作者:天眼查实时计算负责人,王涛
导读: 随着天眼查近年来对产品的持续深耕和迭代,用户数量也在不断攀升,业务的突破更加依赖于数据赋能,精细化的用户/客户运营也成为提升体验、促进消费的重要动力。在这样的背景下正式引入Apache Doris对数仓架构进行升级改造,实现了数据门户的统一,大大缩短了数据处理链路,数据导入速率提升75%,500万及以下人群圈选可以实现毫秒级响应,收获了公司内部数据部门、业务方的一致好评。
天眼查是中国领先的商业查询平台,以公开数据为切入点、以关系为核心的产品,帮助传统企业或个人降低成本,为防范化解金融风险方面提供了产品化的解决方案。目前已收录全国3亿多家社会实体信息,300多种维度信息及时更新,致力于构建商业安全,从而实现“公平看清世界”。
业务背景
天眼查的数据仓库主要服务于三个业务场景,每个场景都有其特点和需求,具体如下:
●亿级用户人群圈选:人群圈选场景中目前有100+人群包,我们需要根据SQL 条件圈选人群包,来支持人群包的交并差、人群包实时圈选和人群包更新通知下游等需求。例如:圈选出 下单未支付超过5分钟的用户,我们通过用户标签可以直观掌握用户支付状态,为运营&营销团队提供更精细化的人群管理服务,从而提高转化率。
●多元活动支撑的精准营销:该场景目前支持了1000 多个指标,可支持即席查询,根据活动效果及时调整运营策略。例如在“开工季”活动中,需要为数据分析&运营团队提供数据支持,从而生成可视化的活动驾驶舱。
●高并发的 C 端分析数据:该场景承载了3亿+实体(多种维度)的数据体量,同时要求实时更新,以供用户进行数据分析。
原有架构及痛点
为满足各业务场景提出的需求,我们开始搭建第一代数据仓库,即原有数仓:
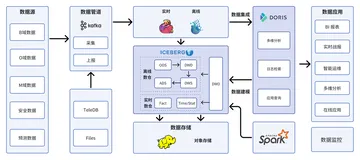
 在原有数仓架构中, Hive 作为数据计算层,MySQL、ES、PG 作为数据存储层,我们简单介绍一下架构的运行原理:
在原有数仓架构中, Hive 作为数据计算层,MySQL、ES、PG 作为数据存储层,我们简单介绍一下架构的运行原理:
●数据源层和数据接入层: MySQL 通过 Canal 将 BinLog 接入 Kafka、埋点日志通过 Flume 接入Kafka,最后由 DataX把 Kafka 中的数据接入数据计算层 Hive 中;
●数据计算层:该层使用 Hive 中的传统的数仓模型,并利用海豚调度使数据通过 ODS->DWD->DWS 分层,最后通过 DataX 将 T+1 把数据导入到数据存储层的MySQL 和 ES 中。
●数据存储层:MySQL 主要为 DataBank、Tableau、C 端提供分析数据,ES 用于存储用户画像数据, PG 用于人群包的存储 (PG 安装的插件具有Bitmap 交并差功能),ES、PG 两者均服务于DMP 人群圈选系统。
问题与挑战
依托于原有架构的投入使用,初步解决了业务方的需求,但随着天眼查近年来对产品的持续深耕和迭代,用户数量也在不断攀升,业务的突破更加依赖于数据赋能。精细化的用户/客户运营也成为提升体验、促进消费的重要动力。在这样的背景下,原有架构的缺点逐渐暴露:
●开发流程冗长:体现在数据处理链路上,比如当面对一个简单的开发需求,需要先拉取数据,再经过 Hive 计算,然后通过T+1 更新导入数据等,数据处理链路较长且复杂,非常影响开发效率。
●不支持即席查询:体现在报表服务和人群圈选场景中,所用的指标无法根据条件直接查询,必须提前进行定义和开发。
●T+1 更新延迟高: T+1 数据时效性已经无法提供精确的线索,主要体现在报表和人群圈选场景上。
●运维难度高:原有架构具有多条数据处理链路、多组件耦合的特点,运维和管理难度很高。
理想架构
基于以上问题,我们决定对架构进行升级改进,在正式升级之前,我们希望未来的架构可以做到以下几点:
●原架构涉及 MySQL、PG、ES 等多个组件,并为不同应用提供服务;我们希望未来的架构可以兼容 MySQL 协议,实现低成本替换、无缝衔接以上组件。
●支持即席查询且性能优异,即席查询能够给业务方提供更灵活的表达方式,业务方可以从多个角度、多个维度对数据进行查询和分析,更好地发现数据的规律和趋势,帮助业务方更精准备地做出决策。
●支持实时聚合,以减轻开发负担并保证计算结果的准确性。
●统一数据出口,原架构中数据出口不唯一,我们希望未来的架构能更统一数据出口,缩短链路维护成本,提升数据的可复用性。
●支持高并发, C 端的实时分析数据需要较高的并发能力,我们希望未来的架构可以高并发性能优异。
技术选型
考虑到和需求的匹配度,我们重点对 OLAP 引擎进行了调研,并快速定位到ClickHouse 和Apache Doris 这两款产品,在深入调研中发现Doris在以下几个方面优势明显,更符合我们的诉求:
●标准 SQL:ClickHouse 对标准 SQL支持有限,使用中需要对多表Join语法进行改写;而Doris兼容MySQL 协议,支持标准SQL, 可以直接运行,同时 Doris的 Join性能远优于ClickHouse.
●降本增效:Doris 部署简单,只有 FE 和 BE 两个组件,不依赖其他系统;生态内导数功能较为完备,可根据数据源/数据格式选择导入方式;还可以直接使用命令行操作弹性伸缩,无需额外投入人力;运维简单,问题排查难度低。相比之下,ClickHouse 需要投入较多的开发人力来实现类似的功能,使用难度高;同时ClickHouse 运维难度很高,需要研发一个运维系统来支持处理大部分的日常运维工作。
●并发能力: ClickHouse 的并发能力较弱是一个潜在风险,而Doris 并发能力更占优势,并且刚刚发布的2.0 版本支持了更高并发的点查。
●导入事务: ClickHouse 的数据导入没有事务支持,无法实现 Exactly Once 语义,如导数失败需要删除重导,流程比较复杂;而 Doris 导入数据支持事务,可以保证一批次内的数据原子生效,不会出现部分数据写入的情况,降低了判断的成本。
●丰富的使用场景: ClickHouse 支持场景单一,Doris 支持场景更加丰富,用户基于Doris 可以构建用户行为分析、AB 实验平台、日志检索分析、用户画像分析、订单分析等应用。
●丰富的数据模型:Doris 提供了Unique、Duplicate、Aggregate 三种数据模型,可以针对不同场景灵活应用不同的数据模型。
●社区响应速度快: Doris 社区的响应速度是其独有特色, SelectDB 为社区组建了一直完备的社区支持团队,社区的快速响应让我们少走了很多歪路,帮助我们解决了许多问题。
更多精彩内容,欢迎观看:
带你读《Apache Doris 案例集》——08秒级数据写入,毫秒查询响应 天眼查基于 Apache Doris 构建统一实时数仓(2):https://developer.aliyun.com/article/1405689