人会说,向量数据库目前也不是搜索引擎和数据库的核心组件,RAG和向量数据库有什么必然关系呢?
不错,RAG不一定非要依赖向量数据库,也可以通过关键词抽取、重组的方式接入传统搜索引擎来实现。这可能也是近期向量数据库渐渐的一个主要原因。但我个人的想法是,目前以向量为核心的检索还需要依赖语言模型的表征技术的进一步发展,向量数据库依然会是未来RAG的核心。原因是,基于向量的语义表征技术,对语义信息的理解必然会大幅超越传统关键词搜索的框架。另外,token,或者说分词,并不是大模型自己的语言体系,向量才是。所有的token,可以理解为模型语言(向量)向人类语言(token)的转译,大模型产生预测的内部核心计算是依赖向量流转的。这也就意味着,基于向量的检索与大模型的默契度更高。甚至,如果可以把RAG中高频检索内容直接表达为向量,让大模型以向量为起点开始预测,我们可以直接省略在prompt上进行推理的成本。要实现这一目标,目前还需要解决的几个技术难题包括:
1. 向量表征和大模型内部状态表征对齐,让大模型可以从离线构建的向量为起点进行输出。
2. 强化向量表征的知识压缩能力,实现超长上下文的向量表达。
3. 实现多向量起点的推理,让“向量prompt”之间可以自由组合。
4. 目前近邻检索多数是基于欧氏距离进行检索,但和机器学习模型最常用的内积度量空间并不完全对齐。
综上所述,传统搜索引擎的框架,受制于对语言的理解方式以及对多模态信息的不兼容性,已经触摸到了这一范式的天花板,而表征学习以及大语言模型技术的发展,为进一步优化搜索产品体验提供的新的契机。在RAG范式下,可以对向量表示的信息进行直接检索的向量数据库重新焕发了生机。
诚然,这一范式下的技术链路依然复杂,但它已经成为搜索产业冉冉上升的新星。
向量检索服务 DashVector 免费试用进行中,玩转大模型搜索,快来试试吧~
了解更多信息,请点击:https://www.aliyun.com/product/ai/dashvector