
笔记的主要内容是 PCA(主成分分析) 原理和基本知识,相关数学原理和核心概念。
什么是PCA分析?
主成分分析(PCA, principal component analysis)是一种数学降维方法,利用正交变换把一系列可能线性相关的变量转换为一组线性不相关的新变量也称为主成分PC,用新变量在更小的维度下展示数据的特征。下图展示了经过标准化之后数据的展示差异:

有几个问题值得思考,如果数据很复杂而且具有很多个变量,应该如何选择合适的主成分?PCA分析的优势有哪些?PCA的应用场景?


选择主成分
PCA的核心是选择新的坐标系(主成分),坐标轴垂直(也就是正交,线性无关),方差足够大(为了使数据在坐标轴的投射点尽可能的广,显示出更多数据特征)
假设有很多个不同的数据,它们在坐标系散乱分布,先确定它们中最中心的点,经过该点的一条直线和所有点平方距离最小时,即可确定主成分PC1,如下图所示过程,紫线位置。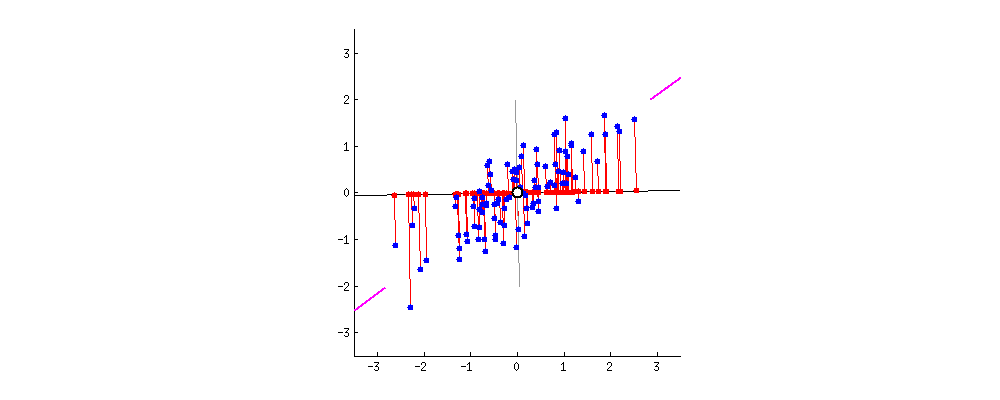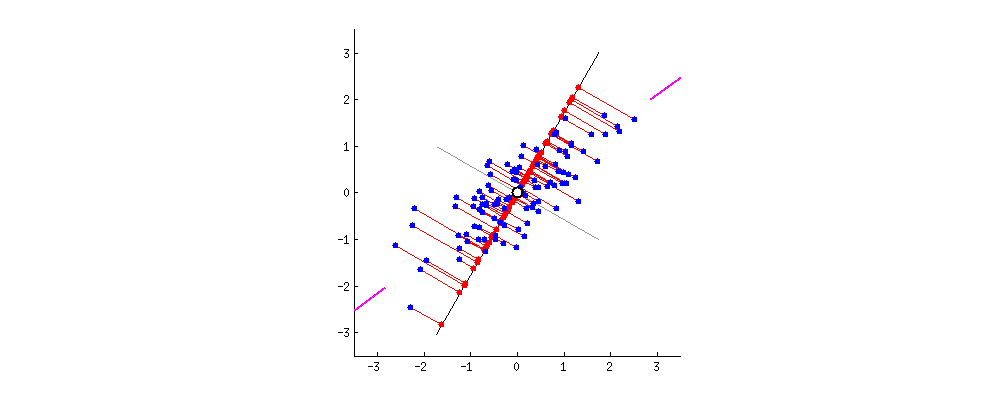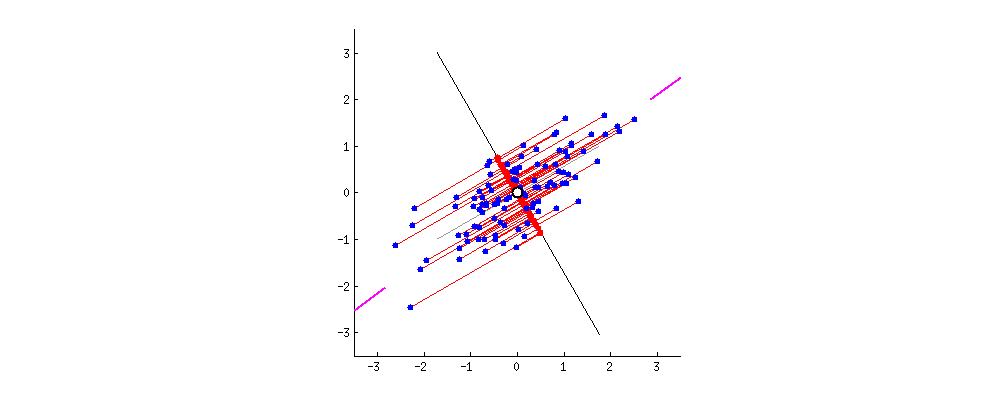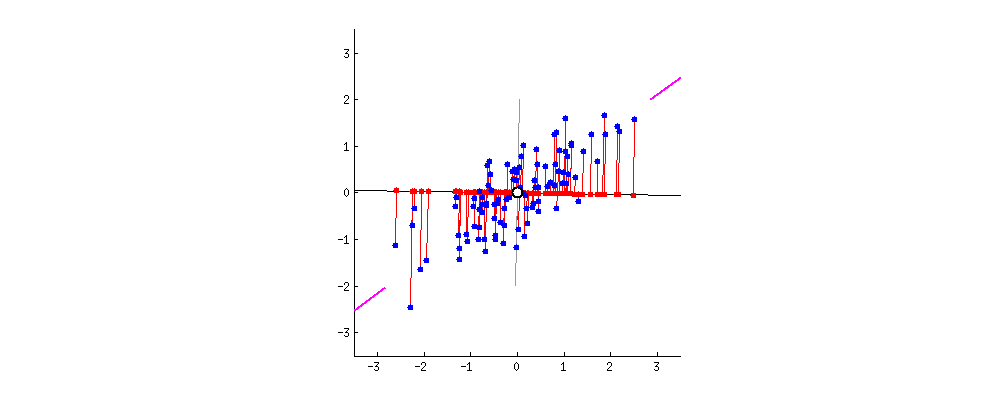 由于
由于第二主成分PC2与PC1正交(即垂直),所以根据这两条线为坐标轴,把所有的点分别投影到新的坐标轴,这样就完成了从二维到一维的转换。

投影的方式比较多,目的是尽可能的保留数据的特征,使第一主成分具有最大的方差(var)同时利用正交非线性相关性完成去冗余。

PCA分析优势
- 简化数据
数据量非常大时,比如有800份小麦重测序数据,几万个不同的基因表达量有差异,导致分析过程变的很麻烦,通过PCA分析可以确定其中最主要的变化因子,简化运算过程。

- 去除误差数值
PCA分析对数据降维处理时,过滤掉由于误差引起的变化,增大数据的可信度。

- 数据可视化
在展示多个基因表达数据时,利用PCA选择表达差异最显著的两个基因作为主成分,然后得出各个基因表达量的关系。
PCA分析应用场景
科研中经常会应用PCA分析方法,在阅读一些文献时,笔者发现PCA图频繁出现在paper中,比如研究肠道微生物的菌群构成、某种细胞的基因表达情况等。

这些场景下都具有很多变量,PCA分析通几个主成分来揭示多个变量之间的关系,且主成分间互不相关。将高维数据降低至二维或三维,同时保持各方差贡献最大的特征,降低数据复杂度。

PCA的数学原理
假如有一份原始数据包含多个变量,先将每个变量的方差和协方差计算出来,得到数据的协方差矩阵。
- 方差
var,单个变量的变异度。表示数据的离散程度 - 协方差
cov,两个变量的相关度,若为0表示没有相关性,如果为正,表示一组数据增加时另一组数据也随之增加

为了统一衡量的尺度,需要对协方差矩阵进行标准化处理(scale),通俗的说就是让数据的平均值为0并且方差为1,这样所有数据的评价标准和尺度都一样。
原始变量的协方差矩阵包含以下两部分信息:
- 原始变量自身的方差(协方差矩阵的主对角线位置)
- 原始变量之间的相关程度(非主对角线位置)
PCA分析就是产生一组新的变量,使得新变量的协方差矩阵为对角阵。
特征值法分解协方差矩阵

参考资料:
https://blog.csdn.net/weixin_60737527/article/details/125144416
https://blog.csdn.net/Monica_428/article/details/117667137
https://zhuanlan.zhihu.com/p/37777074
https://www.aisoutu.com/a/1510739
https://blog.csdn.net/weixin_39747087/article/details/112455438
http://www.ehbio.com/Bioinfo_R_course/Rplots.html#pcaintroduc
https://blog.csdn.net/weixin_39837727/article/details/110160387
http://blog.genesino.com/2016/10/PCA/
END
© 素材来源于网络,侵权请联系后台删除


往期推荐:

