
经过长达大半年时间的崩溃治理后,基于 Electron 框架开发的新版 PC 淘宝直播推流客户端的稳定性终于赶超基于QT 框架开发的旧版本了。剩下的崩溃问题中有 40% 是跟内存 OOM 有关,其中 V8FatalErrorCallback js heap OOM 问题整整困扰了我一个多月。历经千辛万苦终于破案并解决了这个问题,作为技术人来说还是非常兴奋的。为了了解该问题的来龙去脉,本文会从 V8FatalErrorCallback 崩溃问题的堆栈分析开始讲起,然后通过堆栈信息尝试各种解决方案,并对 v8 堆内存进行源码分析和尝试编译 electron 源码提升 v8 堆内存上限都不奏效后(如果对于编译 electron 源码不感兴趣,可以直接跳到 “如何用 Memory 和 Performance 工具分析内存泄漏问题“章节查看最终解决问题的方案),最终借助 chrome devtools 提供的 Memory 和 Performance 工具一步步排查和解决 Electron v8 引发的内存 OOM 问题,并且触类旁通解决其他内存 OOM 问题。

背景
▐ 为啥会上报 V8FatalErrorCallback 崩溃问题
让我们先来看下 V8FatalErrorCallback 崩溃上报的堆栈信息:

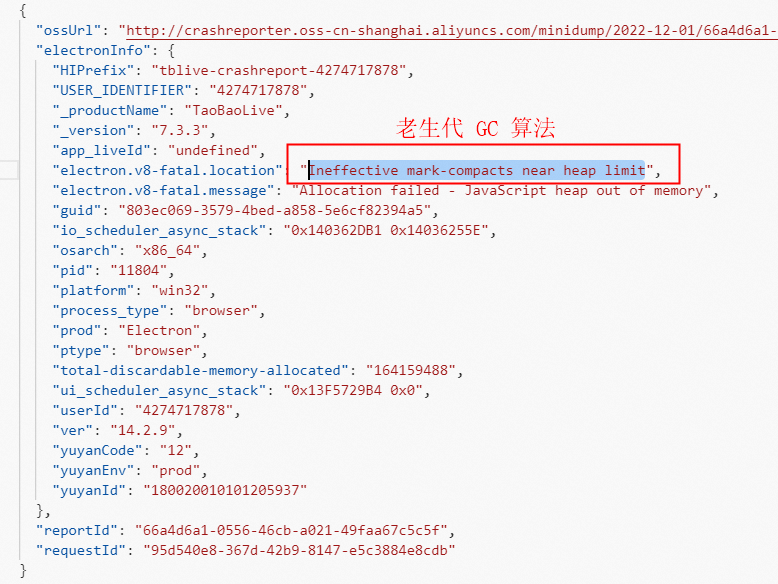
从上面的堆栈信息可以得知,由于 v8 执行老生代 GC 算法时 JaveScript heap out of memory 导致触发了 V8FatalErrorCallback 的崩溃上报。
既然是 v8 heap 堆内存 GC 后仍然无法回收空间导致 OOM,那会不会是缓存一直增长造成的?顺着这个思路发现在 Node.js 的 vm 中编译一段脚本时,最终依赖的对象叫 UnboundScript。在编译过程中,会逐步调用到下面的代码:
CompilationCache* compilation_cache = isolate->compilation_cache(); // 从 Compilation Cache 中查找是否命中maybe_result = compilation_cache->LookupScript( source, script_details.name_obj, script_details.line_offset, script_details.column_offset, origin_options, isolate->native_context(), language_mode); if (!maybe_result.is_null()) { // 若命中,则标记命中 compile_timer.set_hit_isolate_cache();} else if (can_consume_code_cache) { // 反序列化 if (CodeSerializer::Deserialize(isolate, cached_data, source, origin_options).ToHandle(&inner_result) && inner_result->is_compiled()) { // 将反序列化后的内容加入 Compilation Cache compilation_cache->PutScript(source, isolate->native_context(), language_mode, inner_result); }}
大致意思是用源码去检索 Compilation Cache 中是否存在相同 key 的对象,若存在则直接返回已经存在的缓存,否则以源码字符串作为 key 将结果储存在 Compilation Cache 中(v8 分配的堆内存上)。
使用 Compilation Cache 的好处是可以加快脚本的编译速度,但副作用是该 Compilation Cache 只有在 CollectAllAvailableGarbage 时才会被回收,而正常的 GC 并不会回收该 Cache,导致 v8 堆内存一直上涨。当Node.js 14 / 16 对应的 v8 在堆内存抵达上限后,GC 时就会触发 V8FatalErrorCallback OOM 的“Bug”。
▐ 尝试解决 V8FatalErrorCallback 崩溃问题
若要解决该问题可通过设置 --no-compilation-cache 关闭 Compilation Cache,但如此一来则无法享受 Compilation Cache。经过权衡之后,我们把主进程的 require('v8-compile-cache') 代码去掉,并且设置如下命令关闭 Compilation Cache,然后高高兴兴地发了个修复版本。
app.commandLine.appendSwitch('js-flags', '--no-compilation-cache')
过两天一看,怎么还是有一堆 V8FatalErrorCallback 崩溃问题上报?通过进一步分析崩溃堆栈信息发现,除了 v8 老生代堆内存 OOM 外,还有下面两类 v8 新生代堆内存 OOM 问题:
- v8 新生代内存申请时报 “young object promotion failed”导致 OOM 崩溃
- v8 新生代内存申请时报 “reach heap limit”导致 OOM 崩溃

于是尝试将 v8 新生代内存最大值从默认的 16M 提高到 64M(从默认的 16M 设置到 64M 时,Node 应用的整体 GC 性能是有显著提升的,并且反映到压测 QPS 上大约提升了 10%。但是进一步将 Semi space 增大到 128M 和 256M 时,收益确并不明显。而且 Semi space 本身也是作用于新生代对象快速内存分配,本身不宜设置的过大,因此这次优化最终选取最优运行时 Semi space 的值为 64M),对应设置如下,然后抱着试一试的心态再次发了个修复版本。
app.commandLine.appendSwitch('js-flags', '--max-semi-space-size=64')
果不其然,这次发版并没有彻底修复问题。那还有什么解决方案呢?绞劲脑汁想了半天,还是毫无头绪,看来只能通过提升 v8 堆内存上限来延缓 V8FatalErrorCallback 崩溃问题了,对应设置如下:
app.commandLine.appendSwitch('js-flags', '--max-old-space-size=8192')
但没想到这种设置也有坑,设置后死活不生效,v8 还是默认的 4G 堆内存上限。没办法,只能硬着头皮查看 v8 源码分析下堆内存限制的原理。
▐ 通过 v8 源码分析堆内存限制原理
接下来我们通过 v8 源码一步步分析堆内存限制的实现原理,代码逻辑图如下所示:

- 首先打开 src\third_party\blink\renderer\core\timing\memory_info.h 文件,看注释里得知 performance.memory 方法也是从这里获取的 v8 堆内存信息,包括 jsHeapSizeLimit 方法获取的 info.js_heap_size_limit 变量值就是 v8 堆内存上限。

- 然后打开 src\third_party\blink\renderer\core\timing\memory_info.cc 文件,发现是从 heap_statistics 的 heap_size_limit 方法获取的值赋值给 info.js_heap_size_limit 变量。
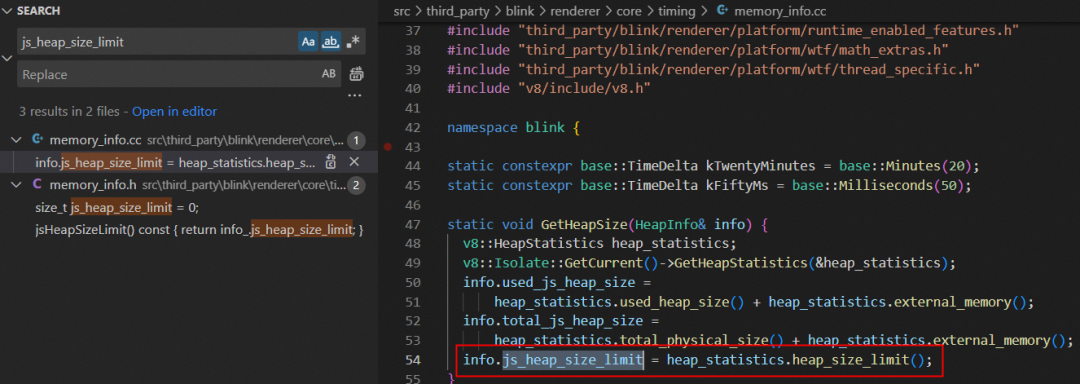
- 接着打开 src\third_party\electron_node\deps\v8\include\v8.h 文件,发现 heap_size_limit 方法返回的是 heap_size_limit_ 变量值。
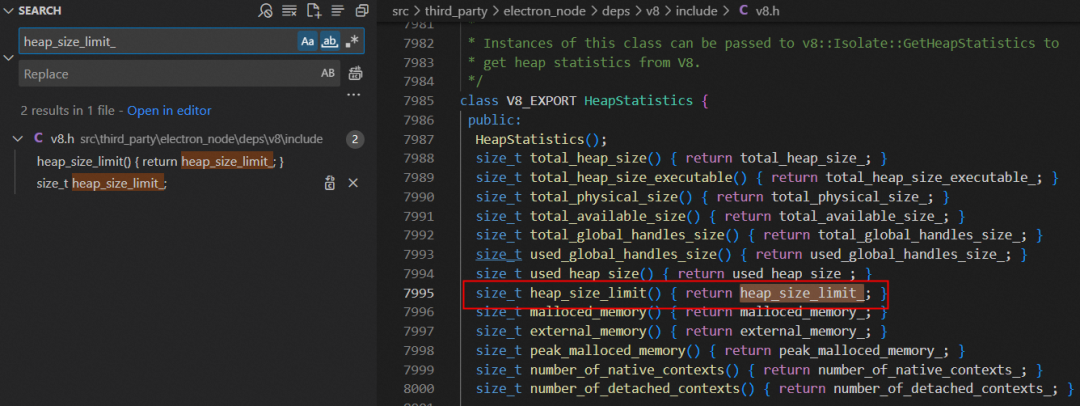
- 紧接着打开 src\third_party\electron_node\deps\v8\src\api\api.cc 文件,发现是从 heap 的 MaxReserved 方法获取的值赋值给 heap_size_limit_ 变量。
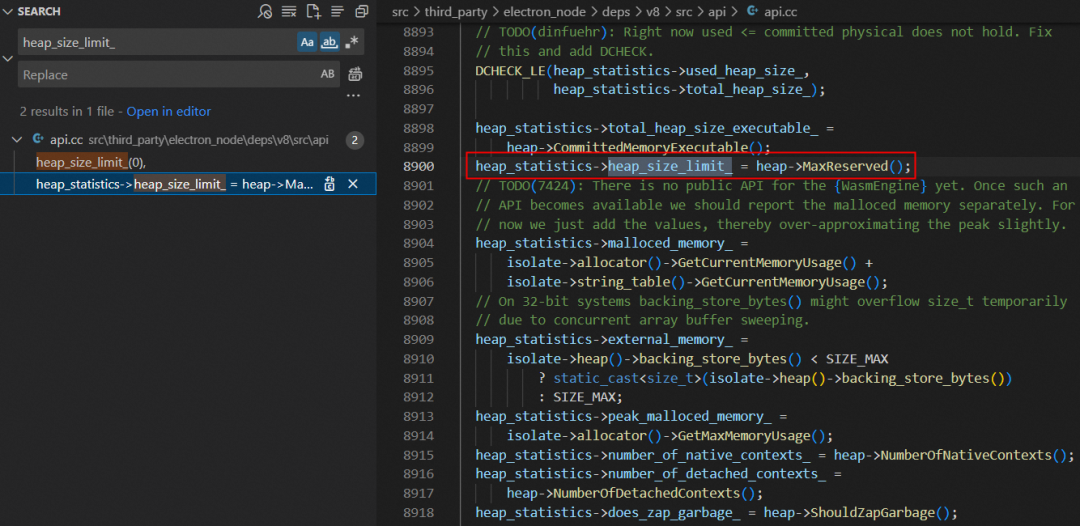
- 继续打开 src\third_party\electron_node\deps\v8\src\heap\heap.cc 文件,终于在 MaxReserved 方法找到详细的实现逻辑了。从下面的代码逻辑可以得知,v8 堆内存上限就等于 3 * max_semi_space_size_ + max_old_generation_size_。


- 最后我们在 src\third_party\electron_node\deps\v8\src\heap\heap.cc 文件的 ConfigureHeap 方法里找到了初始化 max_semi_space_size_ 和 max_old_generation_size_ 这两个变量的逻辑:
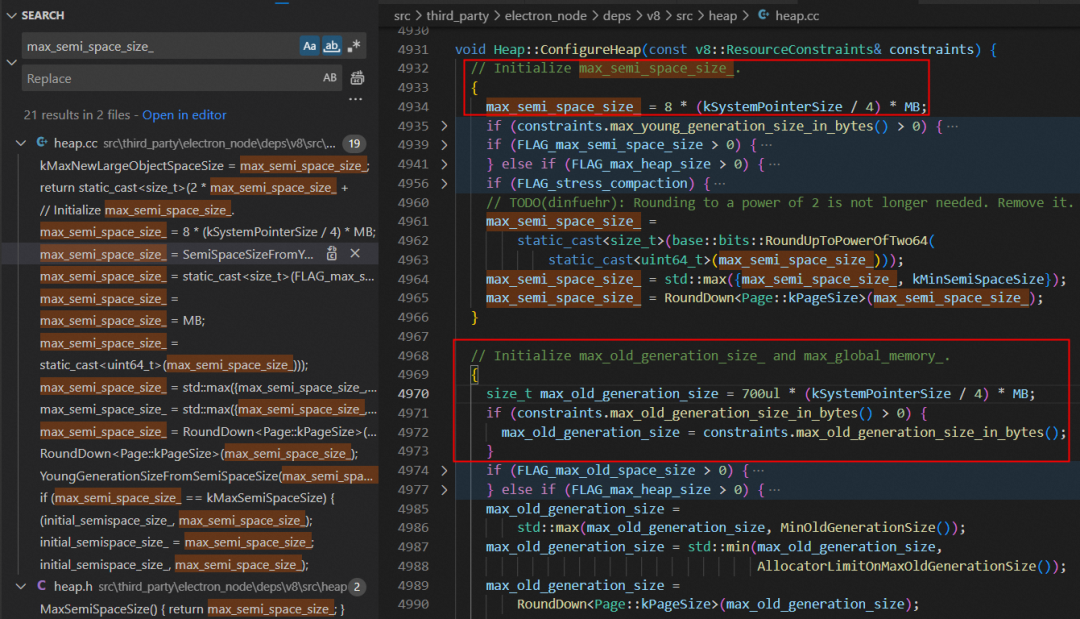
max_semi_space_size_
其中 kSystemPointerSize 等于 sizeof(void*),在 32 位系统是 4 个字节,64 位系统是 8 个字节。也就是说,默认情况下 max_semi_space_size_ 的初始值就是 8MB(32 位)/ 16MB(64 位)。
constexpr int kSystemPointerSize = sizeof(void*);max_semi_space_size_ = 8 * (kSystemPointerSize / 4) * MB;
当然,我们也可以通过下面的指令重设 max_semi_space_size_ 的值。
app.commandLine.appendSwitch('js-flags', '--max-semi-space-size=xxx')
max_old_generation_size_
同理,默认情况下 max_old_generation_size_ 的初始值是 700MB(32 位)/ 1400MB(64 位)。
constexpr int kSystemPointerSize = sizeof(void*);size_t max_old_generation_size = 700ul * (kSystemPointerSize / 4) * MB;
如果这两个变量都按默认值来算的话,32 位系统下 v8 堆内存上限等于 724M(3 * 8M + 700M),64 位系统下 v8 堆内存上限等于 1448M(3 * 16M + 1400M)。但为啥我的 64 位电脑系统下 v8 堆内存上限有 4096M(heapSizeLimit 字段对应的值) 呢?
{ totalHeapSize: 26332, totalHeapSizeExecutable: 768, totalPhysicalSize: 26332, totalAvailableSize: 4174396, usedHeapSize: 19029, heapSizeLimit: 4194048, mallocedMemory: 512, peakMallocedMemory: 9096, doesZapGarbage: false}
这是因为我们刚刚看的计算逻辑只是默认情况下的初始值,实际上现在的 v8 还会根据设备的性能来设置限制,所以我们需要针对这个再往下深挖,先看下面这段代码逻辑:
if (constraints.max_old_generation_size_in_bytes() > 0) { max_old_generation_size = constraints.max_old_generation_size_in_bytes();}

其中 max_old_generation_size_in_bytes 只是获取 max_old_generation_size_ 的 getter 方法,我们需要看具体是哪里调用 set_max_old_generation_size_in_bytes 这个 setter 方法设置该值的。
/** * The maximum size of the old generation. * When the old generation approaches this limit, V8 will perform series of * garbage collections and invoke the NearHeapLimitCallback. * If the garbage collections do not help and the callback does not * increase the limit, then V8 will crash with V8::FatalProcessOutOfMemory. */// gettersize_t max_old_generation_size_in_bytes() const { return max_old_generation_size_;}// settervoid set_max_old_generation_size_in_bytes(size_t limit) { max_old_generation_size_ = limit;}
细查可见是在 src\third_party\electron_node\deps\v8\src\api\api.cc 文件里 ConfigureDefaults 方法调用 set_max_old_generation_size_in_bytes,然后传入 old_generation 变量值进行赋值的。而跟该变量值相关的 GenerationSizesFromHeapSize 只是个简单的二分查找,先将 old_generation 设置为 heap_size 的一半,然后计算 young_generation 的值,看二者加起来是否大于 heap_size,若大于则再将 old_generation 减半,以此再迭代。可以看出,核心还是要看 heap_size 是如何计算的。

继续看 HeapSizeFromPhysicalMemory 方法里 heap_size 的计算实现逻辑,原来 old_generation 取的是物理内存通过系数计算出来的值(如电脑物理内存为 16G,则计算得到的值为 8G)和 v8 的最大内存限制(如电脑物理内存为 16G,则计算得到的值为 4G)二者中的最小值。
其中 MaxOldGenerationSize 方法中定义了 v8 的最大老生代的限制,如果按照我的 64 位电脑物理内存 16G 配置的话,则计算得出 old_generation 为 4096M,最终这个值就是 v8 堆内存上限,跟前面 heapSizeLimit 字段值可以对上。
static constexpr size_t kPhysicalMemoryToOldGenerationRatio = 4;static const int kHeapLimitMultiplier = kSystemPointerSize / 4;static constexpr size_t kMaxSize = 1024u * Heap::kHeapLimitMultiplier * MB;

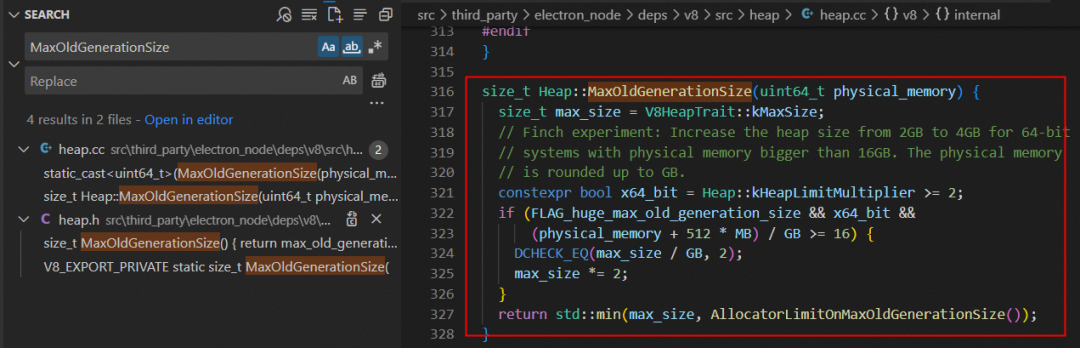
经过上面的源码分析后,电脑物理内存 16G 配置的话 v8 堆内存上限确实只有 4G,主要还是因为 v8 的 v9.2 版本默认使用了指针压缩导致。
那要怎么突破 v8 堆内存上限呢?办法总归是有的,请继续阅读下文。
更多精彩内容,欢迎观看:
如何排查 Electron V8 引发的内存 OOM 问题(中):https://developer.aliyun.com/article/1263249?groupCode=taobaotech
