
环境准备
使用vagrant准备两台虚拟机机器
配置:1C2G
服务端VM预先安装 docker、sysstat 等工具
 VM1: 运行flask应用 IP地址是 192.168.1.9;
VM1: 运行flask应用 IP地址是 192.168.1.9;
VM2: 作为客户端,请求单词的热度,IP地址是192.168.1.10
启动项目
docker run --name=app -p 10000:80 -itd feisky/word-pop
docker ps 查看

VM2终端请求

加上time看到这个接口耗费了37s,为了方便服务端VM1的终端中观察,写个死循环。
[root@node101 opt]# time curl http://192.168.1.9:10000/popularity/word { "popularity": 0.0, "word": "word" } real 0m37.753s user 0m0.004s sys 0m0.008s [root@node101 opt]# while true ;do time curl http://192.168.1.9:10000/popularity/word; sleep 1s ;done
查看Top
top看到cpu使用率大约36%。剩余内存还有80多MB,大多数内存被cache住了.
但是有iowait大约7%。虽然7% 并不能成为性能瓶颈,不过有点嫌疑——可能跟 iowait 的升高有关。
进程部分有一个 python 进程的 CPU 使用率稍微有点高。
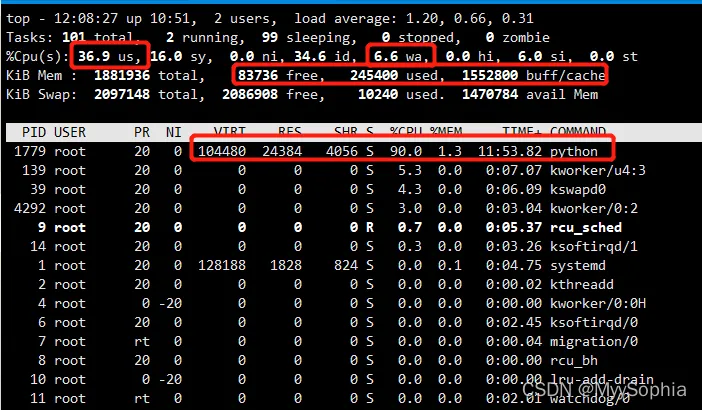 虚拟机我分配了两个cpu,在top中按1显示多个cpu
虚拟机我分配了两个cpu,在top中按1显示多个cpu
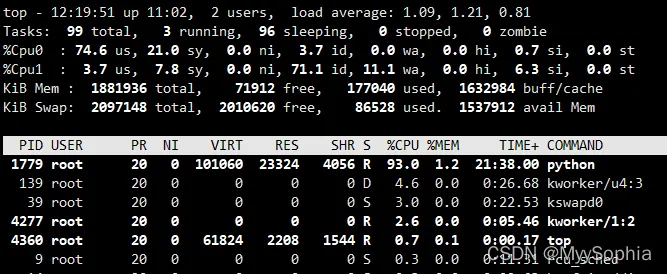
iowait高的时候cpu使用少,没有iowait的时候cpu用的多,这是不是iowait的时候压力在文件系统上而非在CPU上,暂且这么理解,如有不对之初烦请指出.
docker中 确认python进程是不是刚才启动的flask应用

手分析iowait的原因
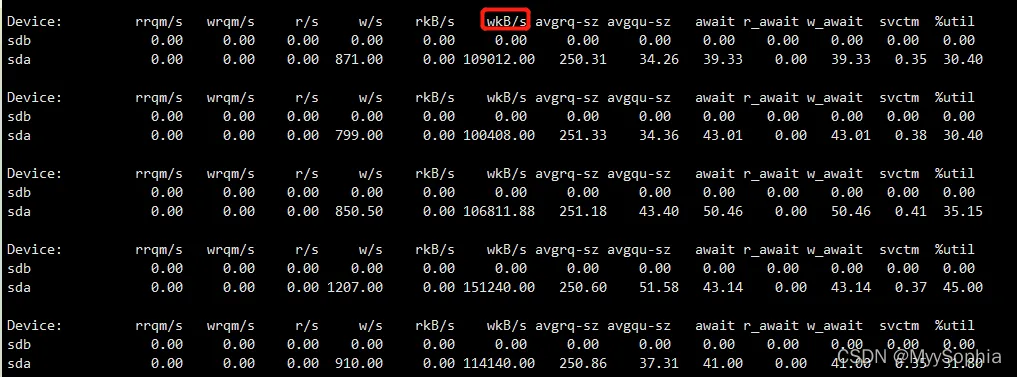
iostat -d -x 1
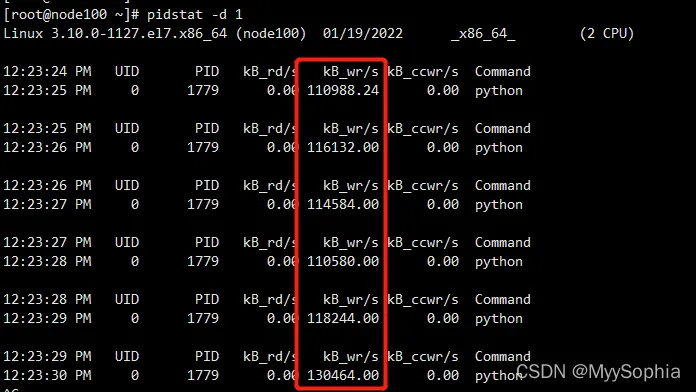
pidstat -d 1
strace定位IO相关操作
刚开始使用strace -p pid一直看不到write的系统调用。
难道此时已经没有性能问题了吗?重新执行刚才的 top 和 iostat 命令,你会不幸地发现,性能问题仍然存在。
我们只好综合 strace、pidstat 和 iostat 这三个结果来分析了。很明显,你应该发现了这里的矛盾:iostat 已经证明磁盘 I/O 有性能瓶颈,而 pidstat 也证明了,这个瓶颈是由1779号进程导致的,但 strace 跟踪这个进程,却没有找到任何 write 系统调用。这就奇怪了。难道因为案例使用的编程语言是 Python ,而 Python 是解释型的,所以找不到?还是说,因为案例运行在 Docker 中呢?
使用pstree 查看该应用时多线程应用,因此strace 的参数要使用-f

strace -f -p 1779
~]# strace -f -p 1779 strace: Process 1779 attached with 3 threads [pid 1780] restart_syscall(<... resuming interrupted read ...> <unfinished ...> [pid 1779] select(0, NULL, NULL, NULL, {tv_sec=0, tv_usec=947112} <unfinished ...> [pid 4470] read(6, "", 1) = 0 [pid 4470] mmap(NULL, 2101248, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f58a5be1000 [pid 4470] munmap(0x7f58a622d000, 2101248) = 0 [pid 4470] munmap(0x7f58a5be1000, 2101248) = 0 [pid 4470] close(6) = 0 [pid 4470] open("/tmp/ca41b630-7923-11ec-a2ee-0242ac110002/40.txt", O_RDONLY|O_CLOEXEC) = 6 [pid 4470] fcntl(6, F_SETFD, FD_CLOEXEC) = 0 [pid 4470] fstat(6, {st_mode=S_IFREG|0644, st_size=1849999, ...}) = 0 [pid 4470] ioctl(6, TIOCGWINSZ, 0x7f58a656e290) = -1 ENOTTY (Inappropriate ioctl for device) [pid 4470] lseek(6, 0, SEEK_CUR) = 0 [pid 4470] ioctl(6, TIOCGWINSZ, 0x7f58a656e1b0) = -1 ENOTTY (Inappropriate ioctl for device) [pid 4470] lseek(6, 0, SEEK_CUR) = 0 [pid 4470] fstat(6, {st_mode=S_IFREG|0644, st_size=1849999, ...}) = 0 [pid 4470] mmap(NULL, 1851392, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f58a626a000 [pid 4470] read(6, "My mom kicks the king for a dise"..., 1850000) = 1849999 [pid 4470] read(6, "", 1) = 0 [pid 4470] mmap(NULL, 1851392, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f58a5c1e000 [pid 4470] munmap(0x7f58a626a000, 1851392) = 0 [pid 4470] munmap(0x7f58a5c1e000, 1851392) = 0 [pid 4470] close(6) = 0 [pid 4470] open("/tmp/ca41b630-7923-11ec-a2ee-0242ac110002/41.txt", O_RDONLY|O_CLOEXEC) = 6 [pid 4470] fcntl(6, F_SETFD, FD_CLOEXEC) = 0 [pid 4470] fstat(6, {st_mode=S_IFREG|0644, st_size=2249999, ...}) = 0 [pid 4470] ioctl(6, TIOCGWINSZ, 0x7f58a656e290) = -1 ENOTTY (Inappropriate ioctl for device) [pid 4470] lseek(6, 0, SEEK_CUR) = 0 [pid 4470] ioctl(6, TIOCGWINSZ, 0x7f58a656e1b0) = -1 ENOTTY (Inappropriate ioctl for device) [pid 4470] lseek(6, 0, SEEK_CUR) = 0 [pid 4470] fstat(6, {st_mode=S_IFREG|0644, st_size=2249999, ...}) = 0 [pid 4470] mmap(NULL, 2252800, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f58a6208000 [pid 4470] read(6, "A cat with rabies eats a dude fo"..., 2250000) = 2249999 [pid 4470] read(6, "", 1) = 0 [pid 4470] mmap(NULL, 2252800, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f58a5bbc000 [pid 4470] munmap(0x7f58a6208000, 2252800) = 0 [pid 4470] munmap(0x7f58a5bbc000, 2252800) = 0 [pid 4470] close(6) = 0
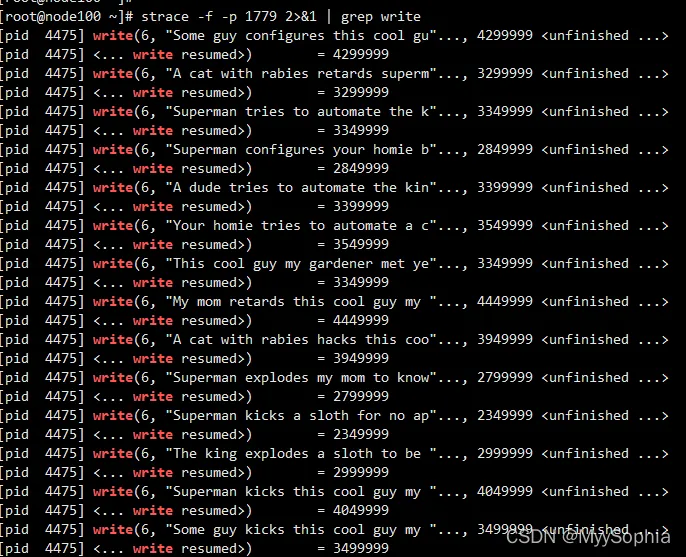
 只看write相关系统调用
只看write相关系统调用
lsof 定位进程打开的文件
根据strace的write系统调用,定位到write的是fd6, 使用lsof定位到具体对应哪个文件。(如果不是一直写,则很难捕捉到这个fd,多试几次)
[root@node100 ~]# [root@node100 ~]# lsof -p 1779 python 1779 root 0u CHR 136,0 0t0 3 /dev/pts/0 python 1779 root 1u CHR 136,0 0t0 3 /dev/pts/0 python 1779 root 2u CHR 136,0 0t0 3 /dev/pts/0 python 1779 root 3u sock 0,7 0t0 26793 protocol: TCP python 1779 root 4u sock 0,7 0t0 26793 protocol: TCP python 1779 root 5u sock 0,7 0t0 124761 protocol: TCP python 1779 root 6r REG 0,38 2049999 34123804 /tmp/44239a22-7924-11ec-a2ee-0242ac110002/913.txt
分析源代码
flask热词统计
#!/usr/bin/env python # -*- coding: UTF-8 -*- import os import uuid import random import shutil from concurrent.futures import ThreadPoolExecutor from flask import Flask, jsonify app = Flask(__name__) def validate(word, sentence): return word in sentence def generate_article(): s_nouns = [ "A dude", "My mom", "The king", "Some guy", "A cat with rabies", "A sloth", "Your homie", "This cool guy my gardener met yesterday", "Superman" ] p_nouns = [ "These dudes", "Both of my moms", "All the kings of the world", "Some guys", "All of a cattery's cats", "The multitude of sloths living under your bed", "Your homies", "Like, these, like, all these people", "Supermen" ] s_verbs = [ "eats", "kicks", "gives", "treats", "meets with", "creates", "hacks", "configures", "spies on", "retards", "meows on", "flees from", "tries to automate", "explodes" ] infinitives = [ "to make a pie.", "for no apparent reason.", "because the sky is green.", "for a disease.", "to be able to make toast explode.", "to know more about archeology." ] sentence = '{} {} {} {}'.format( random.choice(s_nouns), random.choice(s_verbs), random.choice(s_nouns).lower() or random.choice(p_nouns).lower(), random.choice(infinitives)) return '\n'.join([sentence for i in range(50000)]) @app.route('/') def hello_world(): return 'hello world' @app.route("/popularity/<word>") def word_popularity(word): dir_path = '/tmp/{}'.format(uuid.uuid1()) count = 0 sample_size = 1000 def save_to_file(file_name, content): with open(file_name, 'w') as f: f.write(content) try: # initial directory firstly os.mkdir(dir_path) # save article to files for i in range(sample_size): file_name = '{}/{}.txt'.format(dir_path, i) article = generate_article() save_to_file(file_name, article) # count word popularity for root, dirs, files in os.walk(dir_path): for file_name in files: with open('{}/{}'.format(dir_path, file_name)) as f: if validate(word, f.read()): count += 1 finally: # clean files shutil.rmtree(dir_path, ignore_errors=True) return jsonify({'popularity': count / sample_size * 100, 'word': word}) @app.route("/popular/<word>") def word_popular(word): count = 0 sample_size = 1000 articles = [] try: for i in range(sample_size): articles.append(generate_article()) for article in articles: if validate(word, article): count += 1 finally: pass return jsonify({'popularity': count / sample_size * 100, 'word': word}) if __name__ == '__main__': app.run(debug=True, host='0.0.0.0', port=80)
要取得该文件夹下的所有文件,可以使用for (root, dirs, files) in walk(roots)函数
| roots | 代表需要遍历的根文件夹 |
| root | 表示正在遍历的文件夹的名字(根/子) |
| dirs | 记录正在遍历的文件夹下的子文件夹集合 |
| files | 记录正在遍历的文件夹中的文件集合 |
源码中可以看到,这个案例应用,在每个请求的处理过程中,都会生成一批临时文件,然后读入内存处理,最后再把整个目录删除掉。这是一种常见的利用磁盘空间处理大量数据的技巧,不过,本次案例中的 I/O 请求太重,导致磁盘 I/O 利用率过高。
要解决这一点,其实就是算法优化问题了。比如在内存充足时,就可以把所有数据都放到内存中处理,这样就能避免 I/O 的性能问题。
源码中把article放在数组中,也就是内存中处理。不知道是何原因?我本地测试竟然放入内存处理却更加耗时。
可能是样本量的问题,不过这种思路是值得学习的.
[root@node101 opt]# time curl http://192.168.1.9:10000/popularity/reason { "popularity": 16.900000000000002, "word": "reason" } real 0m38.276s user 0m0.011s sys 0m0.009s [root@node101 opt]# time curl http://192.168.1.9:10000/popular/reason { "popularity": 15.5, "word": "reason" } real 1m11.180s user 0m0.007s sys 0m0.010s




