
递归
前言
递归的思想如其名就是递和归,一步一步展开,最后在合回去,从而解决问题,通过每次递归不断改变一定的数据,将大问题转化成一个一个和大问题相似的小问题来求解,只需要简短的程序,一步一步完成某个工作。
举一个生活中的例子
校长想要知道疫情返校人数,他可以一个一个寝室挨个查,也可以动用院长辅导员等人帮忙统计
递归就是如此

要学会递归,就要深刻了解递归的思想和方法,最重要的是他的逻辑性。
- 首先你要了解写出这个递归函数到底是用来做什么的,这是递归函数的第一要素,递归函数短小精悍,但一定要明确知道自己的需求。
- 在递归的过程中会有前进段和返回段,满足一定的条件就进行前进,如果不满足则return返回,不能死递归下去,不然就会爆栈,这就是递归的第二要素。
- 在明确需求后,找出函数的等价关系式,这是递归的第三要素,会在后边的学习中进行说明。
以下两道题帮助理解,精彩还在后边。
求n的阶乘
int factorial(int n) { if(n <= 1) return 1; else return n * factorial(n-1); }
给这个函数传入参数,如果小于等于1,就返回1,假使传入的值为5,运行时return结果为nfactorical(4),这个函数的返回值重新开辟了一个函数,传入值为4,这样一直递归,直至传入结果为1,当一个函数返回时,会回到之前进入函数的位置,然后在n=2的函数中继续return,直至函数结束。
通过不断地传递,当遇到限制条件后开始归,如图所示
这个函数的作用是求n的阶乘,所以函数f(n)的等价关系式是nf(n-1),在后边的函数中也都一样,改变的是n的值。
求第n个斐波那契数递归解法

int fib(int n) { if (n <= 2) return 1; else return fib(n - 1) + fib(n - 2); }
注意:前两个数的结果为1,后边的数都是前两个相加,函数结束的标志是n<=2,函数的功能是实现找到第n个斐波那契数,要知道第n个斐波那契数,就要知道第n-1个斐波那契数和第n-2个斐波那契数,要知道第n-1个斐波那契数,就要知道第n-2和第n-3个斐波那契数,一直递归下来,可以看到,在求第n个斐波那契数时,第n-2个斐波那契数被求了两次,第n-3个斐波那契数被求了3次,如果n非常大的话,利用递归来查找结果,会多余计算很多次。
我们可以来实验一下
#include <stdio.h> #include <stdlib.h> int count = 0;//全局变量 int fib(int n) { if (n == 3) count++; if (n <= 2) return 1; else return fib(n - 1) + fib(n - 2); } int main() { fib(10); printf("%d", count); return 0; }
运行后如图

传入10时,仅仅是3的斐波那契数就进行了21次,如果传入的值再大一点呢?
这个时候使用递归的弊端就显示出来了,虽然代码原理浅显易懂,但有些情况下要进行的运算太多了。

传入50跑了许久都跑不出来。如果数据再大一点的话,会一直开辟栈空间,知道栈空间被耗尽,造成栈溢出。
这道题告诉我们虽然递归逻辑清晰,代码块小,但某种情况下我们还是利用非递归的方式来写。
思路:第三个数是1+1,第四个数是2+1,只要保存更新两个相加数即可。
int fib(int n) { int ret=1,pre=1;//结果 int older_ret;//第一个加数 while (n > 2) { n -= 1; older_ret = pre; pre = ret;//上一次的结果赋值 ret = pre + older_ret; } return ret; }
总结:
1. 许多问题是以递归的形式进行解释的,这只是因为它比非递归的形式更为清晰。
2. 但是这些问题的迭代实现往往比递归实现效率更高,虽然代码的可读性稍微差些。
3. 当一个问题相当复杂,难以用迭代实现时,此时递归实现的简洁性便可以补偿它所带来的运行时开销。
但是当我们在计算二叉树相关的问题时,在遍历树的过程中递归就非常的好用。
我写了另一篇二叉树及Topk问题,详解了二叉树,感兴趣的朋友可以去看一看。
从基本讲起,随后会有几道力扣题巩固理解
前中后序遍历
二叉树有三种遍历方式
1,前序遍历 根,左,右。
2,中序遍历 左,根,右。
3,后序遍历 左,右,根。
结构体声明如下
typedef int BTDataType; typedef struct BinaryTreeNode { BTDataType data; struct BinaryTreeNode* left; struct BinaryTreeNode* right; }BTNode;
其中根为子树的根节点,左为左孩子节点,右为右节点。
前序遍历
//前序遍历 void BinaryTreePrevOrder(BTNode* root) { if (root == NULL) { return; } printf("%d ", root->data);//先访问该节点 BinaryTreePrevOrder(root->left);//再访问左子树和右子树 BinaryTreePrevOrder(root->right); }
前序遍历就是先访问根节点,然后走左节点,再走右节点,首先访问该节点,然后找他的左,判断条件为如果该节点为空,就停止递,开始归。
假设我们已经有了一个二叉树
递归展开如下:
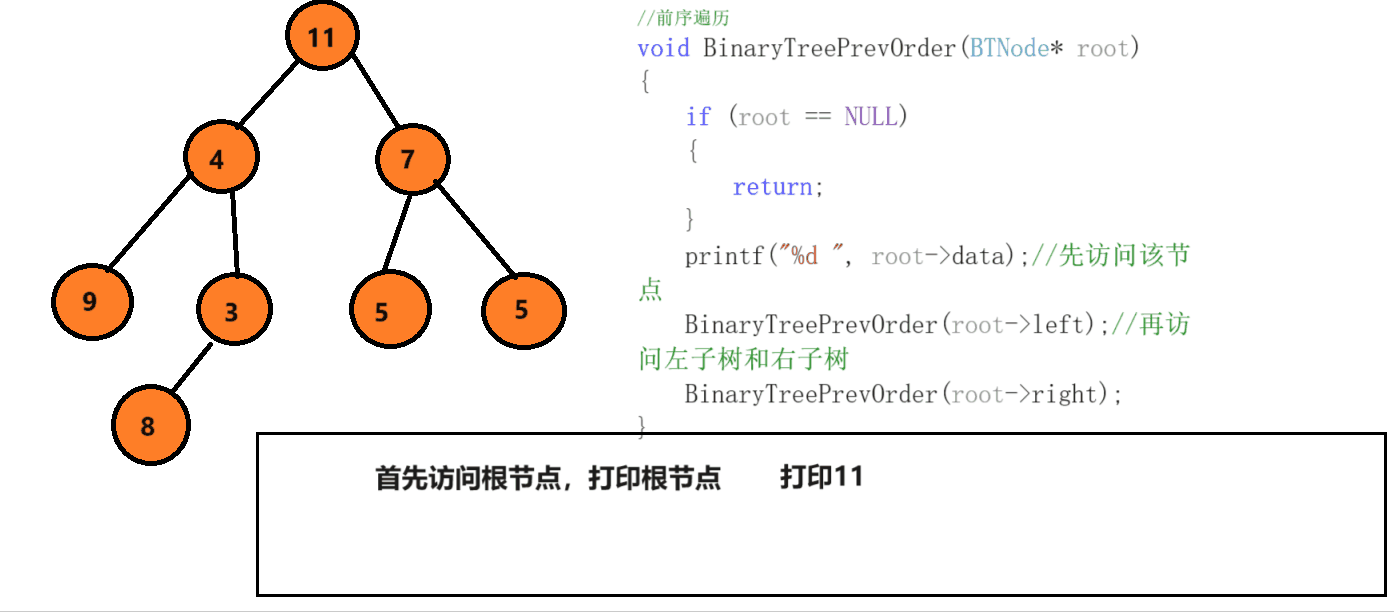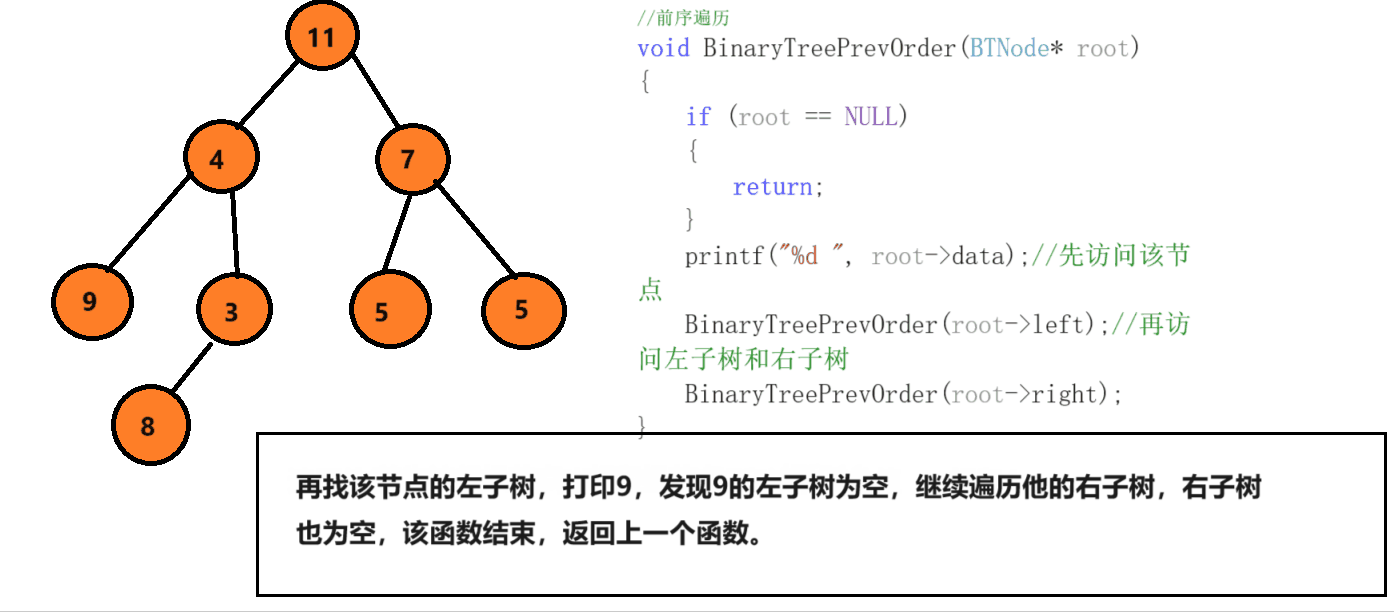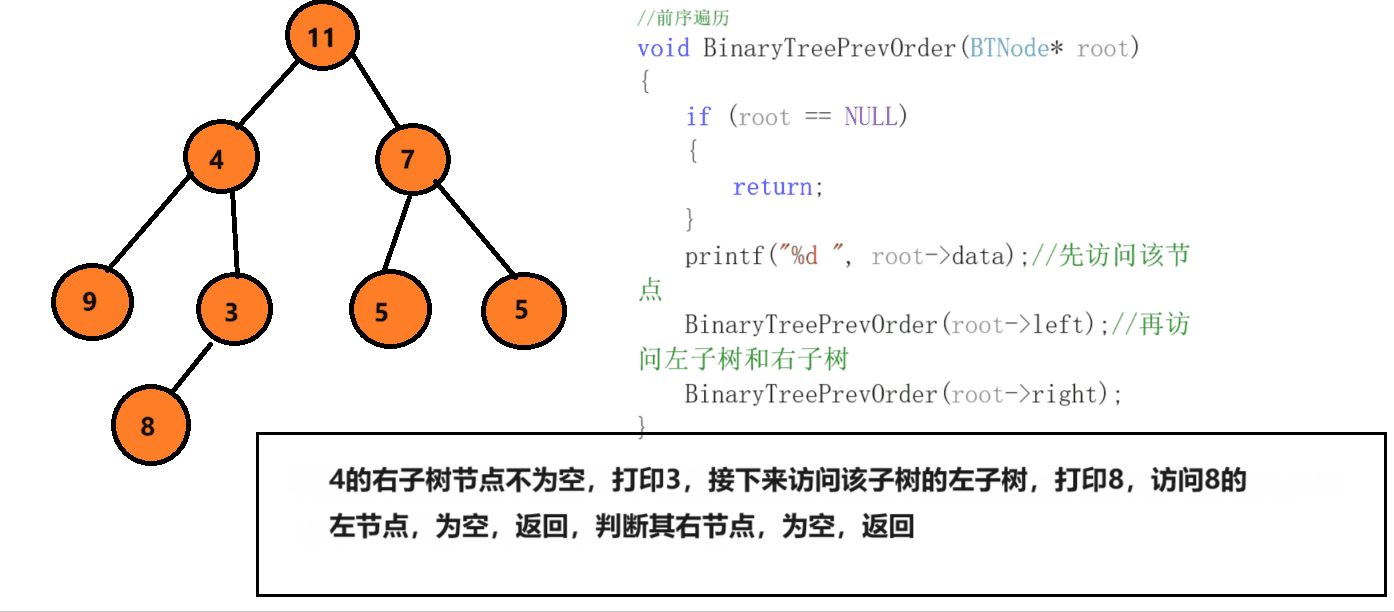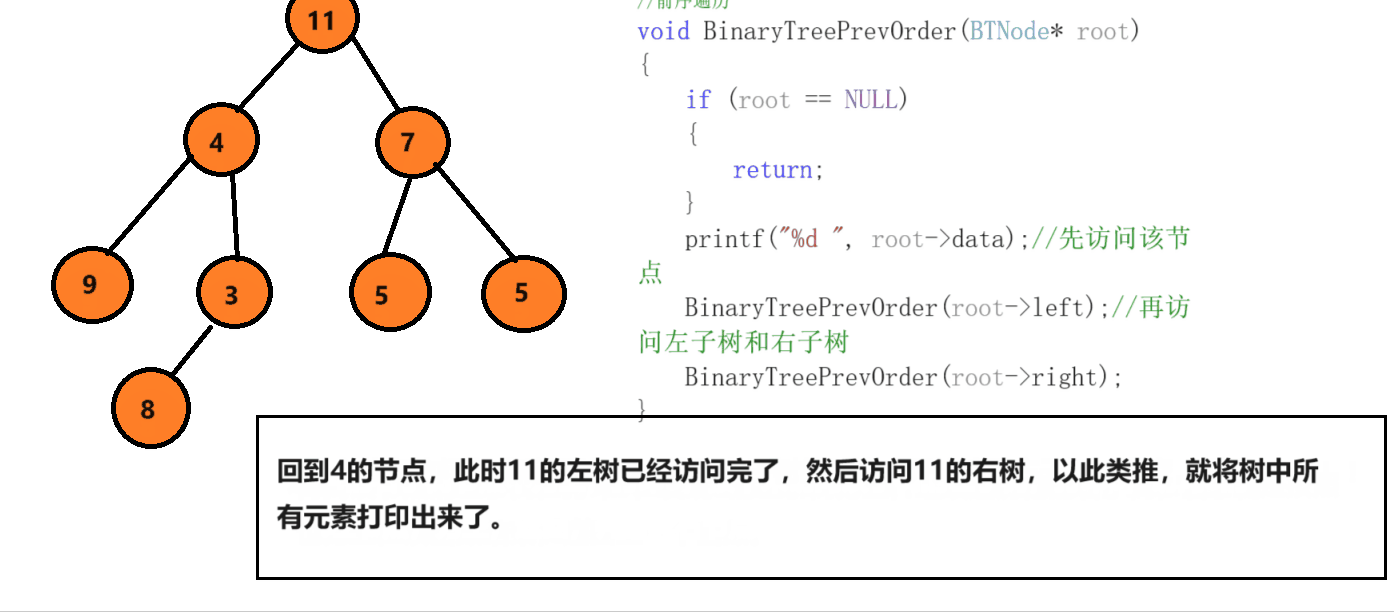
中序遍历和前序遍历相差不大
//中序遍历 void BinaryTreeInOrder(BTNode* root) { if (root == NULL) { return; } BinaryTreePrevOrder(root->left);//先访问左子树 printf("%d ", root->data);//再访问该节点 BinaryTreePrevOrder(root->right);//最后访问右子树 }
下边的问题都将利用这个二叉树来进行解释,这个树可以展现出我们会遇到的大多种情况。

递归展开图如下

上边标注了步骤及打印顺序,遇到有关递归的题目,有不懂的地方只要画一画递归展开图就会豁然开朗
同样,后序还是更改一下顺序,按照左右根的顺序来访问打印,如果想要更加清晰地建看出,可以访问空节点返回前打印一个*号。
后序代码如下
//后序遍历 void BinaryTreePostOrder(BTNode* root) { if (root == NULL) { printf("*"); return; } BinaryTreePrevOrder(root->left);//先访问左子树和右子树 BinaryTreePrevOrder(root->right); printf("%d ", root->data);//最后访问该节点 }
二叉树全局遍历问题
树的节点个数
要找树的节点个数,分析,访问全树,如果为空树就返回,如果不是空树就加1。可以找一个变量来存储这个值,但由于局部变量在一个函数是单个个体,全局变量的安全性不高,我们可以传过来一个指针变量,每当访问到非空节点就解引用加一,空节点就return。
也可以利用返回值直接返回每个函数返回的值。
代码如下
//树的节点个数 int BinaryTreeSize(BTNode* root) { if (root == NULL) { return; } return BinaryTreeSize(root->left) + BinaryTreeSize(root->right) + 1; //return root==NULL?0:BinaryTreeSize(root->left) + BinaryTreeSize(root->right) + 1;//三目操作符,前序 }
控制每个函数返回一个值,最后总和起来的就是节点的个数。归的条件是节点为空,返回的是统计的节点个数。
仍然利用上图讲解

递归展开图如下

到了这里,你是否已经开始熟悉递归的思路了。
相同类型的题目,不过要判断条件
