
实时监听一个文件末尾产生的数据
有时我们会产生需求实时的监控一个文件的数据,一般来说是日志这种信息,这种情况我们可以使用Flume进行解决,我们需要将source端改为exec,它是按照给定指令进行监控,一般监控文件末尾数据就是tail -F /home/file,这里的-F有一定的讲究就是,如果我们采用大F,那么如果采集出现问题,我们的程序会不断进行尝试,而小f不会。
有时候你会发现,还没有对文件进行任何操作,flume控制台会打印一些文件中的数据,其实那不是监听到的,它就是tail -F 命令打印出来的10行信息。
我们为了简单就监听一个普通文件末尾的数据,我们会不断地向file末尾写入新的数据观察flume会不会监听到,为了测试方便,就将输出结果打印到控制台。
接下来进行配置flume信息,我们要监控一个文件末尾产生的数据,那么我们的source端应该采用exec命令式,tail -f指定文件,channel会使用内存进行缓冲,sink就选择的是logger日志。
这里有一点进行说明,其实logger不是控制台,只是将source获得的数据传输的flume/logs/flume.log 日志文件中,为什么会打印到控制台,是因为我们在开启flume的时候,我们添加了一条命令 -Dflume.root.logger=INFO,console这样才会将logger中的数据打印到控制台,开启了该命令后,我们采集的数据就不会进入log文件中了,只是会显示在控制台中,那么存储日志的文件我们可以在conf中的文件中进行配置。
a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = exec a1.sources.r1.command=tail -F /home/hadoop/data/file a1.sinks.k1.type = logger a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
采用上述配置我们就可以实现我们需要的功能了,看一下结果。
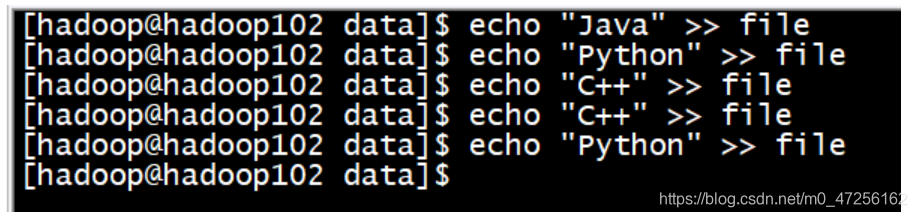
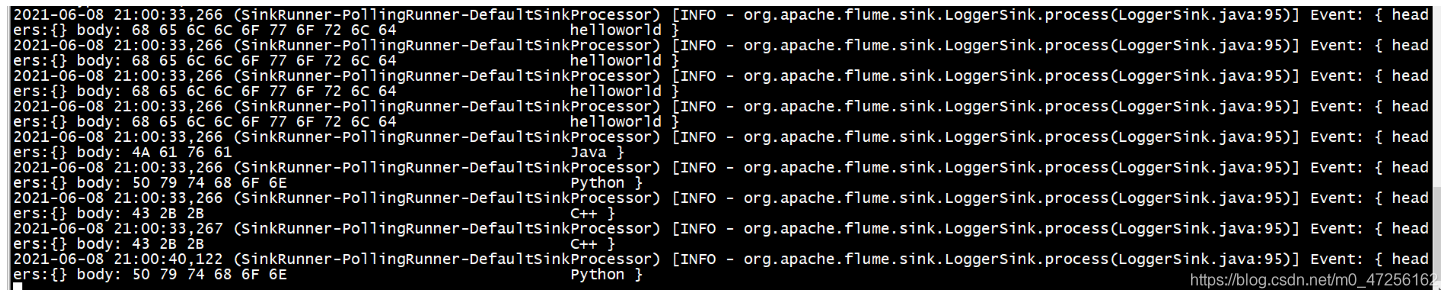
我们使用echo命令不断地向file文件中写入数据,然后再flume端就会监控到我们新添的数据。

